🧑🏻💻 주요 정리
NLP
Word Embedding
CBOW
Represent the meaning of word
- Two basic neural network models:
- Continuous Bag of Word(CBOW) : use a window of word to predict the middle word.
- Skip-gram (SG) : use a word to predict the surrounbding ones in window.

위와 같은 차이를 보입니다.
하나씩 살펴봅시다.
# see http://pytorch.org/tutorials/beginner/nlp/word_embeddings_tutorial.html
import torch
from torch.autograd import Variable
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
torch.manual_seed(1)
먼저, 위와 같이 필요한 library를 import 합니다.
CONTEXT_SIZE = 2 # 2 words to the left, 2 to the right # 앞에 몇 단어를 볼 것인가. 총 4개의 단어를 봄.
text = """We are about to study the idea of a computational process.
Computational processes are abstract beings that inhabit computers.
As they evolve, processes manipulate other abstract things called data.
The evolution of a process is directed by a pattern of rules
called a program. People create programs to direct processes. In effect,
we conjure the spirits of the computer with our spells.""".split() # 데이터
split_ind = (int)(len(text) * 0.8)
# By deriving a set from `raw_text`, we deduplicate the array
'''
첫 번째 작업. vocavluary를 만듦. (0, 0, 0, 0, 0, 0, 0) 단어를 몇 번째 index만 1로 바꾸는 One-hot encoding을 사용.
we = (1, 0, 0, 0, 0, 0, 0)
are = (0, 1, 0, 0, 0, 0, 0)
about = (0, 0, 1, 0, 0, 0, 0)
to = (0, 0, 0, 1, 0, 0, 0)
이렇게 저장하는 것은 힘듦.
'''
# text를 그냥 split하면 모든 것이 다 나옴.
vocab = set(text) # set을 사용해서 vocalvulary로 만듦.
vocab_size = len(vocab)
print('vocab_size:', vocab_size)
# 앞에서부터 하나씩 배정
w2i = {w: i for i, w in enumerate(vocab)}
i2w = {i: w for i, w in enumerate(vocab)}
# 자연어에서 가장 먼저하는 것이 이러한 vocalvulary를 만드는 것이다.
print(w2i)
print(i2w)
위 식을 조금씩 살펴보겠습니다.
먼저, CONTEXT_SIZE = 2를 살펴보면, 앞 뒤로 2단어씩을 살펴볼 수 있는 것입니다.
이는 우리가 앞 뒤의 두 단어 씩을 보고, 가운데 단어를 학습시켜서 예측시킬 수 있습니다.
그리고, 데이터를 text에 담아서 split으로 분리하여 단어 하나하나씩을 담아둡니다.
- 첫 번째 작업. vocavluary를 만드는 것입니다.
그런데,
(0, 0, 0, 0, 0, 0, 0) 단어를 몇 번째 index만 1로 바꾸는 One-hot encoding을 사용합니다.
we = (1, 0, 0, 0, 0, 0, 0)
are = (0, 1, 0, 0, 0, 0, 0)
about = (0, 0, 1, 0, 0, 0, 0)
to = (0, 0, 0, 1, 0, 0, 0)
이렇게 저장하는 것은 힘듭니다.
수많은 단어를 One-hot encoding을 하는 것은 상당히 많은 vectors가 필요합니다.
그러한 한계가 있습니다.
그래서 숫자로 하나씩 매칭시켜주었습니다.
그리고,
vocab에 해당 text를 set으로 받아서 vocabulary를 만듭니다.
그래서 아래와 같은 Output을 뽑을 수 있습니다.
