🧑🏻💻용어 정리
Neural Networks
RNN
LSTM
Attention
CNN
Sequential Data Modeling
- Sequential Data
- Most of data are sequential
- Speech, Text, Image, ...
- Deep Learnings for Sequential Data
- Convolutional Neural Networks (CNN)
- Try to find local features from a sequence
- Recurrent Neural Networks : LSTM, GRU
- Try to capture the feature of the past
- Convolutional Neural Networks (CNN)
지금까지 입력에 대해 살펴보았죠.
그런데, 그 입력에 대해서 다 output이 존재합니다.
우리는 그 output을 우리가 원하는대로 사용할 수도 있습니다.
그래서 아래와 같은 Task에 사용될 수 있습니다.

그래서 아래와 같은 Sequence Generation의 task도 우리가 풀어볼 수 있습니다.
Sequence가 나오면 Sequence를 뱉는 형식입니다.
우리는 다음과 같은 종류의 Task로 구분할 수 있습니다.
- One to Many
- Image Captioning
- Image -> Sequence of words
- caption model
- Many to One
- Sentiment Classification
- sentence -> sentiment
- classification 모델
- encoder에서 많이, 주어진 것으로 output을 만든다.
- input은 이미 아는 값.
- Many to Many
- Machine Translation
- sentence -> sentence
- 번역 모델
- decoder는 예측한 것을 매 time 마다 새로운 것을 가지고 넣어서 자시 써야하는 것임.
- synched Many to Many
- Stock Price Prediction
- Prediction of next word
- language model
- 바로 바로 다음 문장 예측하는 language model
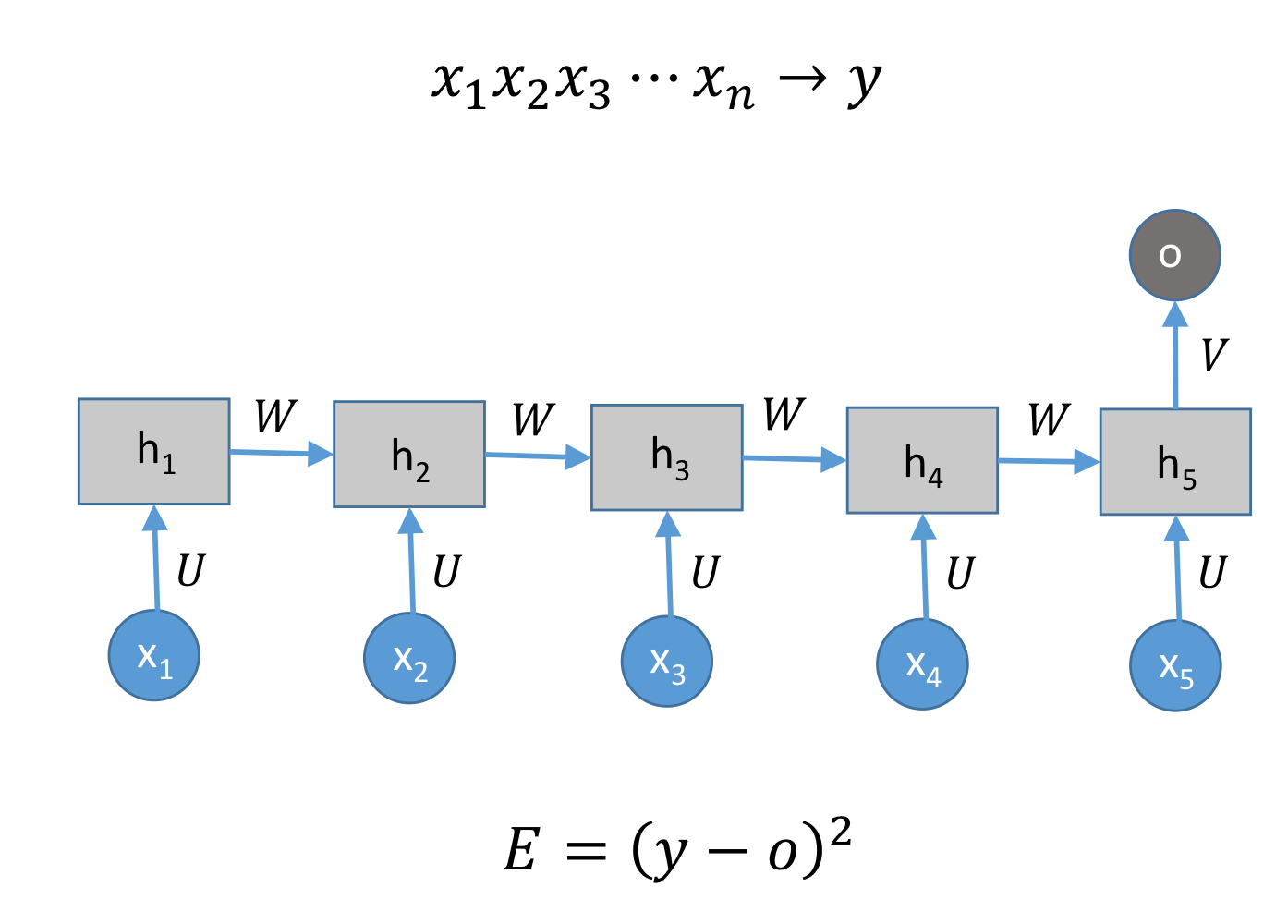
다음과 같은 모델이 있다고 봅시다.
다음은 어떤 모델일까요?
Many to Many 입니다.
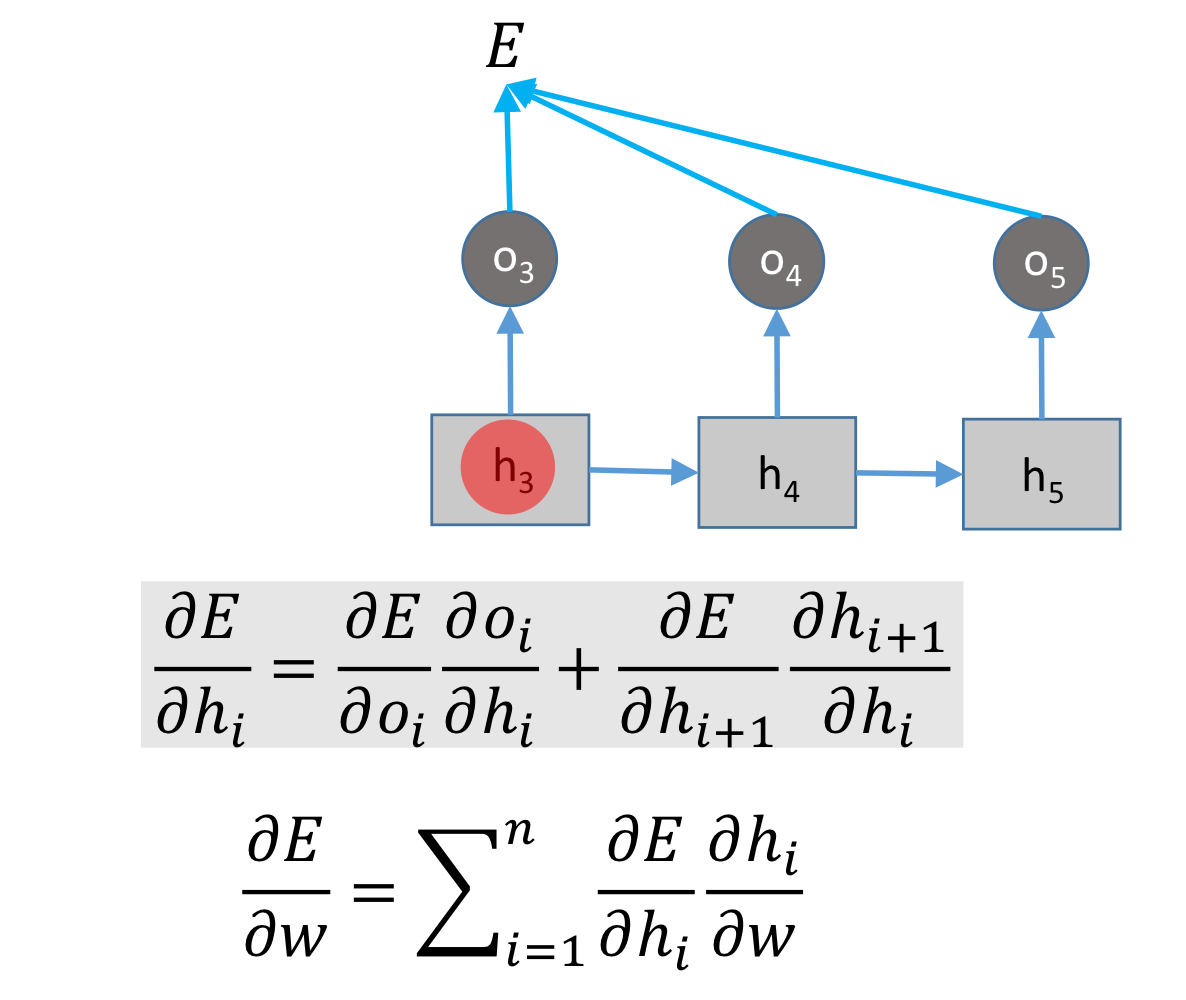
그리고 우리는 정답을 알고 있으니, 예측값과 실제값 사이의 MSE를 사용합니다.
그리고, 각각에 대해 MSE를 적용합니다.
