
[Deep Learning] - Neural Networks
🧑🏻💻용어 정리
Neural Networks
Linear Separability
Optimization
Perceptron
Activation function
오늘은 NN이 무엇인지에 대해 알아보고자 한다.
Neural Networks (NN)
뉴럴 네트워크.
이것은 사람의 뇌를 흉내내어 만든 mathematical model이다.
수학적으로 흉내낸다.
- 데이터가 들어온다.
- 데이터가 weight와 함께 다른 networs들과 연결된다.
- 마냑 function의 값이 충분히 강하다면, node가 activation 된다.
이를 ANN, Artificial Neural Networks라고도 한다.
대부분의 알고리즘들이 special한 NN의 form으로 묘사될 수 있다.
이것에는 다음과 같은 항목들이 존재한다.
- Bayesian classifier
- support vector machines
- decision tree
- etc..
Deep learning은 NN에 포함되어 있다.
Linear Separability
여기에는 Classification problem이 존재한다.
즉,
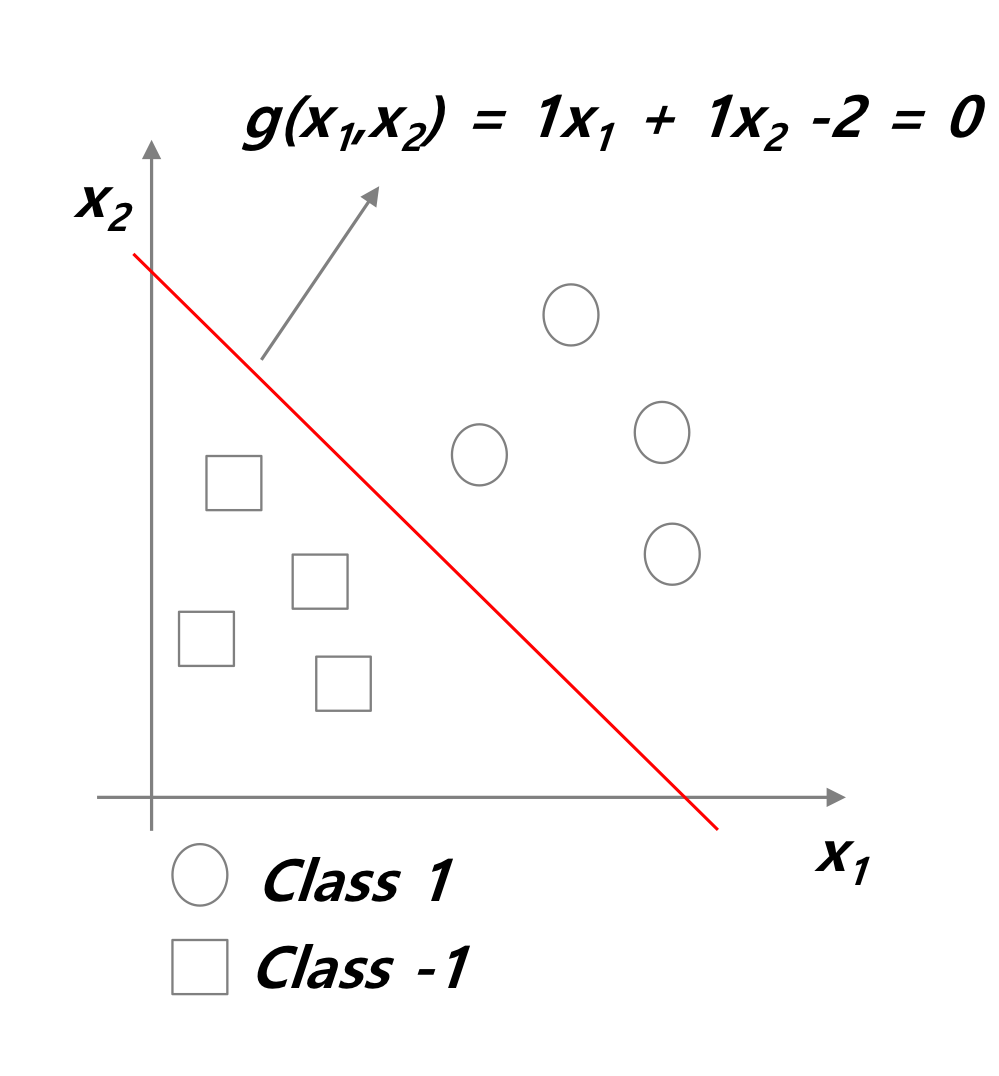
위 그림과 같이 분류하는 문제이다.
어떤 함수 g(x)에 대해여 두 가지로 분리한다.
여기서 g(x) = 0 이 되는 것을 다음과 같이 이름 붙인다.
- Decision boundary
- Decision Surface
- Decision hyperplane
- Class boundary
- ...
위는 original space를 두 가지 subspace로 분리하는 linear function이라고 할 수 있다.
