🧑🏻💻용어 정리
Neural Networks
Feed-forward
Backpropagation
Backpropagation
자, 지금까지 우리가 같이 Peceptron을 통해 linear problem을 해결할 수 있음을 알았고,
그를 통해 우리가 Multi-layer perceptron을 구하여, 이를 통해 Non-linear problem 또한 해결할 수 있음을 알았습니다.
여기서,
그래서 Weight를 어떻게 구한다는 건데?
라는 의문이 생길 것입니다.
그것을 이번 장에서 다룹니다.
결국 한 마디로 말하자면,
"Backpropagation이라는 알고리즘을 사용하여 구합니다."라고 할 수 있습니다.
57년도에 single-layer perceptron이 나오고, 69년도에 MLP가 나와서 우리들은 그것들을 가지고 많은 문제들을 풀 수 있게 되었습니다.
그럼에도 불구하고, 그것으로 Weight를 최적화 할 수 없다는 문제로 Neural Net을 죽이는 결과를 낳게 됩니다.
그렇게 57년에 태어나 69년에 죽었지만,
Backpropagation이 86년에 등장하며 NN을 다시 살리게 됩니다.
Backpropagation은 수학적으로 존재하던 것이지만, 실제로 존재하였지만,
MLP에서 Weight를 update하는 목적으로 쓰이게 된 것은 이번이 처음입니다.
그리고, 번외로 95년도에 SVM으로 다시 죽었다가, 06년도에 DBN으로 다시 살아나서 현재 전성기를 맞고 있는 Neural Net의 역사적인 순간을 여러분 함께하고 계십니다.
자 그럼 Backpropagation에 대해 더 자세히 알아봅시다.

이것은 error backpropagation 이라고 칭하며,
우리 말로 역전파 알고리즘이라고 합니다.
결국,
Gradient descent method에 기반하여 error 를 역전파 시키며 weight를 optimization하는 방법이라고 소개할 수 있습니다.
위 그림과 같이 Input layer, Hidden layer, Output layer를 지나고, loss가 나옵니다.
이 Loss로부터 뒷 방향으로 거슬러 올라가게 됩니다.
결국 우리는 Gradient Descent 방식을 활용해서 Backpropagation을 하게 됩니다.
Gradient Descent
위와 같이 random 값으로 설정된 initial weight에서, 계속해서 update를 통해서 최적의 weight를 찾아가는 것입니다.
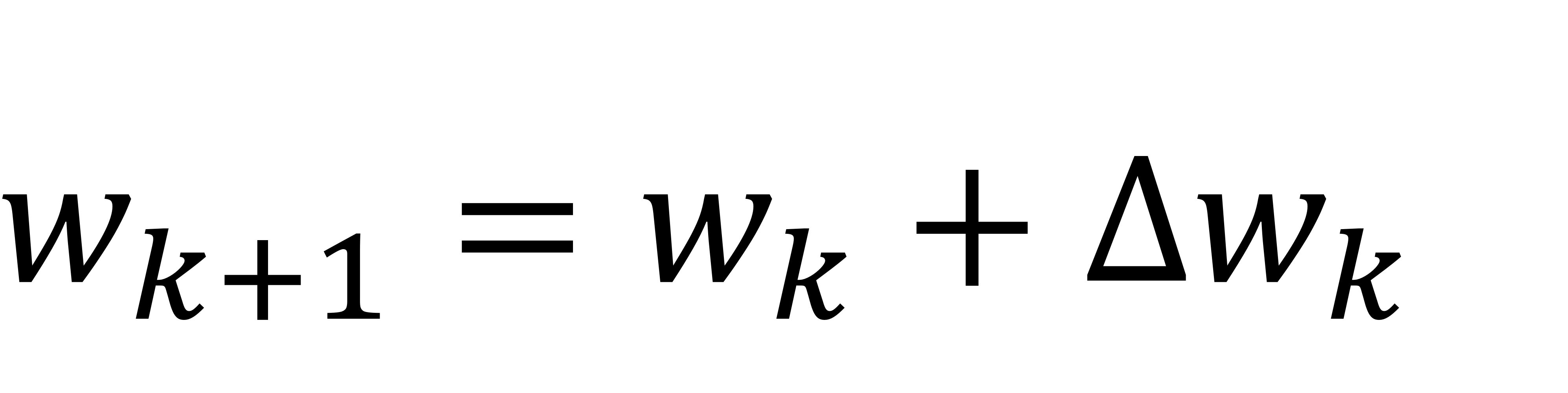
결국 weight들은 scalar 값을 가지는 weight들입니다.