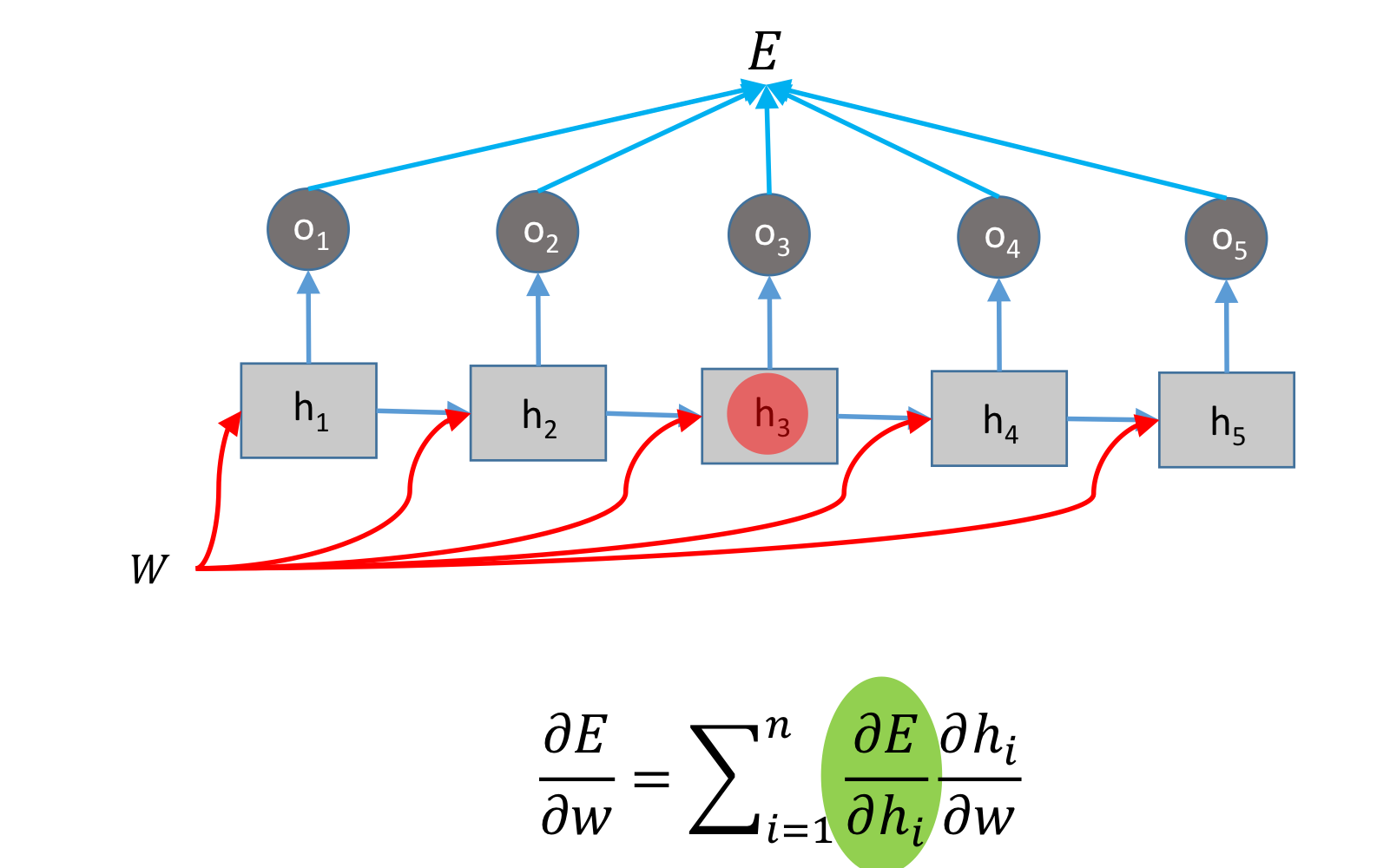
그렇다면 Test할 때는 어떻게 할까요?
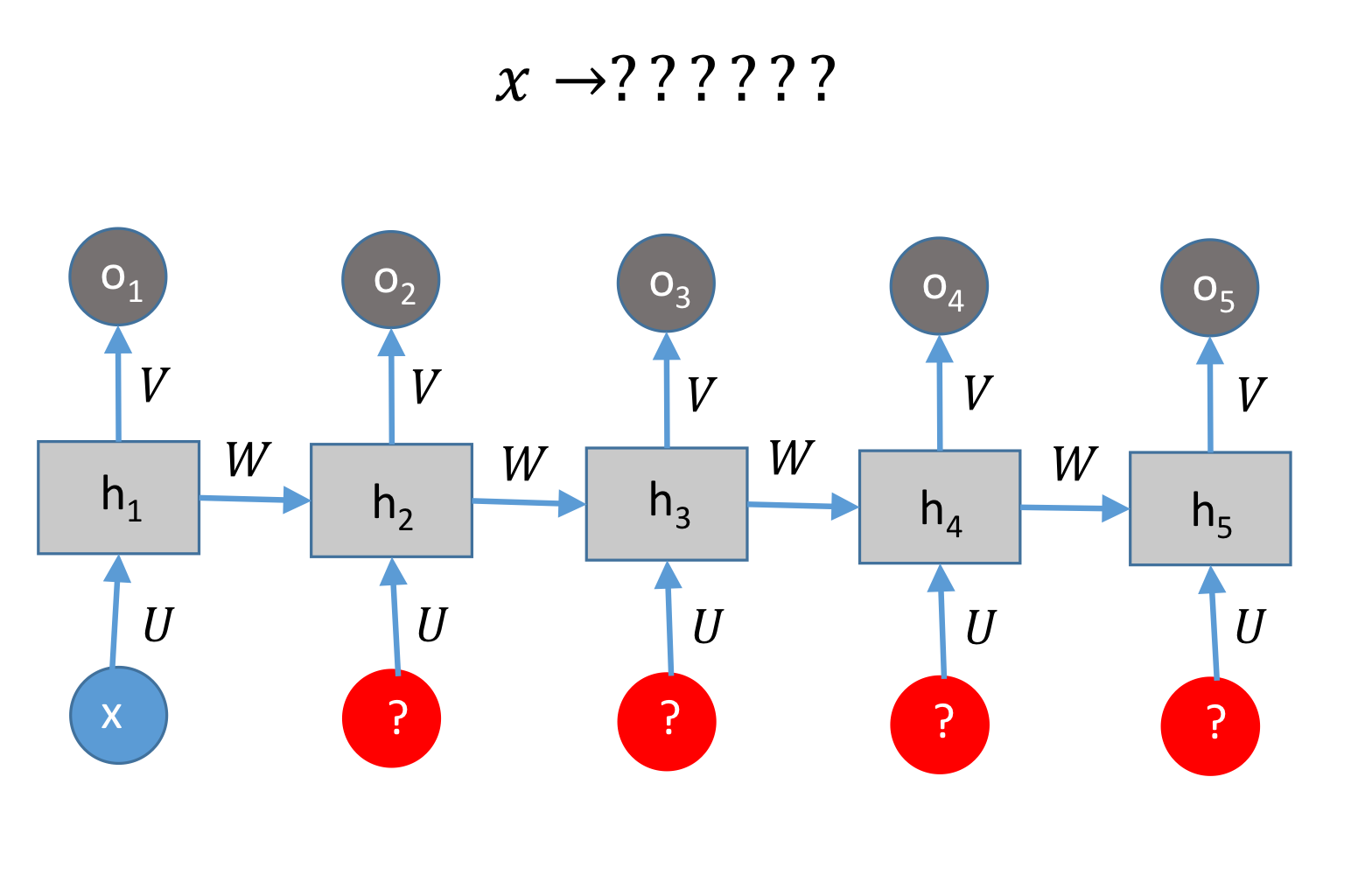
training은 입력 뒤에 뭐가 오는지 알지만, Test는 알지 못합니다.
계속해서 예측하여 입력으로 다시 넣고, 예측하여 넣고를 반복합니다.
