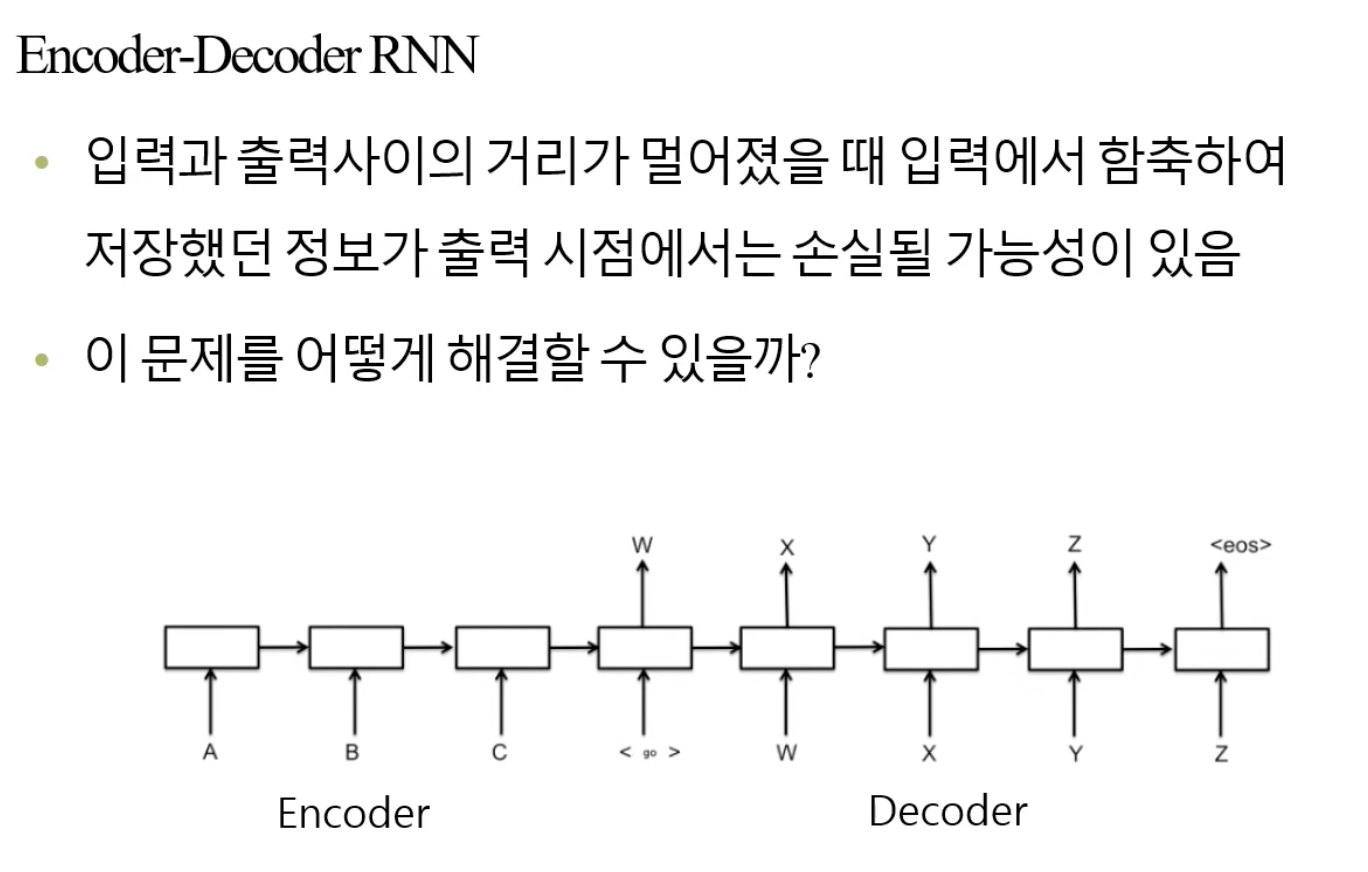
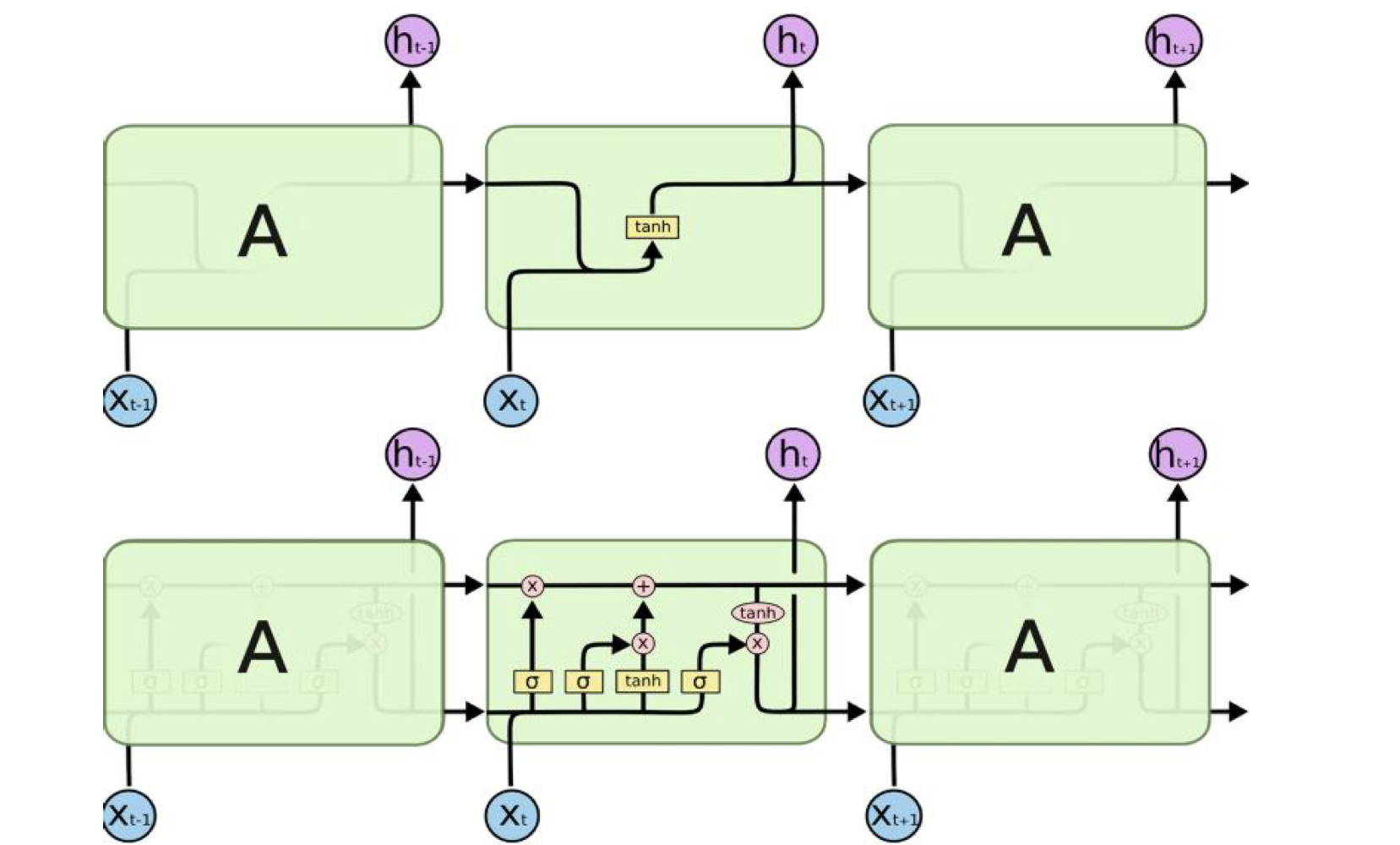
🧑🏻💻용어 정리 Neural Networks RNN LSTM Attention Transformer Generator discriminator self-attention layer normalization multi-head attention positional encoding https://arxiv.org/abs/1706.03762 Attention Is All You Need The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect..