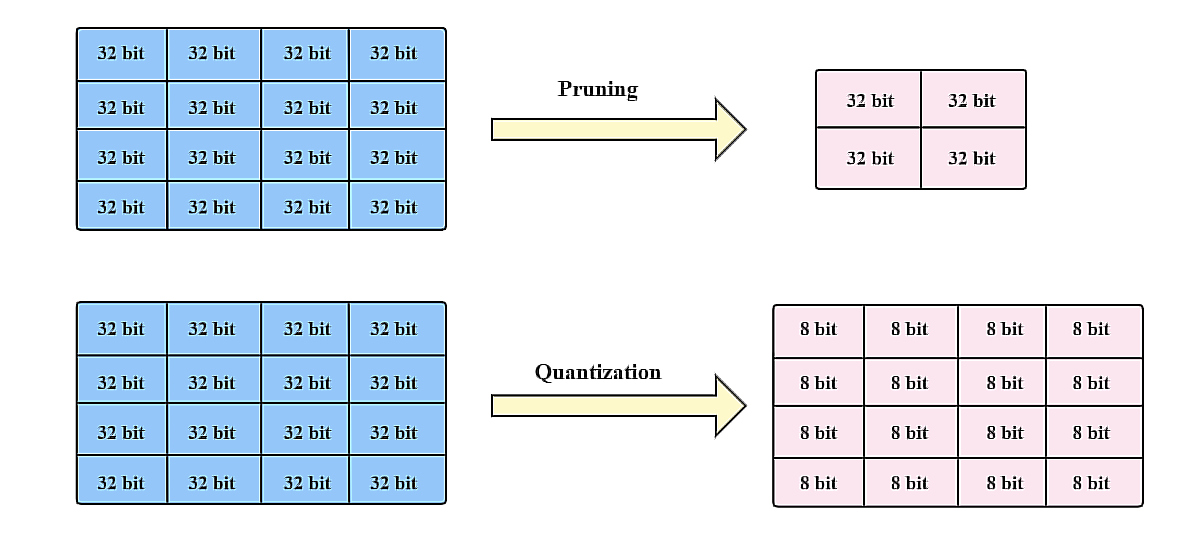
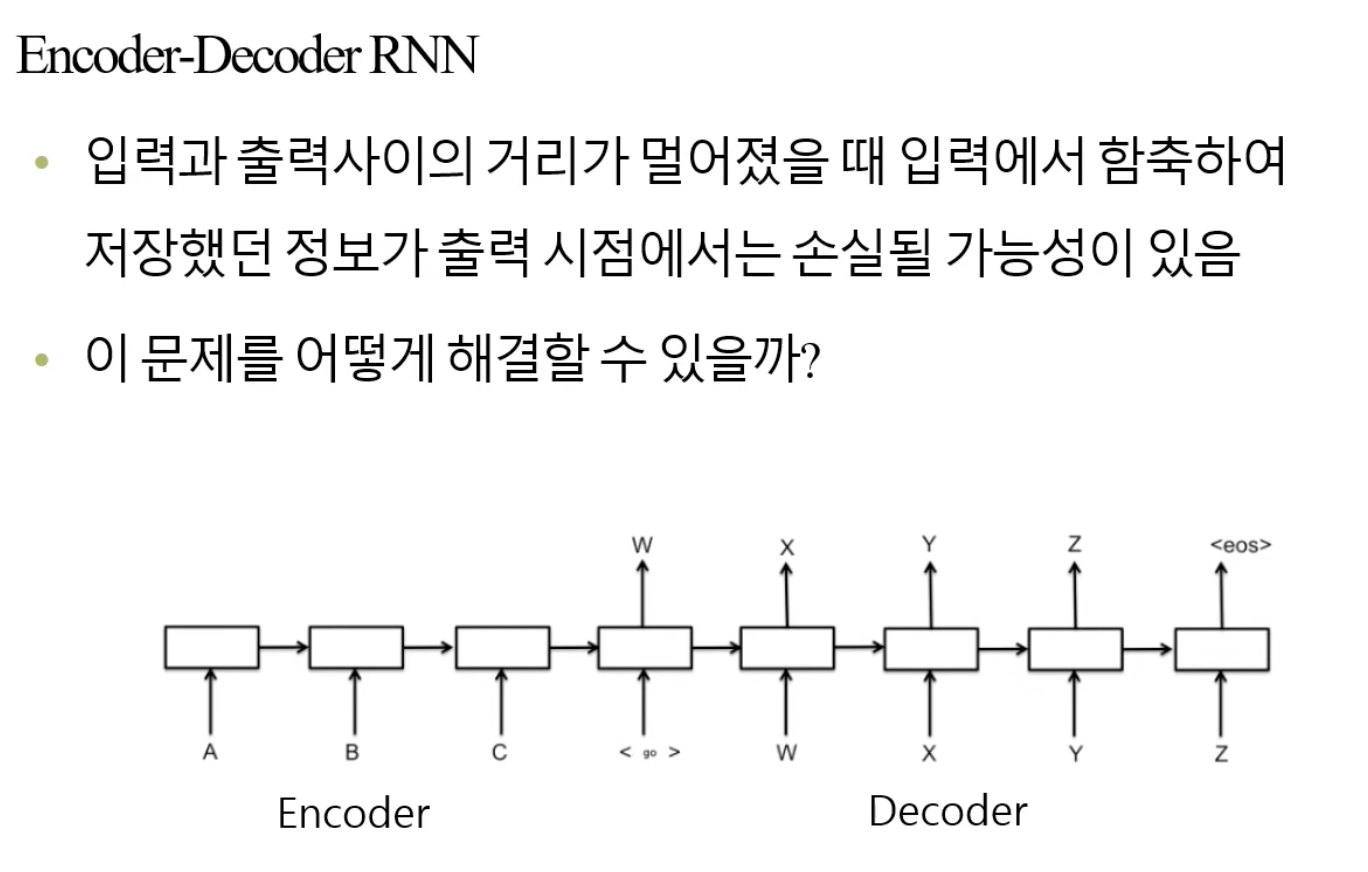
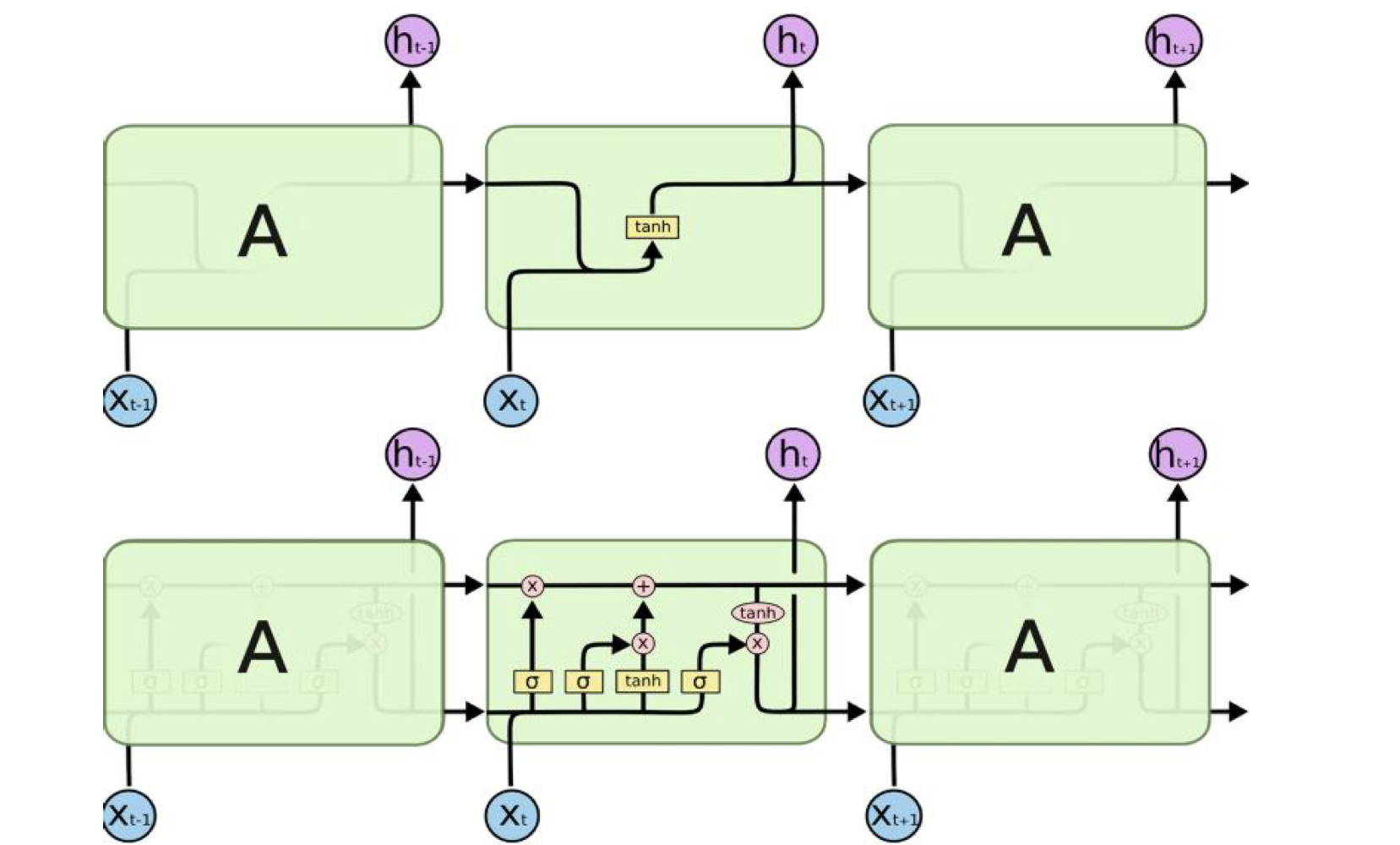
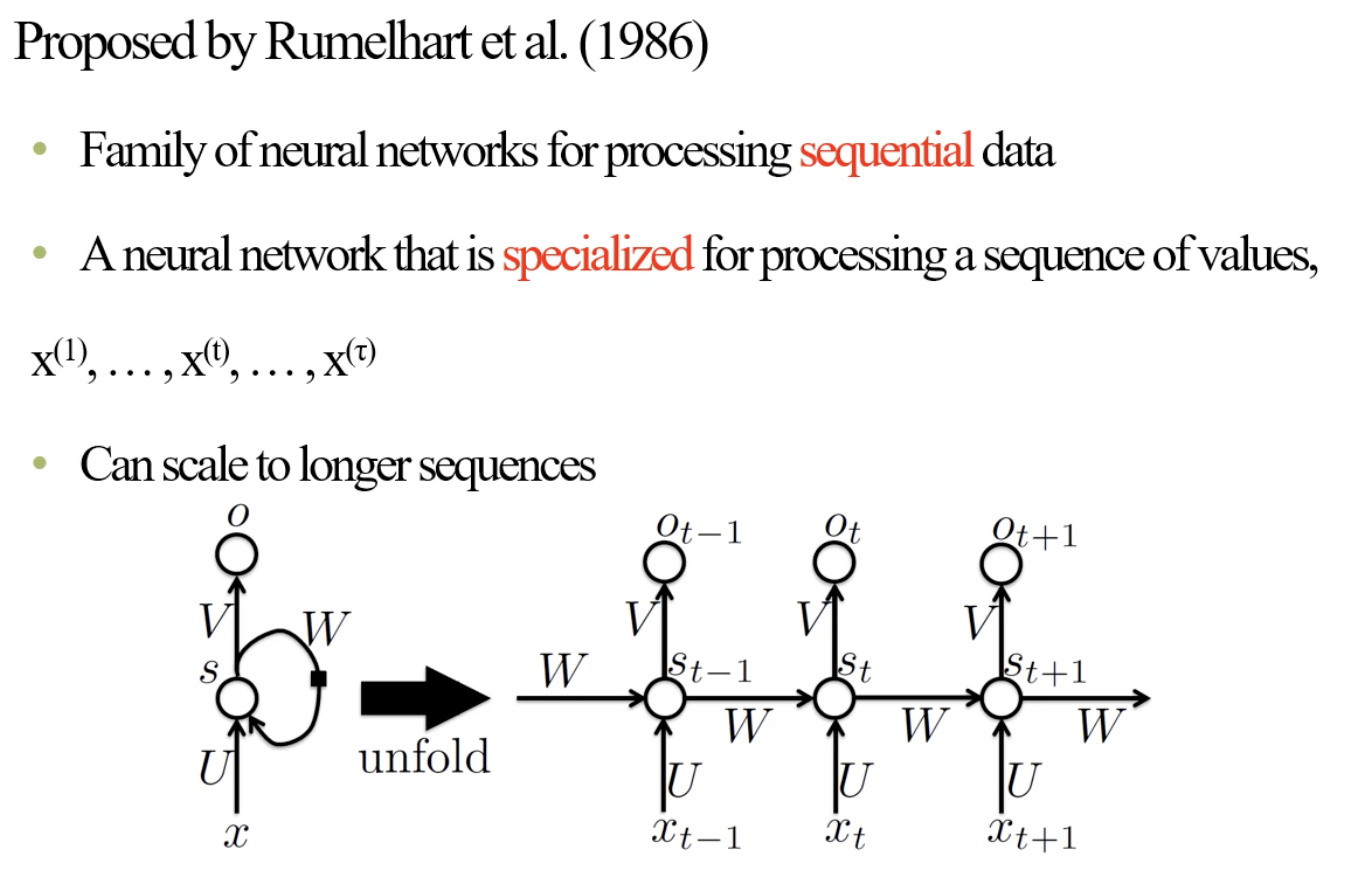