그래서 Training과 Test는 구조가 다르다는 것을 알 수 있습니다.
Many to One
classification에선 어떨까요?
긍정/부정을 위와 같이 마지막에서 예측하도록 합니다.
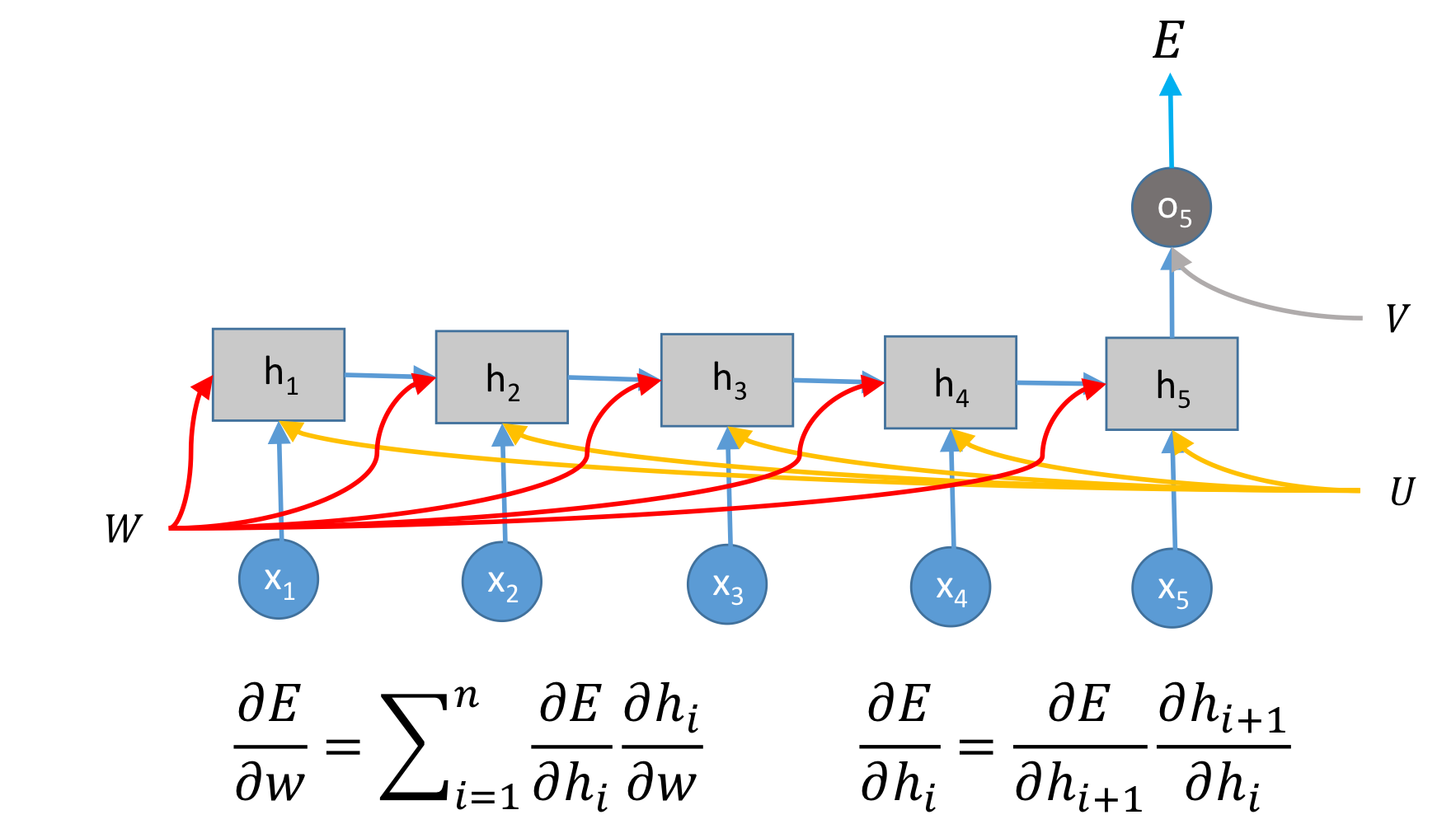
그리고,
Many to Many
번역 모델은 모든 입력을 알고 있습니다.