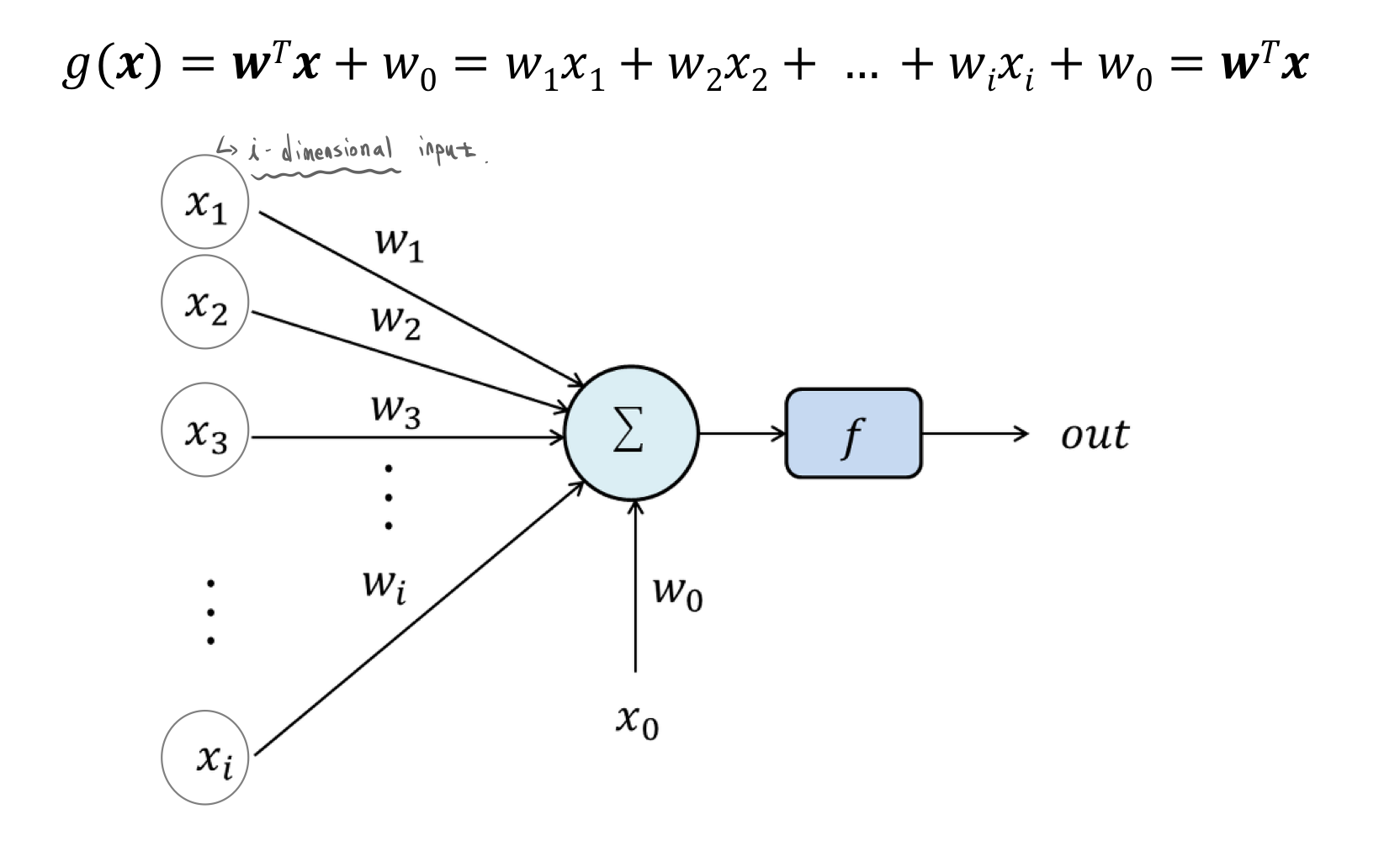
Generalize to multivariate proble
이와 같이 앞에서 봤던 g(x) 함수를 일반화 할 수 있다.