결국 scalar의 관점에서 볼 때,
이 weight 값을 증가시킬 것이냐. 감소시킬 것이냐.
이 두 가지로 나뉩니다.
그래서 위 방향을 결정해야합니다.
결국 이 방향은 기울기로 결정됩니다.
기울기가 현재 +이면 -로 update,
기울기가 현재 -이면 +로 update.
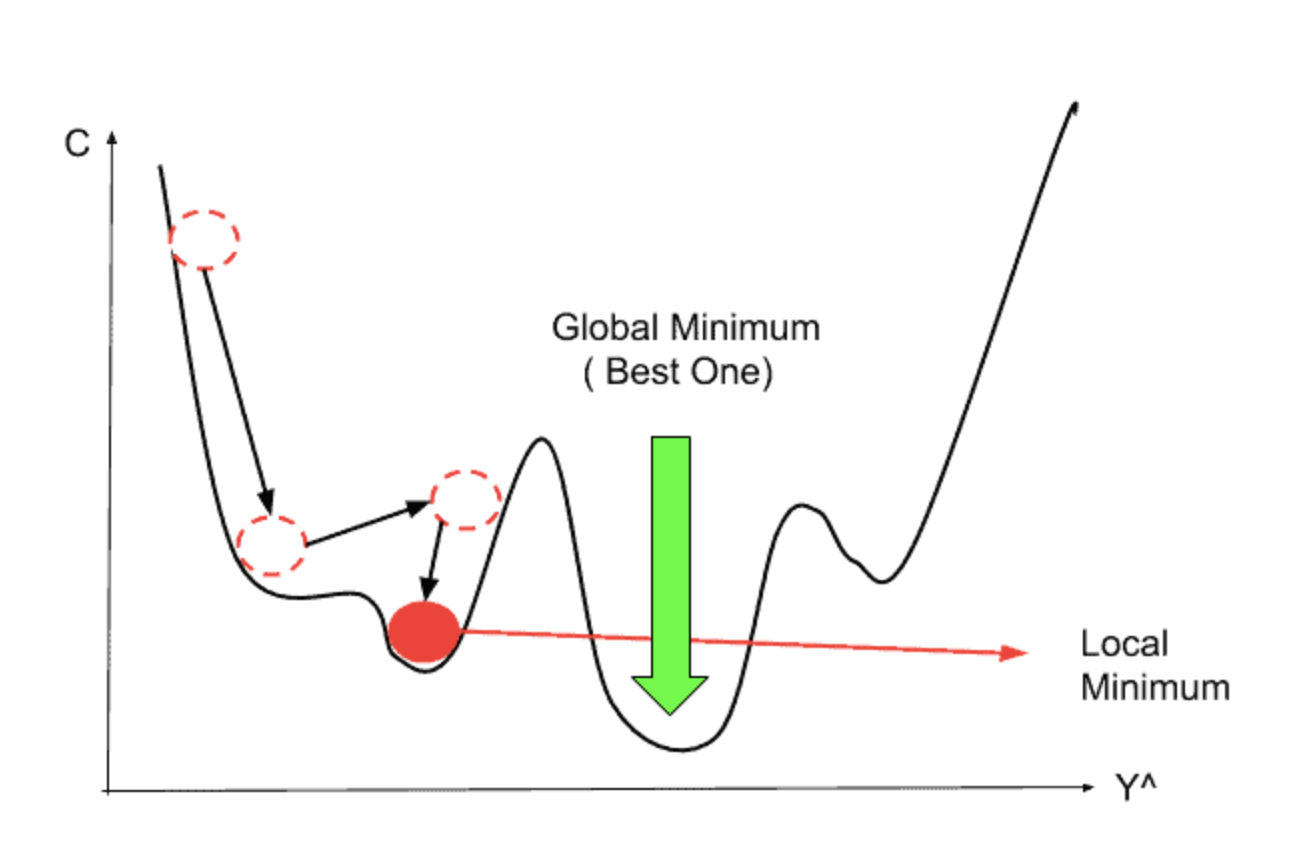
위와 같이 우리가 알고 있는 함숫 값에 대해서는 +와 -를 잘 결정할 수 있지만,
자동화된 algorithm이나 loss function이 더 복잡해진다면 우리는 이것을 눈으로 보고 할 수 없게 됩니다.