그렇다면, 몇 개의 단어를 넣고, 그것에 대한 output이 나오도록 학습합니다.
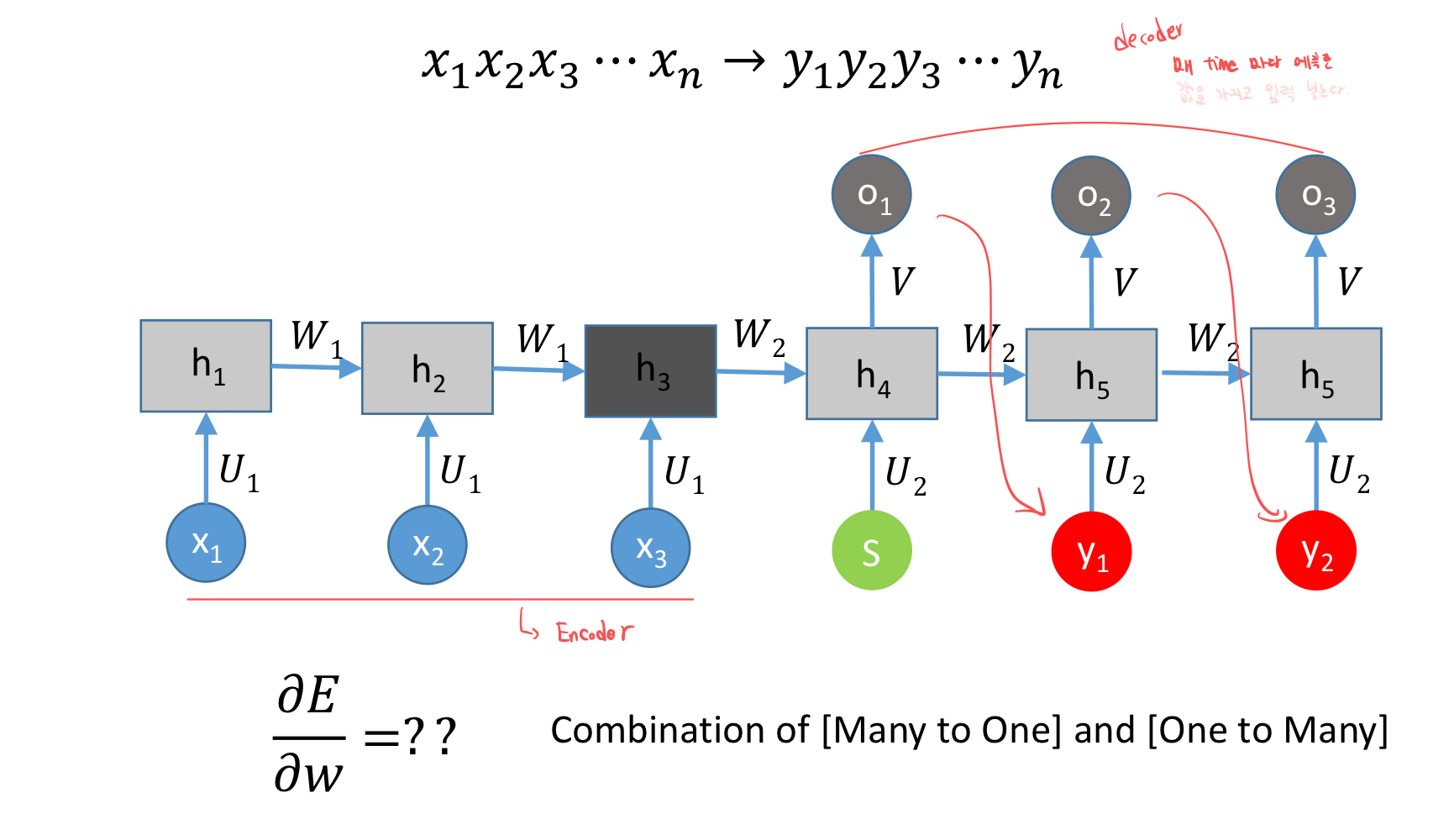
다시 하나씩 살펴봅니다.