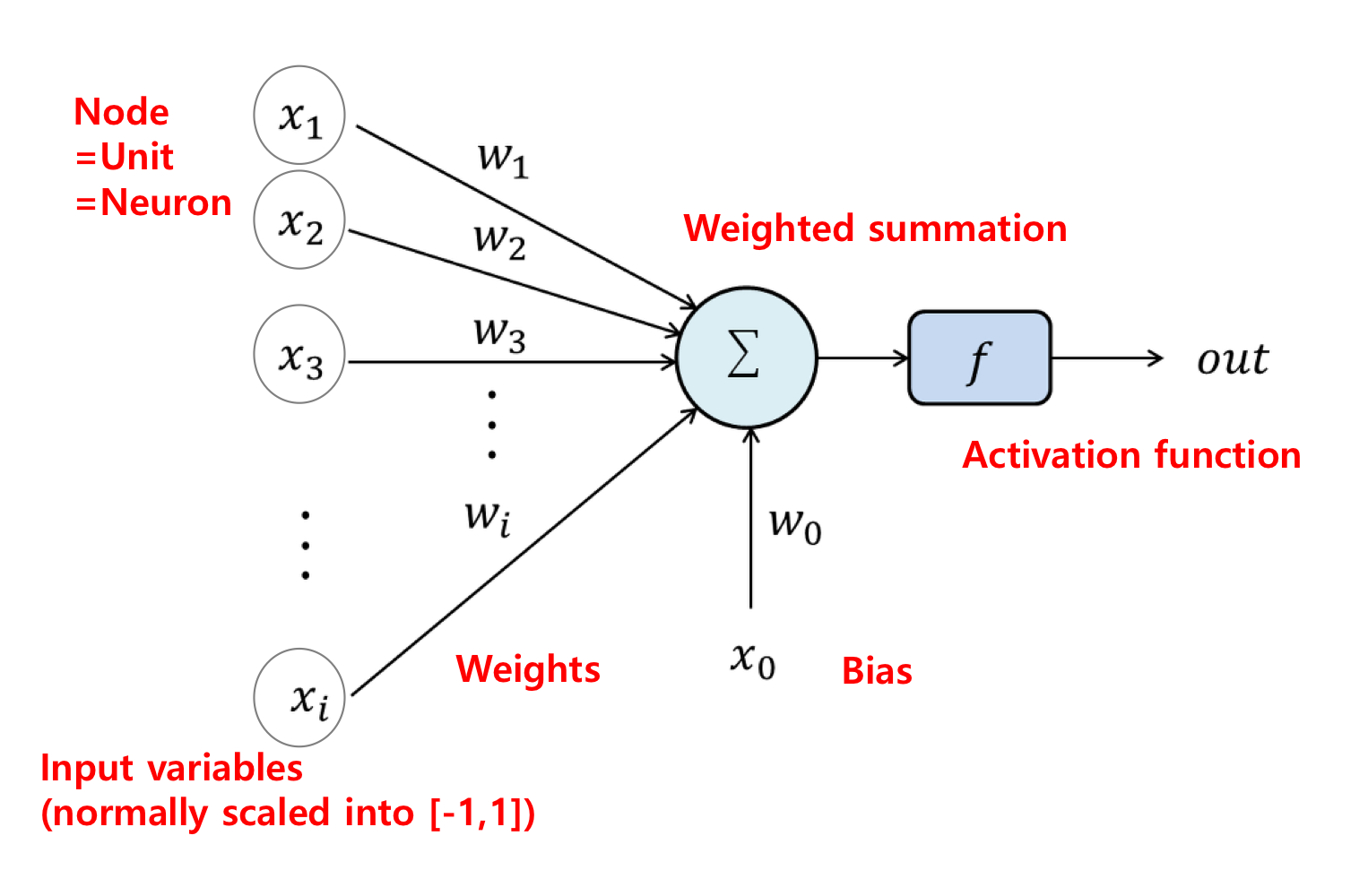
이에 대한 용어도 위와 같이 정리할 수 있다.
하나 하나의 Neuron 들을 unit or node라고도 부른다.
그리고 이것들에는 input variables가 들어간다.
그리고 이것들에 Weight가 곱해진다. 이것들을 모두 더한 뒤 Bias 항까지 더하면 Weighted Summation이 만들어진다.
그리고 !!!
이것이 끝이 아니다 !!!!
여기에 Activation function을 통과시킨 후 나오는 것이 output이 된다.