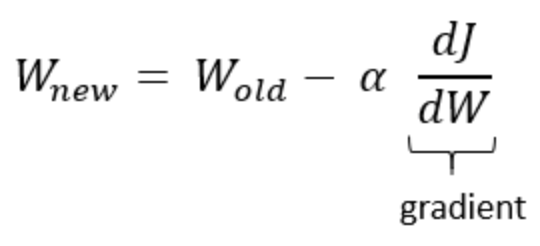
그래서, 우리는 위와 같이 loss function을 내가 변화시킬 수 있는 weight로 미분한 값이 update하는 값이 됩니다.
그리고 -를 붙여서 기울기의 역방향으로 가는 것으로 볼 수 있습니다.
위 수식으로 미루어 볼 때,
기울기 값이 -이면, weight 값이 커지게 되고, 기울기 값이 +이면 weight 값이 커지게 됩니다.
그래서 이 기울기를 통해 얼마나 update하냐에 대한 실마리가 풀리게 됩니다.
그렇다면, 이제 weight를 update하는 방향을 설정하였고,
이제 얼마나 update할 건지를 결정해야합니다.
그래서 에타라는 hyperparameter를 위와 같이 정의합니다.
우리는 이 에타를 learning rate라고도 부릅니다.
즉, 학습률이라는 것입니다.
우리의 gradient를 얼마나 학습에 반영시킬 것인가? 입니다.
hyperparameter는 model의 outside에 존재하며, 사람이 직접 정해줍니다.
지금은 이것을 상수로 보겠습니다.
그러나, 이 learning rate도 adaptive learning rate라고 하여, 중간 중간 수정이 가능한 형태도 존재합니다.
그러나 이것을 지금은, 상수로 보겠습니다.
learning rate가 100이라면, 우리가 정한 gradient의 방향에 대해서 100만큼 곱해서 update하는 것이고,
learning rate가 0.01이라면, 우리가 정한 gradient의 방향에 대해서 0.01만큼 곱해서 update하는 것입니다.
이것은 보폭을 크게 갈지 성큼성큼 갈지를 결정하는 크기가 되는 상수로 보시면 될 것 같습니다. (아직까진 상수로 보기 바랍니다)
Backpropagation in MLP
자, 이제 Backpropagation이 MLP에서 어떻게 활용되는지 자세히 보도록 하겠습니다.