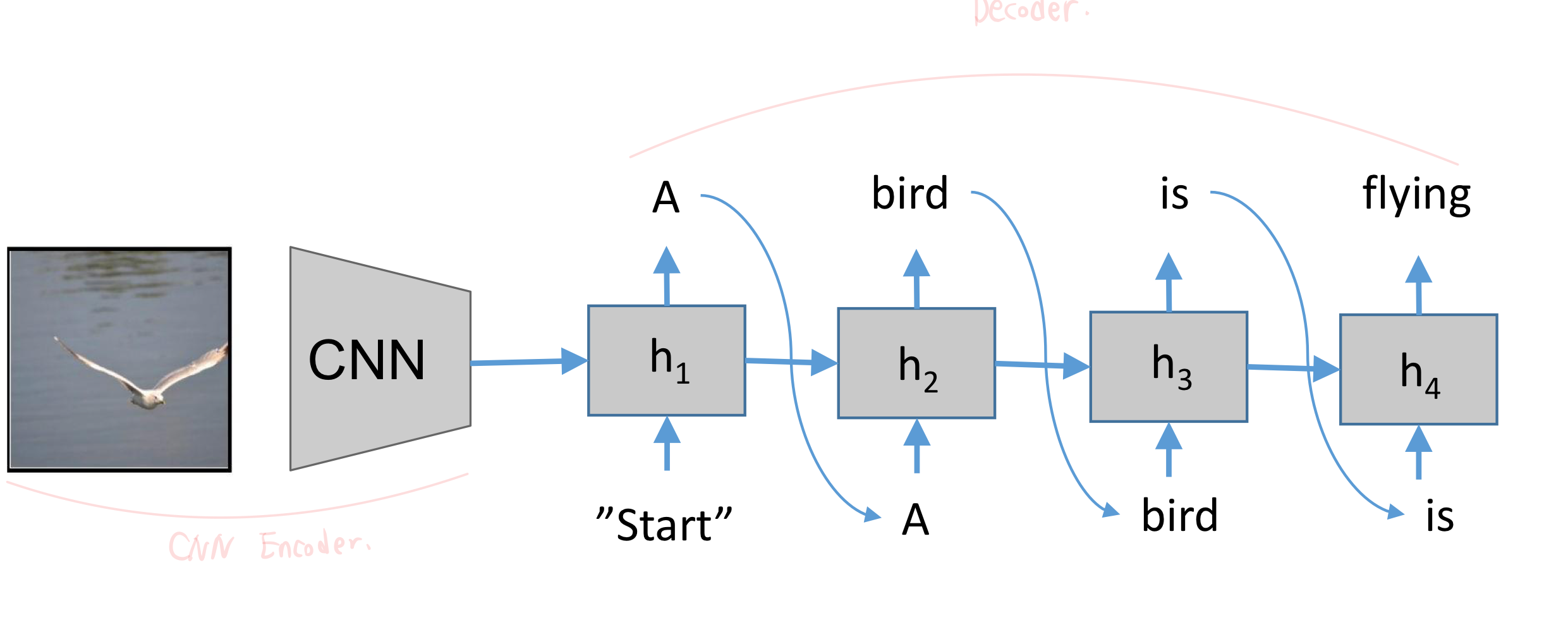
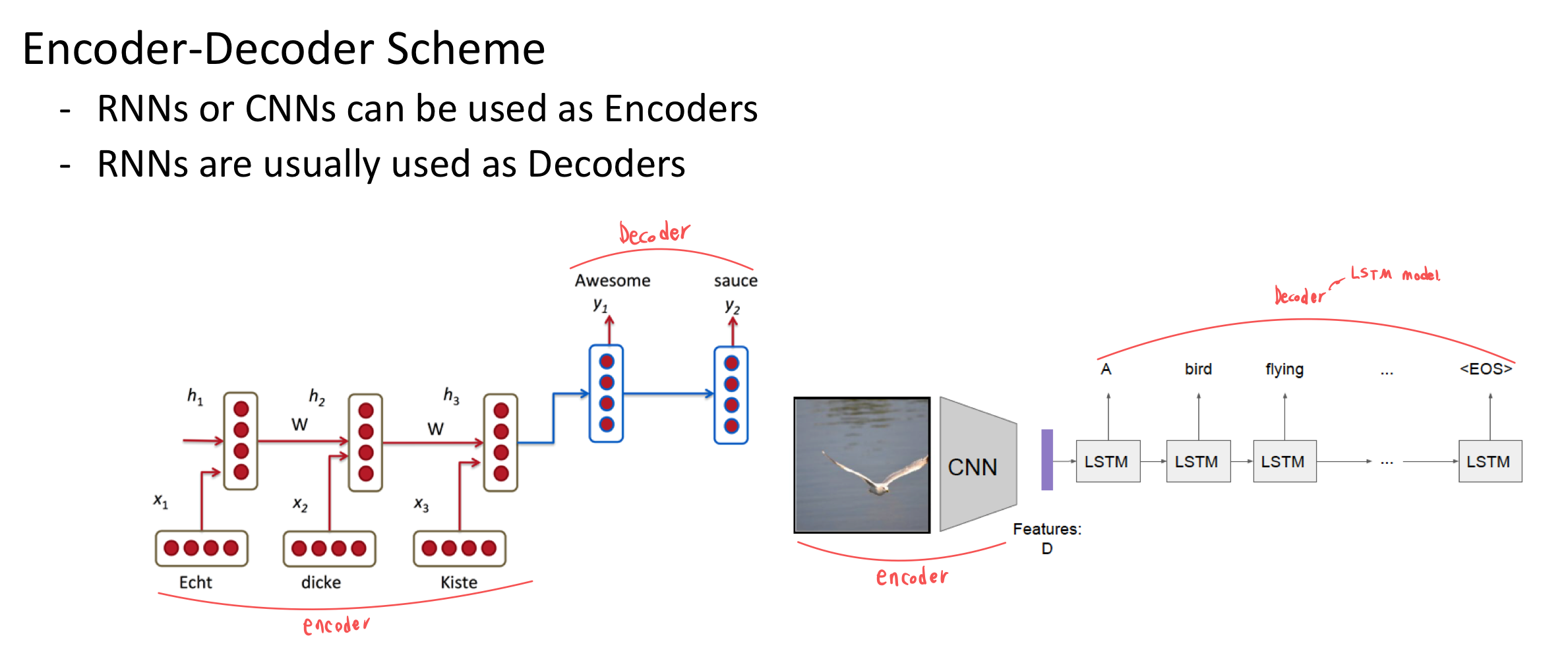
- One to Many
- Caption Generation
- Image is represented by a CNN
- Word Embedding at the input layer
- Softmax at the output layer
- Caption Generation
encoder와 decoder를 잘 살펴봅시다.