즉 우리가 원하는 값은 Weighted Summation이 아니라 그 값에 Activation function을 통과시킨 Output 값이다.
Optimization
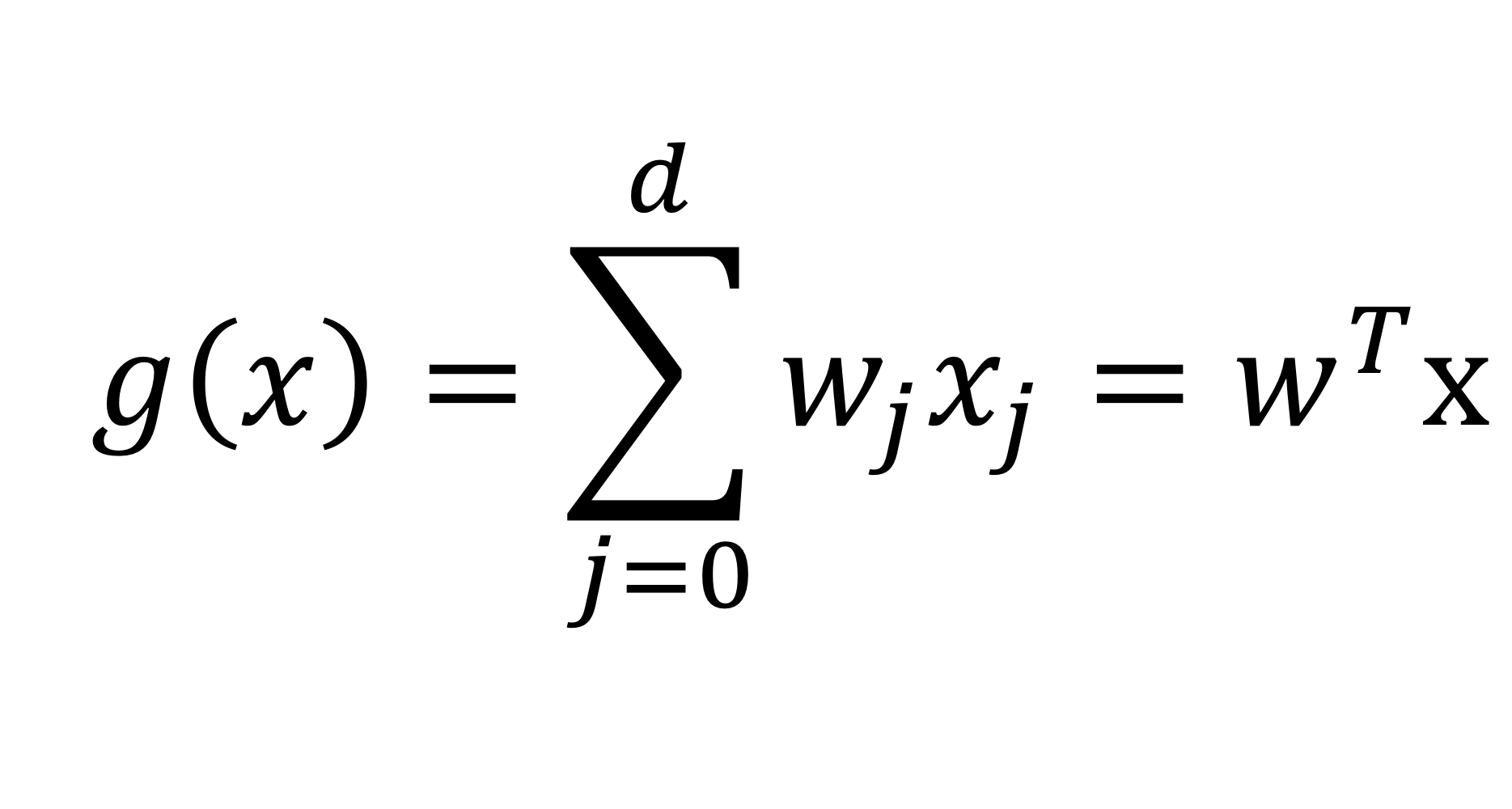
아까 Classification problem에서 본 그림을 위 식에 대하여 적용한다.
위 g(x) = 0 일 때의 값이 우리가 원하고자하는, 우리가 학습을 통해 얻고자하는 학습 목표가 된다.
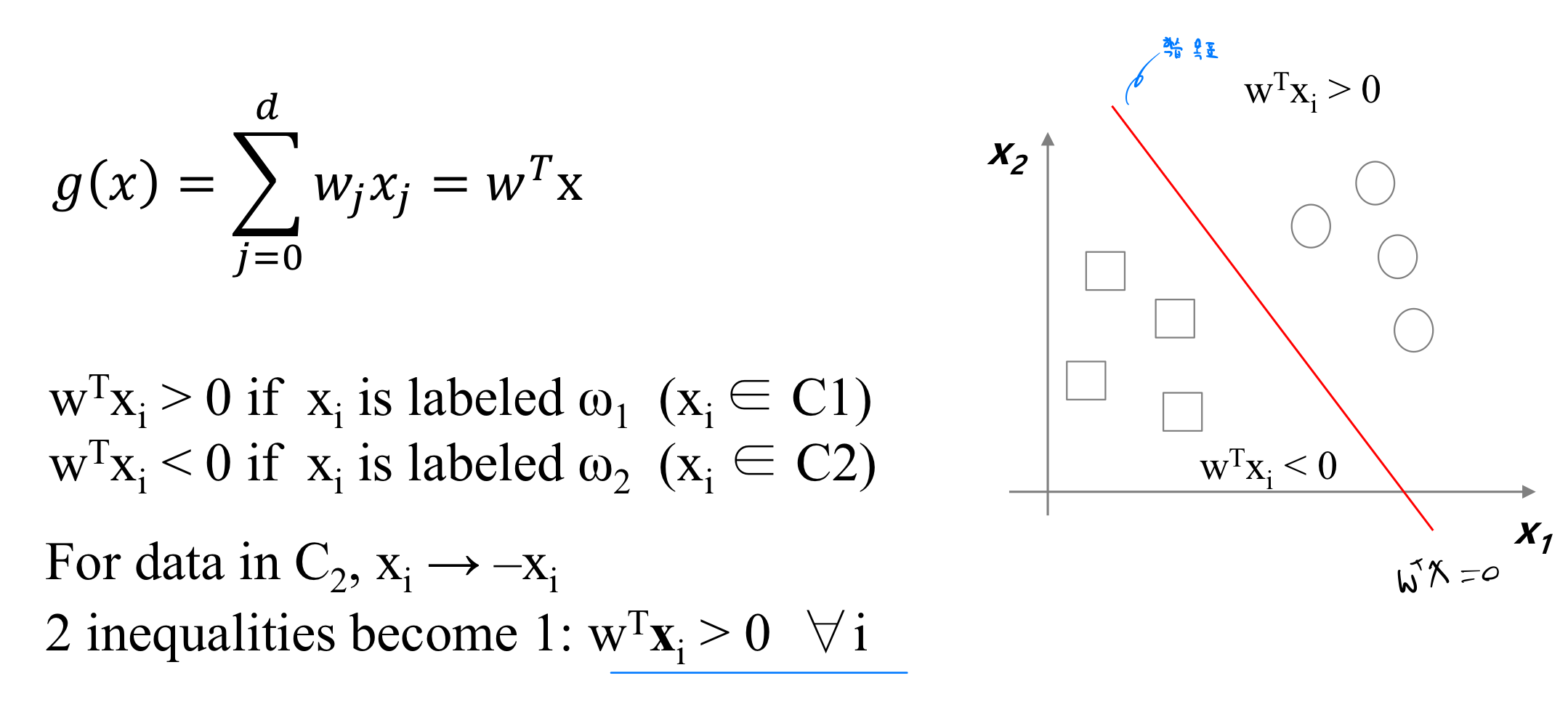
위 그림에서 보면, 우리는 g(x)의 값이 학습 목표이다. 그리고 이 값보다 큰 값을 동그라미, 작은 값을 네모로 Classification 한 것이다.
