🧑🏻💻용어 정리
Neural Networks
RNN
LSTM
Attention
RNN이 왜 나왔을까요?
오늘은 그 이유에 대해 살펴보도록 합시다.
한 마디로 정리하자면,
Sequential Data를 다루기 위해서 나온 것이 RNN입니다.
text Datas는 보통 sequential Data로 이루어져 있습니다.
이를 더 잘 학습시키기 위한 RNN 기반의 구조가 등장했습니다.
물론 CNN도 local 하게 Convolution을 학습하는 것이 가능하지만, RNN 만큼의 성능이 나오진 않았습니다.
RNN (Recurrent Neural Network)
Sequential Data Modeling
- Sequential Data
- Most of data are sequential
- Speech, Text, image, ...
- Deep Learnings for Sequential Data
- Convolutional Neural Networks (CNN)
- Try to find local features from a sequence
- Recurrent Neural Networks : LSTM, GRU
- Try to capture the feature of the past
- Convolutional Neural Networks (CNN)

위와 같이 NN 구조에서 아래의 추가된 값들이 보이는 것이 있습니다.
이러한 형태를 RNN 형태라고 볼 수 있습니다.
똑같이 input, hidden, output layer 가 NN처럼 존재하지만,
이전 representation이 같이 들어온다는 것이 RNN에서 중요한 개념입니다.
일단 Text의 형태를 보고 갑시다.
Text에서 단어 하나하나가 vector로 이루어져 있습니다.
우리는 이것을 One-Hot vector라고 부릅니다.
맨 처음에 위 hidden layer에 들어온 것이 저장되어 다음 input이 들어올 때도 사용되고, 기존 NN처럼 output 계산할 때도 들어옵니다.
즉, 현재 Input을 계산하는 데 있어, 이전 Input들의 값이 현재의 input에 영향을 준다는 것입니다.
이러한 구조로 영향을 받습니다.
즉, 예시로 보면,
Cat이라는 단어를 연산할 때, 이전 단어는 The가 같이 연산되어 hidden state에 반영됩니다.
그렇다면, 다음 단어 sat이라는 단어는 원래는 hidden state만 계산했지만, 이전 단어까지 배웠던 것을 가지고 연산이 이루어집니다.
이렇게 Recurrent하게 반복되는 구조를 Recurrent Neural Network라고 합니다.
이렇게 이루어져 있는 것인 RNN의 기본적인 툴입니다.
어느정도 이해가 되셨나요?
그럼 다음 그림도 보시죠 !
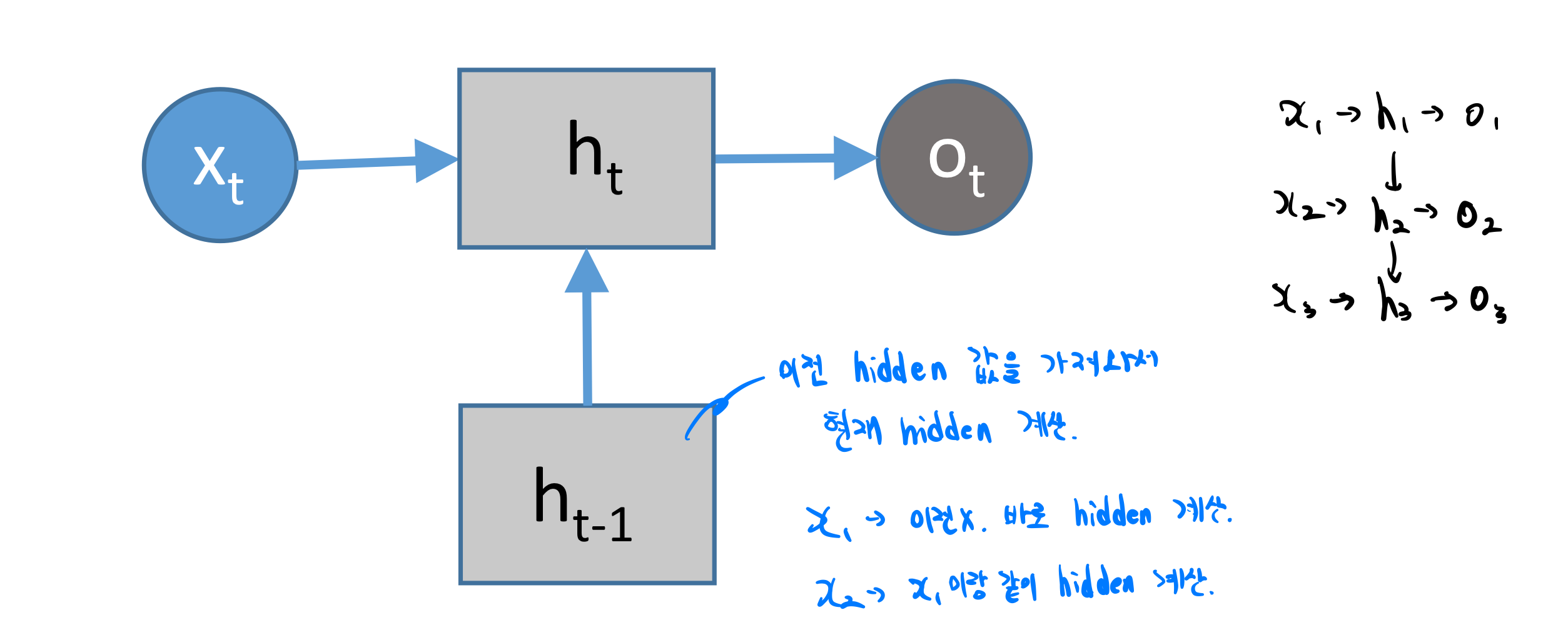
그렇다면 지금까지의 물을 위와 같은 그림 구조로 정리해볼 수 있겠습니다.
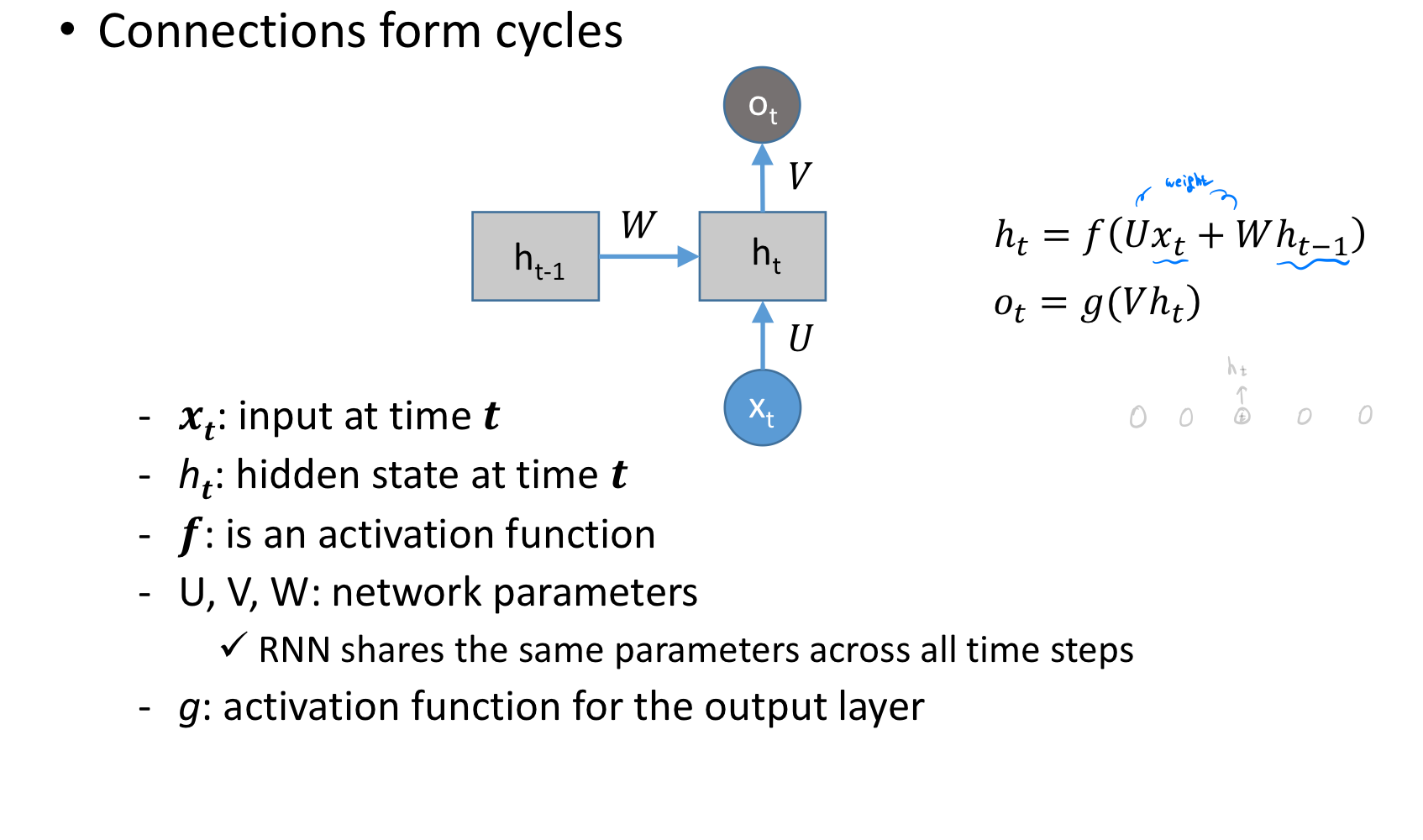
그리고, 수식으로 위와 같이 정리해보겠습니다.
x t는 t에서 input,
x t에서 구한 hidden state 값이 h t 입니다.