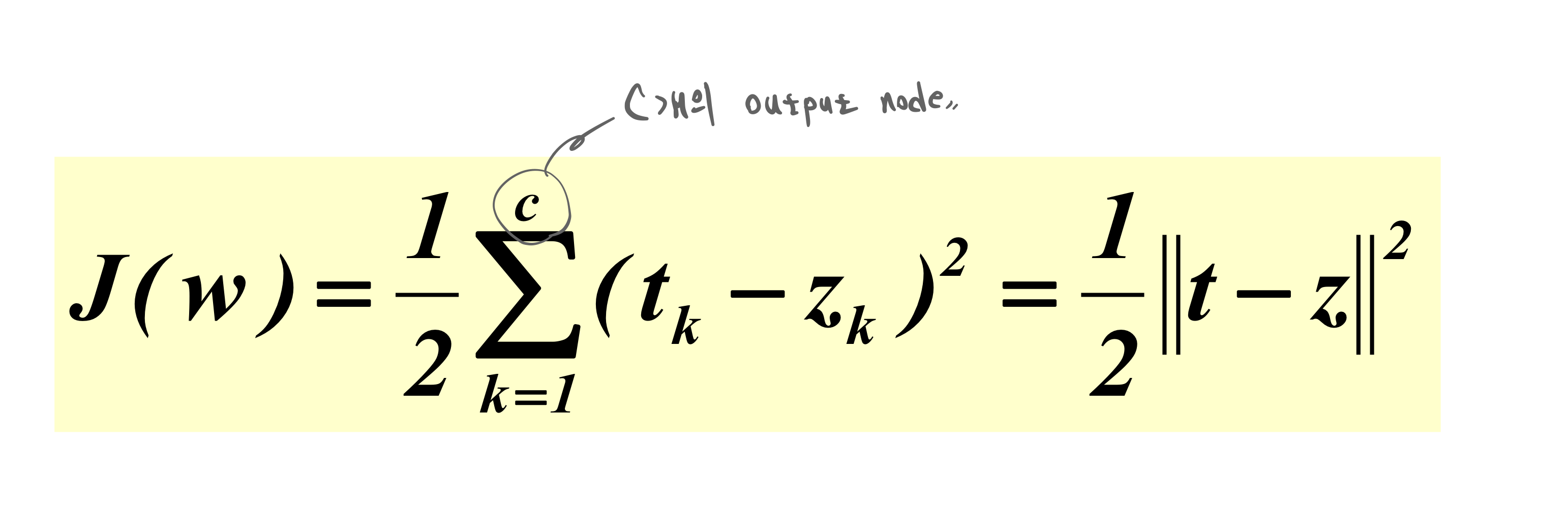
Loss Function으로서의 MSE를 사용하여 performance에 대한 measurement입니다.
이 MSE를 그대로 Objective function 최적화에 사용합니다.
우리 model의 performance 적인 목적과 model을 training 시키는 최적화에 대한 목적을 일치시켜 유리하게 가져갑니다.
performance에 대한 measurement 마다 장단점이 있지만, MSE의 미분 가능함은 후속조치를 쉽게 만들고, 최적화 시 바로 직접적으로 활용할 수 있게 됩니다.
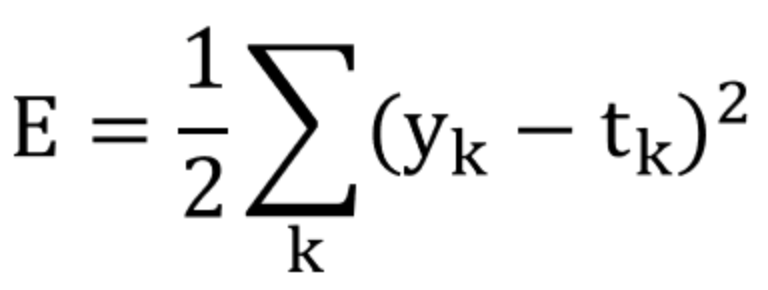
- k - output node index
- t - target, y
- y - mdel output, y^
아래와 같이 Backpropagation 과정을 볼 수 있습니다.
output에서 hidden과 먼쪽부터 시작합니다.