여기서 볼 수 있는 것은 여러 가지 동그라미와 네모의 데이터를 통해서 우리는 hyperplane을 학습시켰다는 것이다.
그리고 g(x)의 값이 0보다 큰 경우와 작은 경우로 나뉘므로, 0보다 작은 경우에 대해서는 데이터들을 x -> -x로 치환한다.
그리고 나서 0보다 큰 경우에 대한 식으로 바꾸어 계산을 더 쉽게 만든다.
그리고 여기서 만일,
새로운 데이터가 들어온다면,
g(x) > 0 값인데, 현재 학습된 데이터로 계산했을 때 0보다 작은 영역으로 간다면 우리는 다시 hyperplane을 update 시켜줄 필요성이 있다,
이럴 때 우리는
Gradient Descent
방법을 이용한다.
이 방법을 통해서
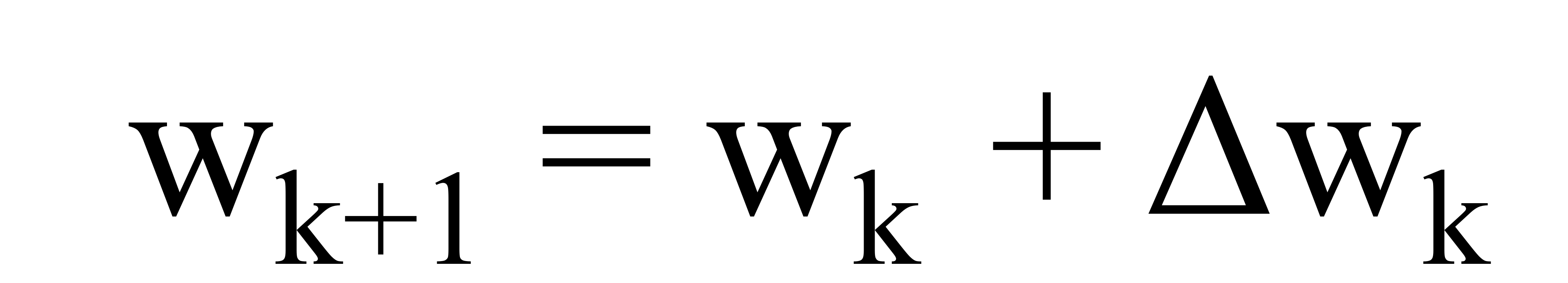
위와 같은 수식을 통해 새로운 input인 데이터를 통해서 weight를 update한다.
그리고 다시 학습된 데이터를 사용한다.
- 이것은 Weight와 misclassified data가 필요하다.
- 여기서 g(x)는 misclassified data로 덮인다.
- misclassified data는 의무이다.
- 만약 data가 아주 크게 misclassified 되어 있다면 gradient 는 커진다.
우리는 위에서 본 이것을 하나의 perceptron이라고 부른다.