vocab_size: 49
{'computers.': 0, 'other': 1, 'directed': 2, 'that': 3, 'data.': 4, 'processes.': 5, 'evolution': 6, 'pattern': 7, 'called': 8, 'programs': 9, 'effect,': 10, 'beings': 11, 'process': 12, 'We': 13, 'a': 14, 'our': 15, 'manipulate': 16, 'inhabit': 17, 'rules': 18, 'the': 19, 'The': 20, 'is': 21, 'program.': 22, 'direct': 23, 'In': 24, 'study': 25, 'computer': 26, 'with': 27, 'As': 28, 'spirits': 29, 'they': 30, 'People': 31, 'conjure': 32, 'spells.': 33, 'abstract': 34, 'are': 35, 'to': 36, 'of': 37, 'about': 38, 'things': 39, 'we': 40, 'create': 41, 'Computational': 42, 'evolve,': 43, 'by': 44, 'computational': 45, 'process.': 46, 'processes': 47, 'idea': 48}
{0: 'computers.', 1: 'other', 2: 'directed', 3: 'that', 4: 'data.', 5: 'processes.', 6: 'evolution', 7: 'pattern', 8: 'called', 9: 'programs', 10: 'effect,', 11: 'beings', 12: 'process', 13: 'We', 14: 'a', 15: 'our', 16: 'manipulate', 17: 'inhabit', 18: 'rules', 19: 'the', 20: 'The', 21: 'is', 22: 'program.', 23: 'direct', 24: 'In', 25: 'study', 26: 'computer', 27: 'with', 28: 'As', 29: 'spirits', 30: 'they', 31: 'People', 32: 'conjure', 33: 'spells.', 34: 'abstract', 35: 'are', 36: 'to', 37: 'of', 38: 'about', 39: 'things', 40: 'we', 41: 'create', 42: 'Computational', 43: 'evolve,', 44: 'by', 45: 'computational', 46: 'process.', 47: 'processes', 48: 'idea'}
자 지금까지 vocabulary를 만들었습니다.
그렇다면 다음과 같은 dataset을 만들 수 있습니다.
CBOW는 input은 t - 2, t - 1, t + 1, t + 2를 그리고 Output으로 t를 내놓는 형식입니다.
아래와 같이 create_cbow_dataset 함수에서 text를 입력으로 받습니다.
그리고 data는 0번째 인덱스와 1번째 인덱스는 앞에 두 개의 text가 없으므로 해당 경우는 제외합니다.
나머지는 context, 현재 t 인덱스의 값을 target으로 지정해서 context와 data의 pair로 이루어진 data를 만들겠습니다.
# context window size is two
# input : t-2, t-1, t+1, t+2
# Output : t
# 각 단어가 들어오면 목적으로 하는 Output의 값을 정하면 양쪽 2개씩의 값이 필요.
def create_cbow_dataset(text):
data = []
for i in range(2, len(text) - 2): # 0번째는는 앞에에 두두 개개 없음음.
context = [text[i - 2], text[i - 1],
text[i + 1], text[i + 2]]
target = text[i] # 나머지는 context, 현재 t번째를 target으로 지정해서 데이터를 만들겠다.
data.append((context, target))
return data
'''
우리는 input은 현재 단어, Output은 4개.
보통 4개의 output으로 하지는 않고,
t - > t-2
t - > t-1
t - > t + 1
t - > t + 2
입력 값에 대한 context를 학습.
'''
# input : t
# Output : t-2, t-1, t+1, t+2
def create_skipgram_dataset(text):
import random
data = []
for i in range(2, len(text) - 2):
data.append((text[i], text[i-2], 1))
data.append((text[i], text[i-1], 1))
data.append((text[i], text[i+1], 1))
data.append((text[i], text[i+2], 1))
# negative sampling
for _ in range(4):
if random.random() < 0.5 or i >= len(text) - 3:
rand_id = random.randint(0, i-1)
else:
rand_id = random.randint(i+3, len(text)-1)
data.append((text[i], text[rand_id], 0))
return data
cbow_train = create_cbow_dataset(text)
skipgram_train = create_skipgram_dataset(text)
print('cbow sample', cbow_train[0])
print('skipgram sample', skipgram_train[0])
# 데이터 만드는 것까지 함.
그리고 위와 같이 create_skipgram_dataset 함수를 구현하여, text를 input으로 받습니다.
그리고, 위 for문에서도 첫번째와 두 번째 인덱스는 값이 좌우 2가지 숫자가 존재하지 않으므로, 위와 같이 꾸려집니다.
input text i번째 text에 대해 t - 2, t - 1, t + 1, t + 2을 output으로 합니다.
그리고 negative sampling을 사용하여 rand_id를 인덱스로 사용하여 랜덤으로 배치합니다.
그리고 cbow_train, skipgram_train에 해당 학습용 데이터들을 넣습니다.
여기까지 데이터를 만드는 것까지 해봤습니다.
cbow sample (['We', 'are', 'to', 'study'], 'about')
skipgram sample ('about', 'We', 1)위 코드의 출력입니다.