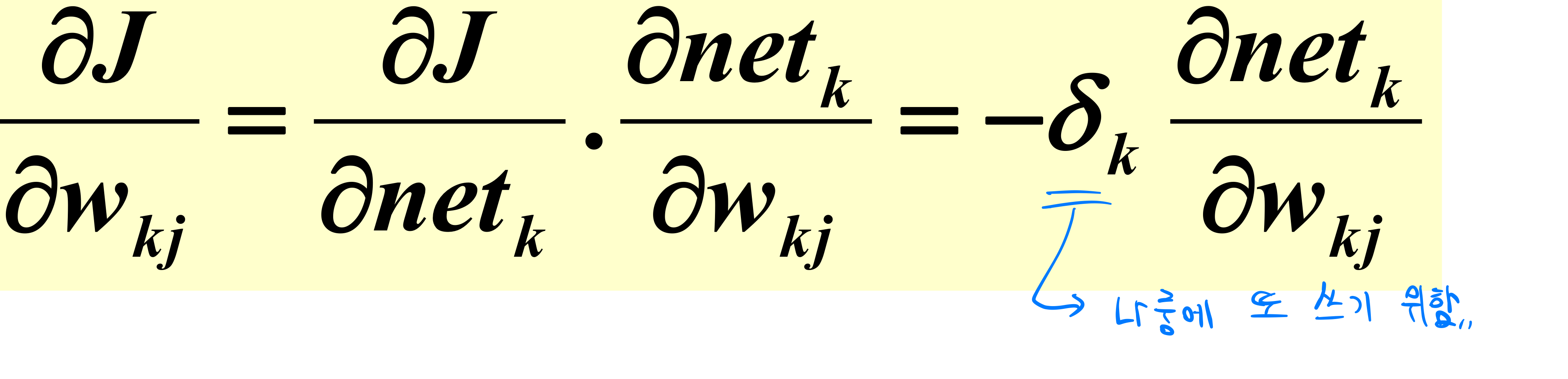
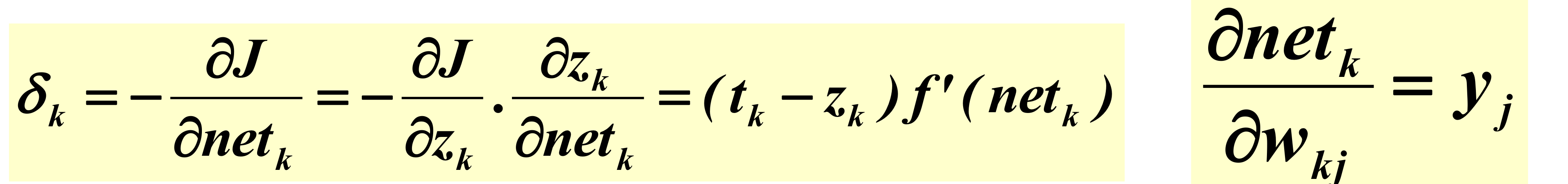
위와 같은 수식들을 잘 살펴보시기 바랍니다.
output에서 loss가 있어 역으로 파고들어갑니다.
그리고 weight의 방향에 따라 여러 가지 경우의 수가 존재합니다.
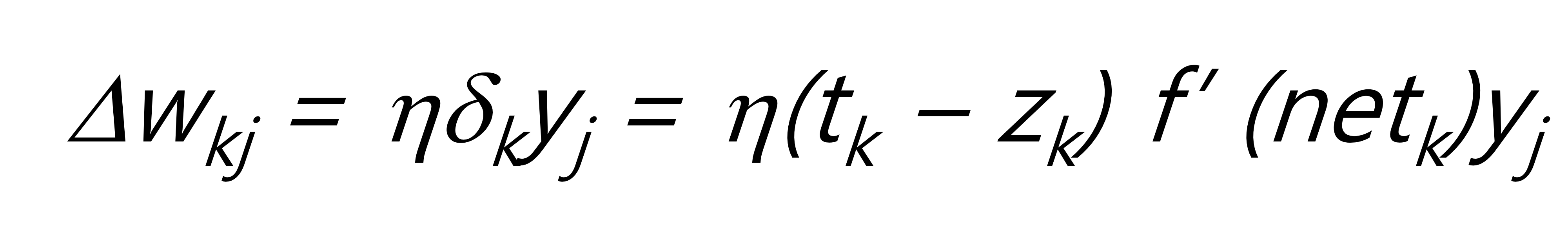
위 수식은 아래와 같은 성질을 가집니다.
- activation function의 미분값이 클 수록 update가 많이 된다.