이것이 각 weight U, W를 각각 input인 x t에 곱해지고 h t-1에 곱해지며 그것을 더한 값이 activation function f를 통과합니다.
hidden state에서의 값이 위에서 말한 바와 같이 input과 이전까지의 input을 나타내는 h t -1이 weighted sum 되어 hidden state의 값이 됩니다.
그리고 이 값이 다시 weight 곱해져서 또 다른 output actvation function을 지나게 됩니다.
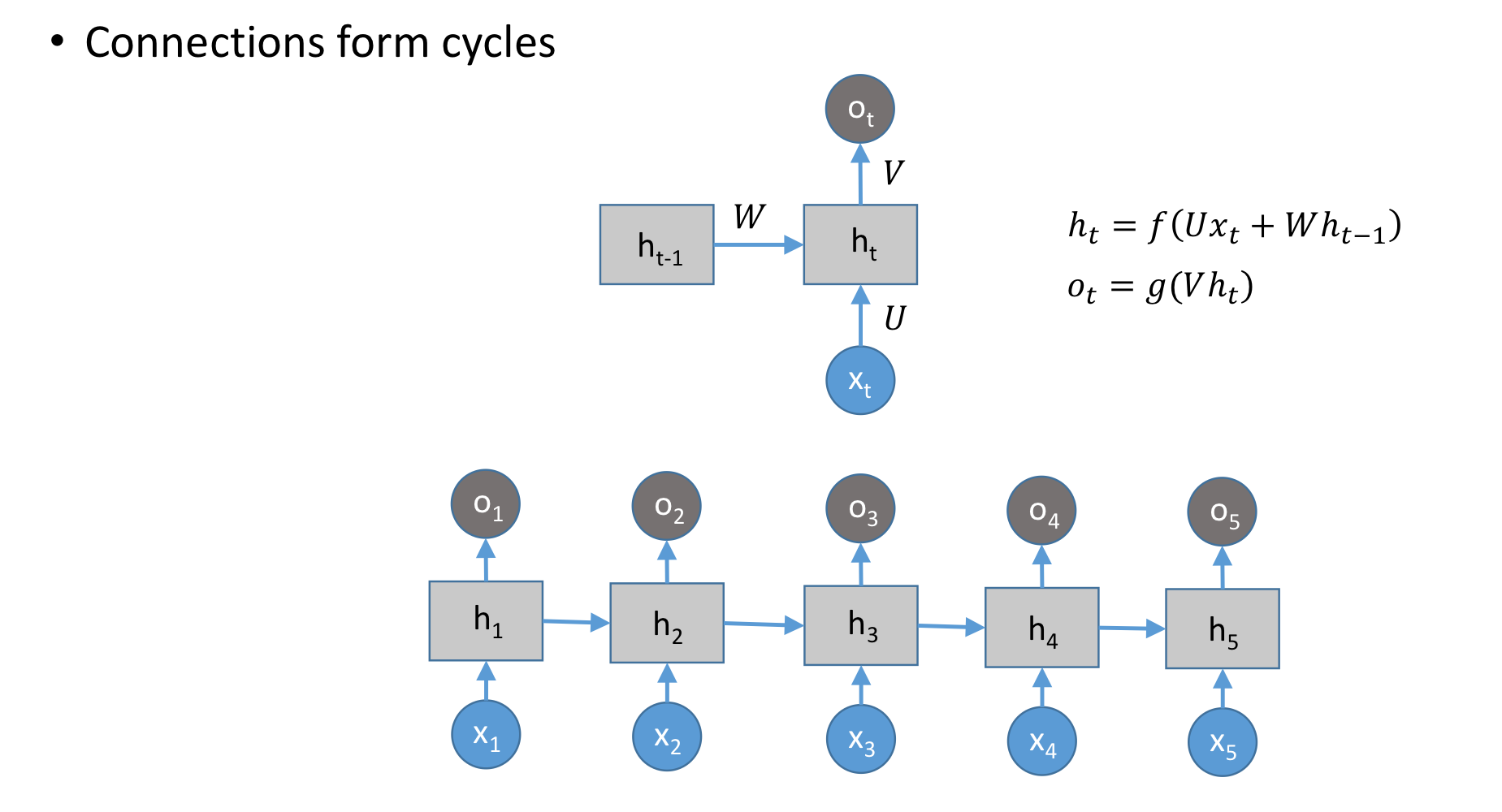
입력은 기존의 NN과 다르게,
Sequence가 존재하므로, sequence의 길이만큼 존재합니다.
그리고 이 각각의 sequence는 One-Hot vector로 이루어져 있어, 총 vecto의 길이가 꽤 크게 100000의 길이가 될 수가 있습니다.
위 구조와 같이 input이 여러 차원 존재하고, output도 여러 차원 존재하는 것을 "Many-to-Many"라고 합니다.
구조에 해당하는 것은 내가 하고자하는 것에 따라 RNN구조를 설정하면 됩니다.
위 그림에서 h3는 x1 ~ x3의 Input이 반영된 hidden state입니다.
그리고 마지막 hidden state인 h5를 sequence의 embedding이라 하며,
이것은 sentence embedding이라 합니다.
여기서 input을 더 살펴봅시다.
The [ 1 0 0 0 0 ]
The 라는 단어를 위와 같이 나타낸다면,
이를 Word2vec이나 GloVe를 사용하여 다르게 나타낼 수도 있습니다.