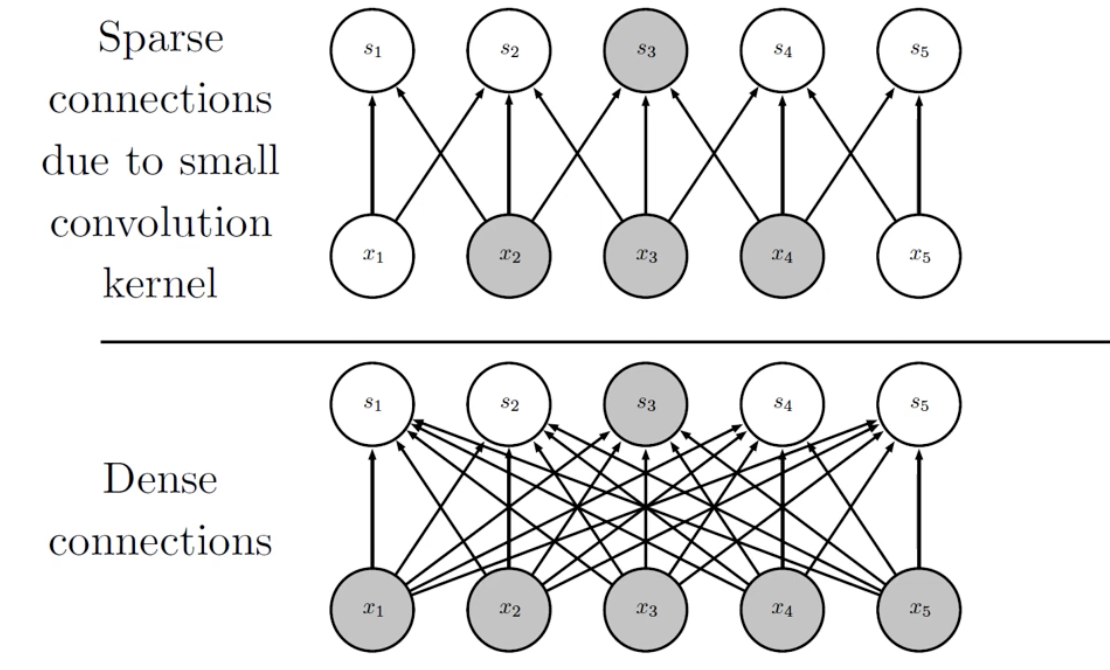
🧑🏻💻용어 정리 Computer vision Quantization Pruning Quantization & Pruning 이 Quantization이 왜 필요할까요? 결국 나오게 된 이유는, computation과 memory를 조금만 사용하면서 비슷한 accuracy를 내고싶다는 것입니다. 이것이 가장 큰 욕망이죠. 한편, CNN이 MLP 보다 우수한 이유는, MLP는 edge 개수만큼의 parameter의 개수가 요구되지만, CNN은 일부의 parameter sharing 등의 성질로 인하여 memory를 조금 사용합니다. 그리고 spare connection을 통해 조금의 weighted summation을 한다는 것입니다. 있습니다. 따라서, 이러한 기법을 사용할 때는 항상 세심한 주의를 기울..