- hidden node의 실제 signal, 값인 y 값이 클 수록 update가 많이 된다.
- target과 실제 값 사이의 차이가 클 수록 update가 많이 된다.
여기서 델타k는 output node의 sensitivity를 의미하고, yj는 hidden node의 기여도를 의미합니다.
그리고 yj인 signal은 기여도가 클 수록 update도 많이 되는 것입니다.
즉, 목소리가 큰 놈이 책임을 더 많이 지게 되는 것이지요.
지금까지 hidden layer - > output layer를 알아봤습니다.
이제 input layer -> hidden layer로 가는 weight update를 알아보겠습니다.

hidden layer -> output layer와 다르게,
input layer -> hidden layer에서의 weight update는 input부터 output에 뻗는 개수까지 모두 영향을 미치므로,
이 모든 것을 고려해주어야 합니다.
그래서, 중첩되어 있는 Neural Net의 weight update가 까다로운 것입니다.
위 식을 계산하면, 아래와 같이 나옵니다.
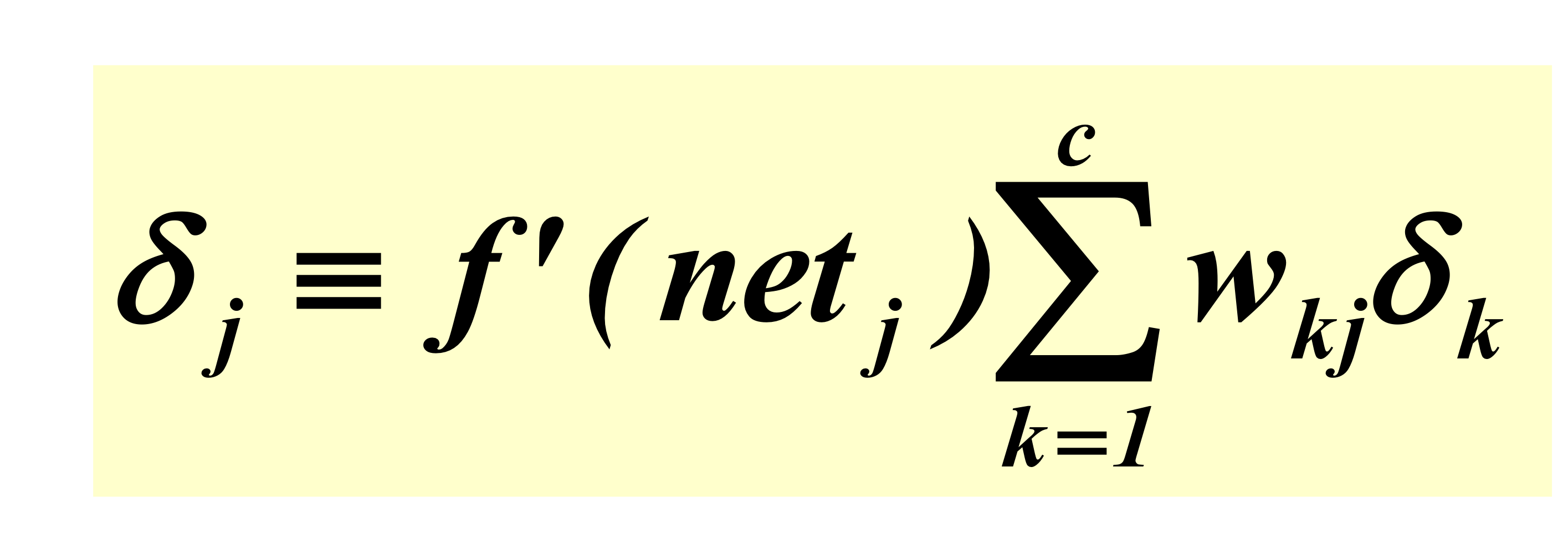