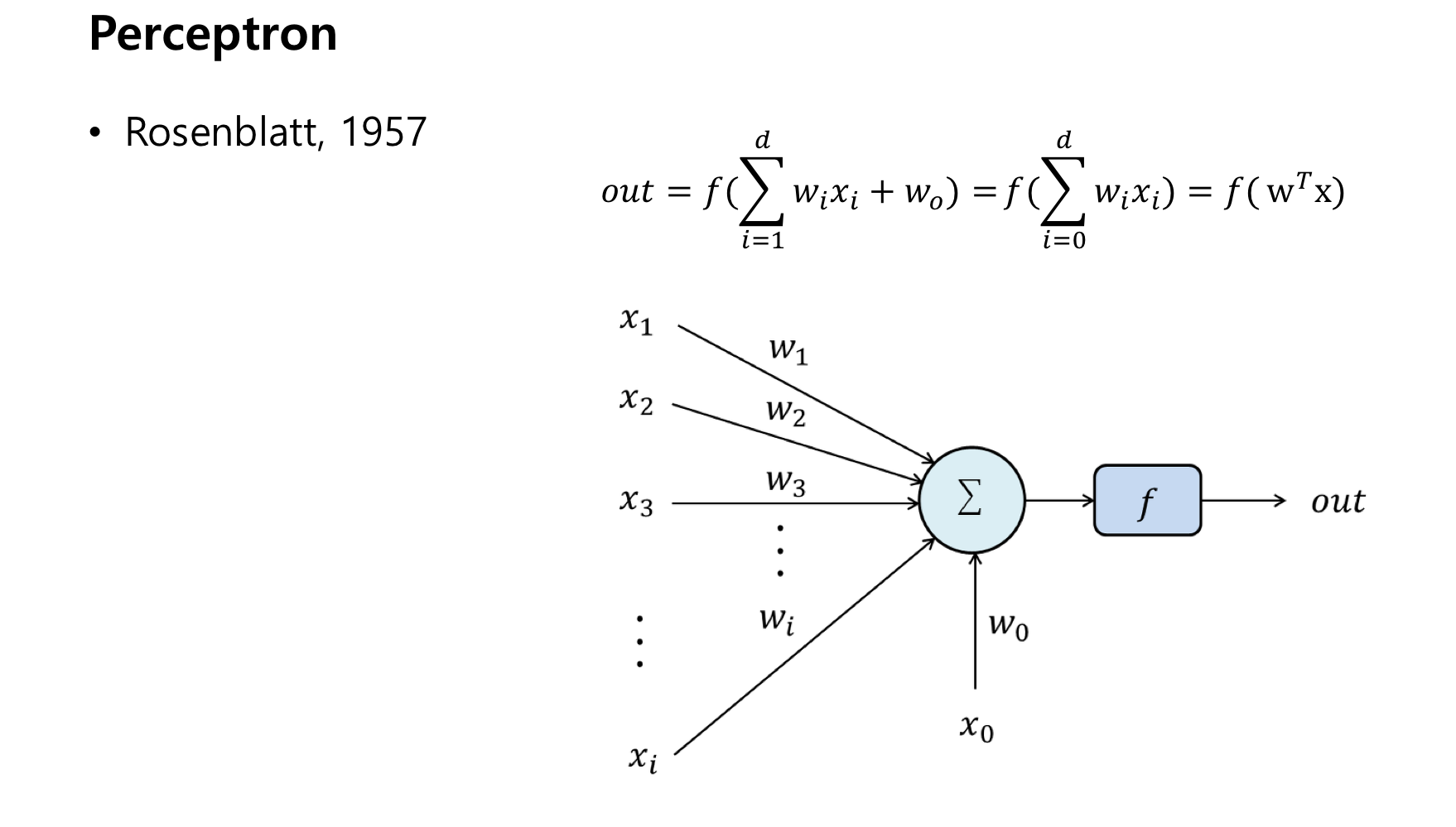
이 perceptron을 통해서 우리는 linear problem을 해결할 수 있게 되었다.
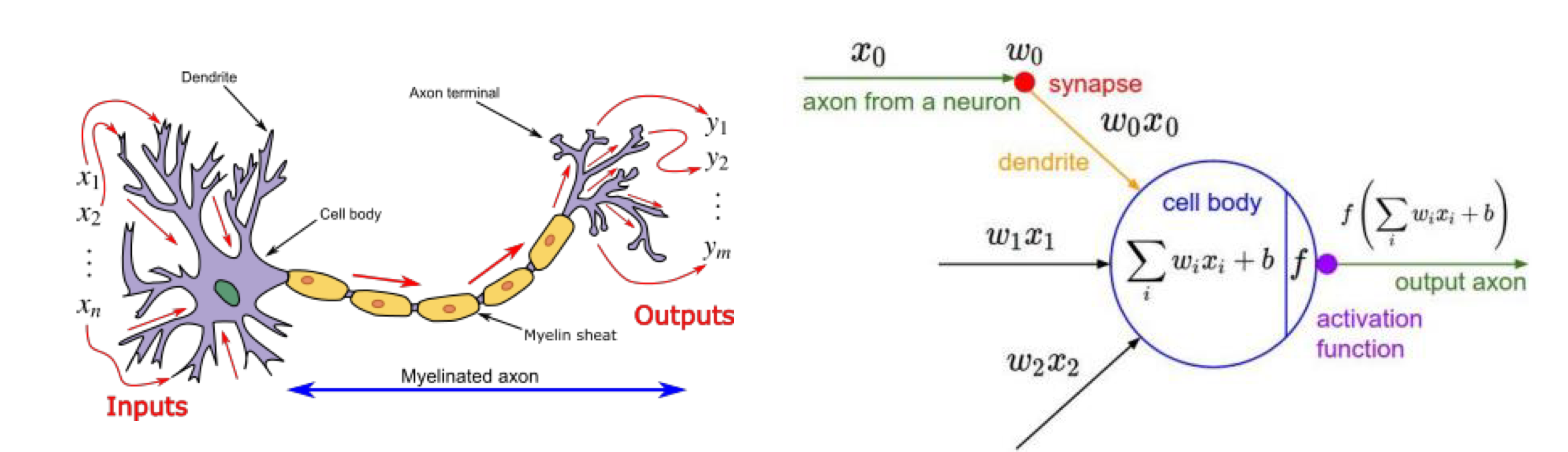
위와 같이 인간의 brain을 모방하여 고안해낸 아이디어이다.