그럼 아래와 같이 CBOW와 SkipGram model을 살펴봅시다,
아래와 같이
class CBOW(nn.Module):
def __init__(self, vocab_size, embd_size, context_size, hidden_size):
super(CBOW, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
self.linear1 = nn.Linear(2*context_size*embd_size, hidden_size) # input이이 4개개 에에 대해해 hidden layer 지났다가가 감감.
self.linear2 = nn.Linear(hidden_size, vocab_size) # (0, 0, 0, 0, 0, 1, 0, 0) # 6번째째 인덱스를를 갖는는 단어다다.
def forward(self, inputs):
embedded = self.embeddings(inputs).view((1, -1))
hid = F.relu(self.linear1(embedded))
out = self.linear2(hid)
log_probs = F.log_softmax(out)
return log_probs
class SkipGram(nn.Module):
def __init__(self, vocab_size, embd_size):
super(SkipGram, self).__init__()
self.embeddings = nn.Embedding(vocab_size, embd_size)
def forward(self, focus, context):
embed_focus = self.embeddings(focus).view((1, -1))
embed_ctx = self.embeddings(context).view((1, -1))
score = torch.mm(embed_focus, torch.t(embed_ctx))
log_probs = F.logsigmoid(score)
return log_probs
위 코드에서 input과 vector, 그리고 embedding에 대하여 살펴볼 수 있습니다.
해당 함수들에 대한 input 값을 잘 살펴보시길 바랍니다.
그리고, 해당 모델에 대한 training 코드를 다음과 같이 볼 수 있습니다.
embd_size = 100
learning_rate = 0.001
n_epoch = 30
def train_cbow():
hidden_size = 64
losses = []
loss_fn = nn.NLLLoss()
model = CBOW(vocab_size, embd_size, CONTEXT_SIZE, hidden_size)
print(model)
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(n_epoch):
total_loss = .0
for context, target in cbow_train:
ctx_idxs = [w2i[w] for w in context]
ctx_var = Variable(torch.LongTensor(ctx_idxs))
model.zero_grad()
log_probs = model(ctx_var)
loss = loss_fn(log_probs, Variable(torch.LongTensor([w2i[target]])))
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
return model, losses
def train_skipgram():
losses = []
loss_fn = nn.MSELoss()
model = SkipGram(vocab_size, embd_size)
print(model)
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(n_epoch):
total_loss = .0
for in_w, out_w, target in skipgram_train:
in_w_var = Variable(torch.LongTensor([w2i[in_w]]))
out_w_var = Variable(torch.LongTensor([w2i[out_w]]))
model.zero_grad()
log_probs = model(in_w_var, out_w_var)
loss = loss_fn(log_probs[0], Variable(torch.Tensor([target])))
loss.backward()
optimizer.step()
total_loss += loss.item()
losses.append(total_loss)
return model, losses
cbow_model, cbow_losses = train_cbow()
sg_model, sg_losses = train_skipgram()
위 train 과정에 대해서는 기본적으로 loss, model call, optimization, epoch 반복으로 이루어져 있습니다.
자세한 내용은 생략하겠습니다.
출력은 다음과 같습니다.
BOW(
(embeddings): Embedding(49, 100)
(linear1): Linear(in_features=400, out_features=64, bias=True)
(linear2): Linear(in_features=64, out_features=49, bias=True)
)
<ipython-input-5-49cae8ab3769>:12: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument.
log_probs = F.log_softmax(out)
SkipGram(
(embeddings): Embedding(49, 100)
)
그리고,
test 부분입니다.
# test
# You have to use other dataset for test, but in this case I use training data because this dataset is too small
def test_cbow(test_data, model):
print('====Test CBOW===')
correct_ct = 0
for ctx, target in test_data:
ctx_idxs = [w2i[w] for w in ctx]
ctx_var = Variable(torch.LongTensor(ctx_idxs))
model.zero_grad()
log_probs = model(ctx_var)
_, predicted = torch.max(log_probs.data, 1)
predicted_word = i2w[predicted.item()] # predicted는 tensor임. 이것을을 어떠한한 값으로로 바꿔야함함. 그것이이 Item.