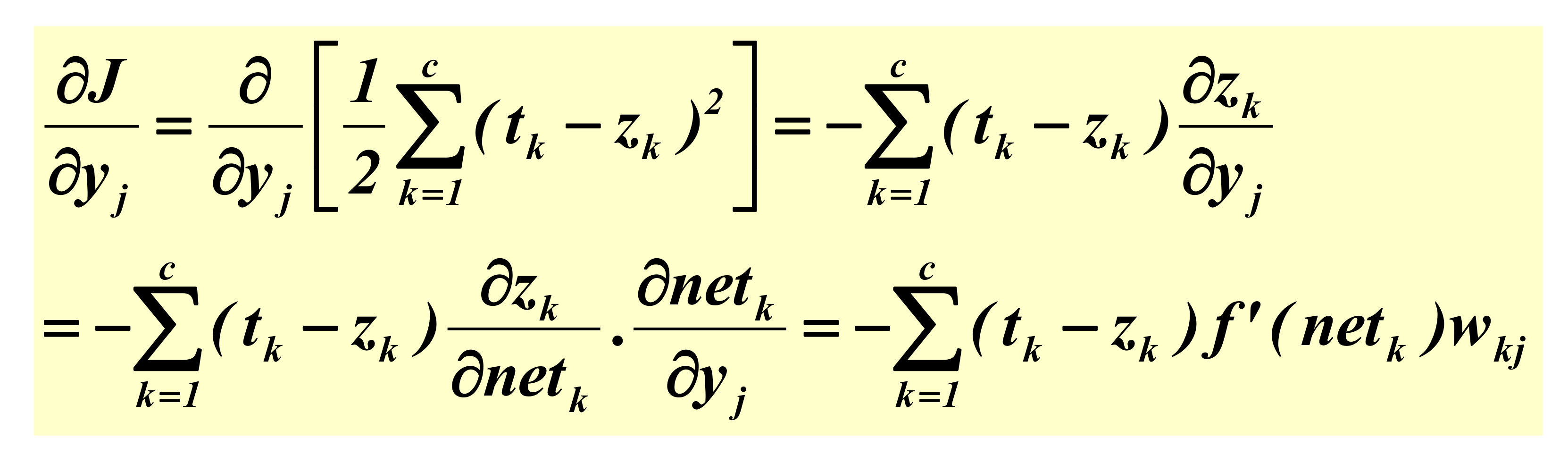
계산의 최종 결과는 다음과 같습니다.
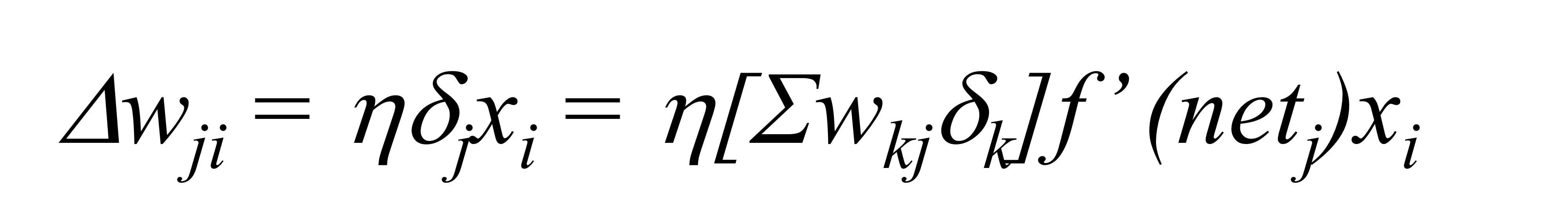
자, 이렇게 3-layer MLP에서 Loss function을 MSE로 가정했을 때, weight update 과정입니다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [Deep Learning] Generating regression model for California housing dataset with Keras functional API (0) | 2023.04.05 |
|---|---|
| [Deep Learning] Backpropagation in special Functions (0) | 2023.04.03 |
| [Deep Learning] Feedforward (0) | 2023.03.27 |
| [Deep Learning] - MLP(Multilayer Perceptron) (0) | 2023.03.26 |
| [Deep Learning] - Neural Networks (0) | 2023.03.26 |