앞 neuron output이 다음 neuron input이 된다.
그리고 이러한 전기 신호에 대한 크기로 output을 보고. activation function이 활성화 여부를 결정한다.
그렇다면, Activation function 에 대해 알아보자.
Activation function
위 그림과 같이 output으로 나온 Weighted Summation, 이러한 continuous output을 probability of decision의 형태로 배출한다.
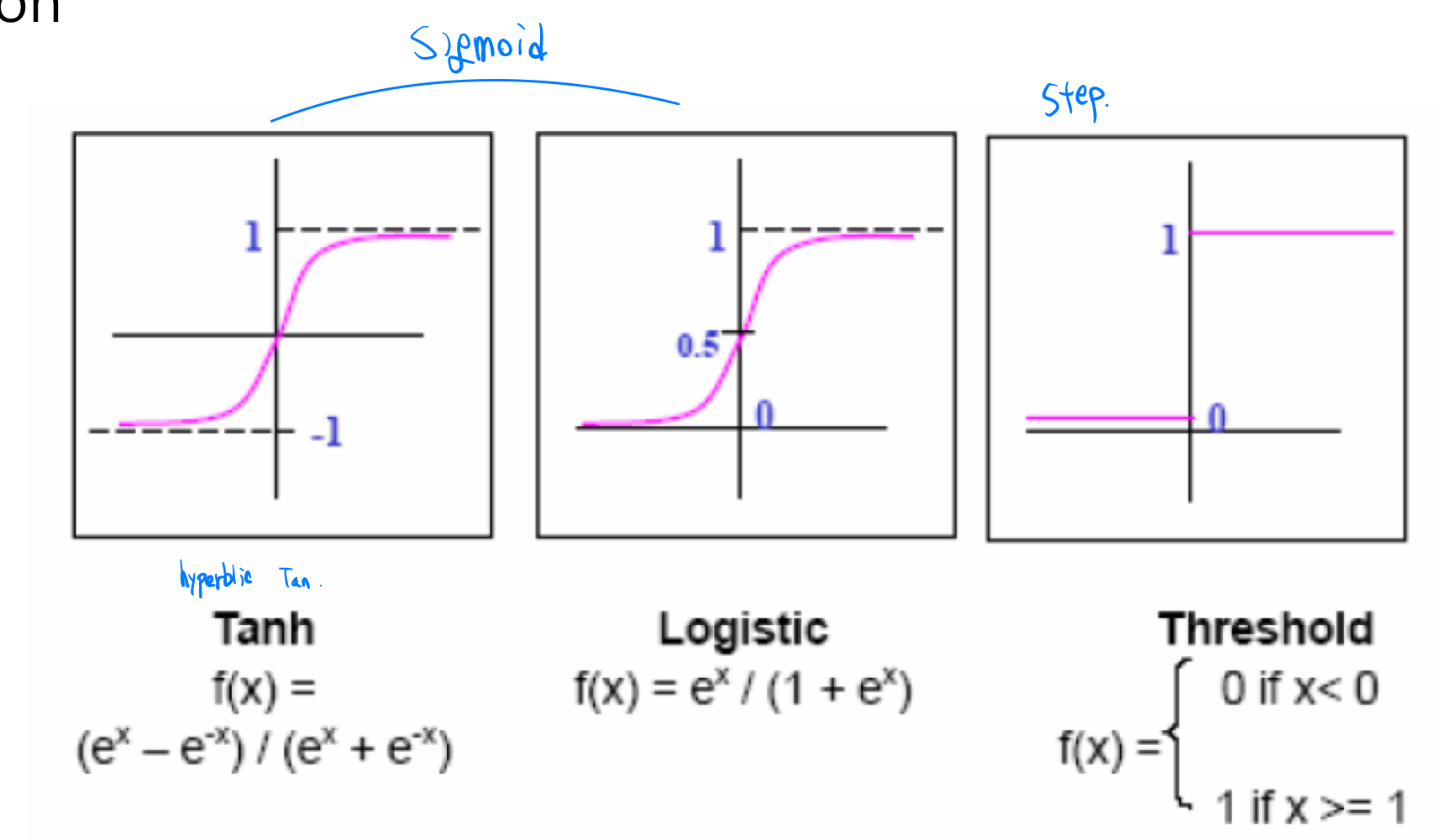
위와 같은 형태로 존재한다.
본래 step function의 형태로 존재했다고 본다.