encoder는 우리가 가진 주어진 input을 가지고 output을 맞추는 것입니다.
decoder는 예측한 것인 output을 가지고 매 time마다 다시 넣어서 새로운 예측을 합니다.
- Many to Many
- Word Embedding
아래와 같이 번역을 하여,
Encoder는 주어진 input을 집어 넣은 부분입니다.
새로운 RNN을 넣은 윗 부분이 Decoder입니다.
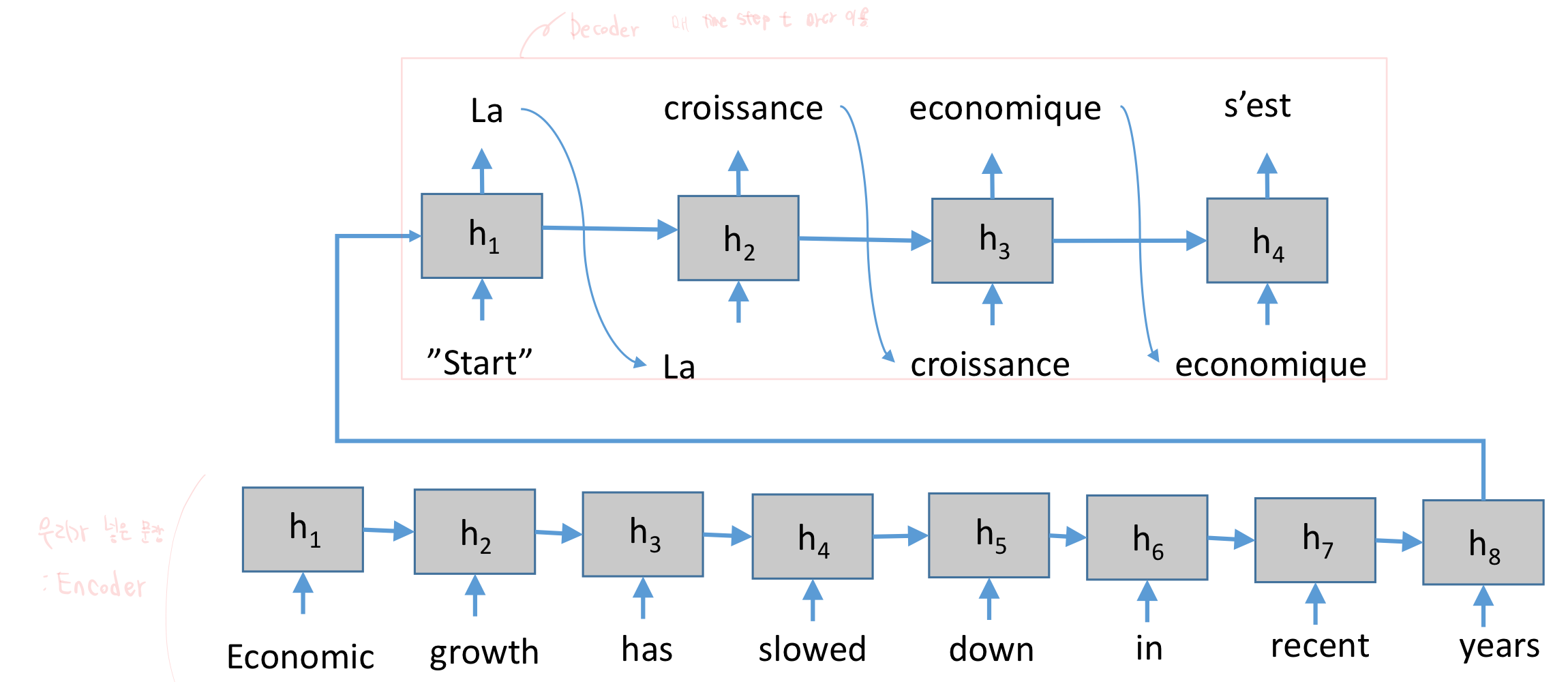
결국 정리하면 다음과 같습니다.