print('predicted:', predicted_word)
print('label :', target)
if predicted_word == target:
correct_ct += 1
print('Accuracy: {:.1f}% ({:d}/{:d})'.format(correct_ct/len(test_data)*100, correct_ct, len(test_data)))
def test_skipgram(test_data, model):
print('====Test SkipGram===')
correct_ct = 0
for in_w, out_w, target in test_data:
in_w_var = Variable(torch.LongTensor([w2i[in_w]]))
out_w_var = Variable(torch.LongTensor([w2i[out_w]]))
model.zero_grad()
log_probs = model(in_w_var, out_w_var)
_, predicted = torch.max(log_probs.data, 1)
predicted = predicted[0]
if predicted == target:
correct_ct += 1
print('Accuracy: {:.1f}% ({:d}/{:d})'.format(correct_ct/len(test_data)*100, correct_ct, len(test_data)))
test_cbow(cbow_train, cbow_model)
print('------')
test_skipgram(skipgram_train, sg_model)
위는 training과 같은 데이터셋을 사용한 것입니다.
데이터의 크기가 작기 때문에 결과가 아닌 코드 그 자체를 보고 공부해주세요.
출력 결과의 일부만 첨부하겠습니다.
====Test CBOW===
predicted: about
label : about
predicted: to
label : to
predicted: study
label : study
predicted: the
label : the
predicted: idea
label : idea
predicted: of
label : of
predicted: a
label : a
:
:
:
predicted: with
label : with
Accuracy: 100.0% (58/58)
------
====Test SkipGram===
Accuracy: 50.0% (232/464)
<ipython-input-5-49cae8ab3769>:12: UserWarning: Implicit dimension choice for log_softmax has been deprecated. Change the call to include dim=X as an argument.
log_probs = F.log_softmax(out)
자, 결과를 살펴보겠습니다.
위 결과에서 CBOW는 정확도가 100프로가 나왔습니다.
그러나, SkipGram은 정확도가 50프로입니다.
두 경우 모두 training set과 test set이 같은 경우인데 왜 그럴까요?
SkipGram은 잘 못 맞추는 이유.
data에 대해 cbow는 입력 4개에 대해 output 1개, skipgram은 정확도가 더 낮을까?
-> 두 개의 데이터를 만든 형식이, cbow는 입력 4개에 대해 1개를 맞추는 것.
-> skipgram은 특정 단에 대한 4개의 단어를 학습했음.
t가 들어와도 t -2, t-1, t+1, t+2가 대상이므로 정확도가 떨어진다.
정확도가 낮다고 안 좋은 모델이 아니다. 단어를 맞추는 게 목적이 아니다. Weight를 사용하는 게 목적이다. 일반적으로 skipgram이이 더 성능이 좋다. cbow는 4개를 받고 하나에 대해 학습하며, 굉장히 specific한 경우에 대해서 학습하게 되는 것이다.
그렇기 때문에 SkipGram이 더 일반적으로 잘 성능이 좋다고 볼 수 있습니다.
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def showPlot(points, title):
plt.figure()
fig, ax = plt.subplots()
plt.plot(points)
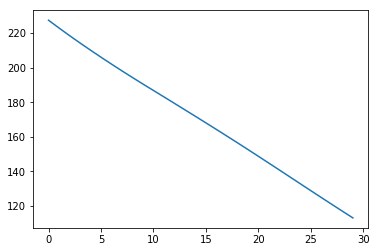
showPlot(cbow_losses, 'CBOW Losses')
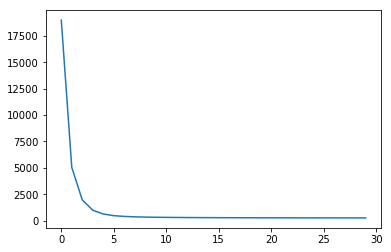
showPlot(sg_losses, 'SkipGram Losses') # loss 학습 차이를 볼 수 있다.
위와 같이 loss를 통해 학습 차이를 살펴볼 수 있습니다.
<matplotlib.figure.Figure at 0x7fe1a5910f28>CBOW
<matplotlib.figure.Figure at 0x7fe1ac39f2e8>SkipGram
'Artificial Intelligence > Natural Language Processing' 카테고리의 다른 글
| [NLP] Word Embedding - GloVe [practice] (0) | 2023.03.31 |
|---|---|
| [NLP] Word Embedding - GloVe (0) | 2023.03.31 |
| [NLP] Word Embedding - Word2Vec (0) | 2023.03.27 |
| [NLP] Word Embedding - Skip Gram (0) | 2023.03.27 |
| [NLP] Word Embedding - CBOW (1) | 2023.03.27 |