이 다르게 나타낸 것을 특정 context에 대한 Vector 값이라고 합니다.
그리고 이것을 Pre-trained embedding이라고 볼 수 있습니다.
이것들을 input으로 넣으면 더 유의미한 embedding으로 사용 가능합니다.
Long Term Dependency
h t는 x 1 ~ x t-1까지의 정보가 모두 encoding된 정보입니다.
RNN은 이러한 recurrent 구조로 하나하나씩 연결되는 구조로 학습되었기 때문에, Long Term Dependency를 가집니다.
이 Sequence 길이가 엄청나게 길다면, 이것이 유지될까요?
RNN은 sequence 정보를 학습하고자 하는데,
뒤로 갈수록 앞에 학습한 것들을 잘 잊어버리는 "Long Term Dependency" 문제가 존재합니다.
LSTM과 GRU가 나왔습니다.
'Artificial Intelligence > Natural Language Processing' 카테고리의 다른 글
| [NLP] Sequential Data Modeling (0) | 2023.04.10 |
|---|---|
| [NLP] RNN - LSTM, GRU (0) | 2023.04.04 |
| [NLP] Word Embedding - GloVe [practice] (0) | 2023.03.31 |
| [NLP] Word Embedding - GloVe (0) | 2023.03.31 |
| [NLP] Word Embedding - CBOW and Skip-Gram (2) | 2023.03.27 |