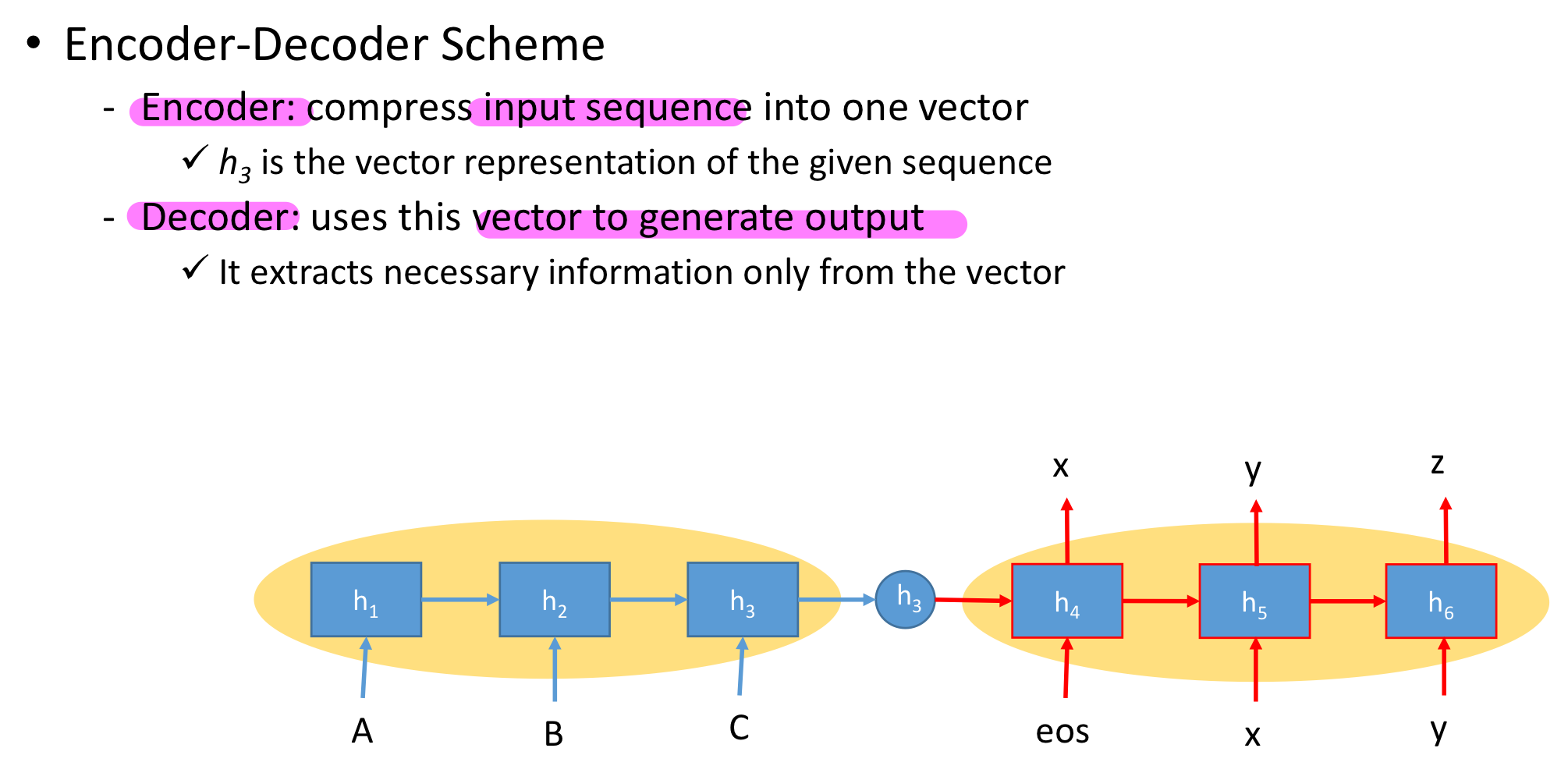
Encoder는 input sequence를 넣는 부분,
Decoder는 이것에 대한 앞 embedding 값을 가지고 뒷 output을 생성하는 부분입니다.
RNN 구조가 encoder, decoder 둘 다 될 수 있습니다.
결국, input이 어떤 구조, output 이 sequence 구조라면 encoder - decoder 구조로 modeling해야겠다고 생각하면 됩니다.
Attention을 쓰는 이유?
굉장히 긴 문장이 들어왔다고 봅시다.
100개의 hidden state가 있어서, 맨 마지막의 sentense embedding이 output 생성할 때, 모든 단어의 정보를 다 포함하고 있을까요?
output을 생성할 때, 각각의 단어를 다 보면서, 현재 hidden state와 각 100개의 hidden state간의 관계를 구하며 가장 attention score가 높은 것을 선택을 합니다.
결국, encoder가 source sentence를 하나의 vector로 encoding하기 어렵다.
그래서 이러한 seq2seq task 에서는 길이가 길 때, 성능이 떨어지는 문제가 있다.
그래서 Attention이 등장하였습니다.
'Artificial Intelligence > Natural Language Processing' 카테고리의 다른 글
| [NLP] Transformer (0) | 2023.05.21 |
|---|---|
| [NLP] Attention (0) | 2023.04.12 |
| [NLP] RNN - LSTM, GRU (0) | 2023.04.04 |
| [NLP] RNN (0) | 2023.04.04 |
| [NLP] Word Embedding - GloVe [practice] (0) | 2023.03.31 |