원래 step function의 형태라면 0보다 크면 activation,
0보다 작다면 deactivation이 맞다.
그런데, 우리는 미분을 너무나도 좋아하는 사람들이기 때문에, 위와 같은 step function에서는 미분하여 계산할 수가 없다.
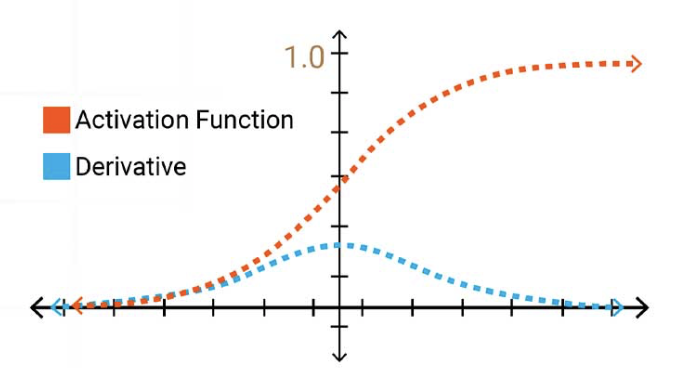
그리하여, 우리는 위와 같은 sigmoid function의 형태를 도입하게 되었다.
그러나, 나중에 다루겠지만 위와 같은 sigmoid function도 문제는 존재한다.
Vanishing Gradient와 같은 문제들이 발생하므로 우리는 위와 같은 함수를 특수적인 상황이 아니면 반영할 수 없게 되었다.
그리하여 우리는 neuron 모방 말고 학습에 도움이 되는 방향으로 다시 activation function을 만들었다.
그것은 ReLU function이다.
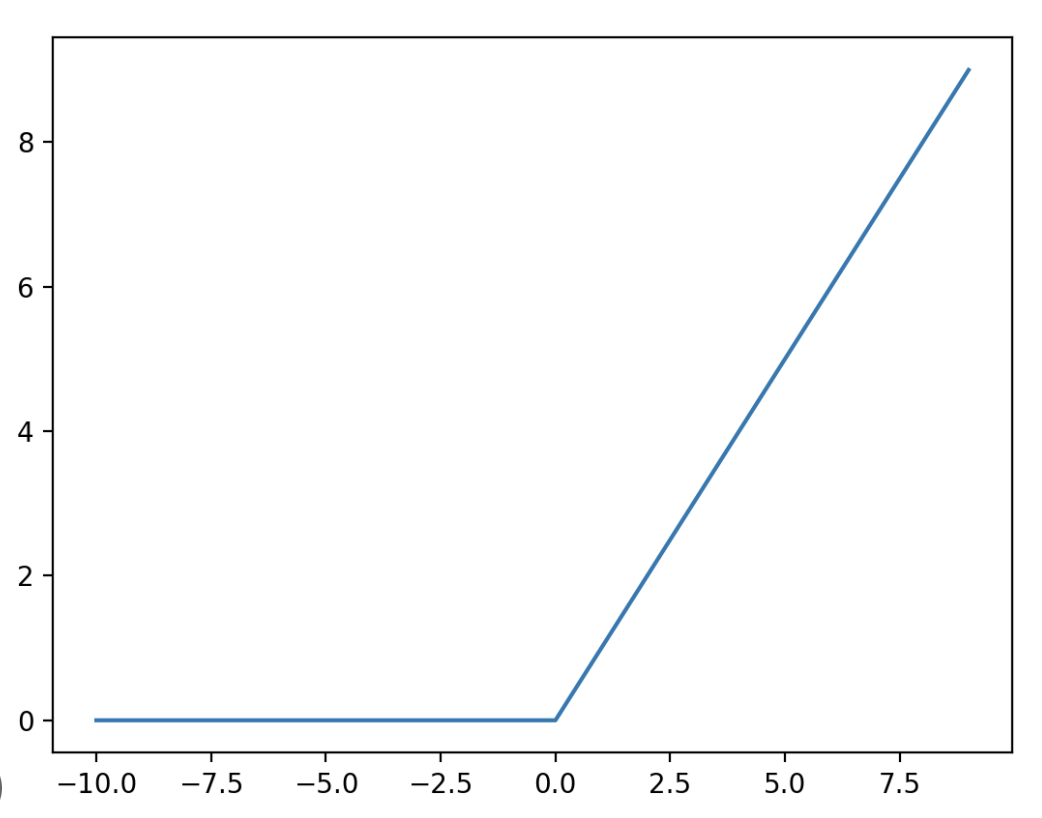
우리는 이 함수로 더 나은 학습을 이루어냈고,
또 다른 변형 형태로도 많이들 존재한다. 연구는 계속되고 있다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [Deep Learning] Feedforward (0) | 2023.03.27 |
|---|---|
| [Deep Learning] - MLP(Multilayer Perceptron) (0) | 2023.03.26 |
| [Supervised Learning] 지도 학습 (0) | 2023.02.08 |
| [Machine Learning] 신경망 기초 3 (0) | 2023.02.08 |
| [Machine Learning] 신경망 기초 2 (2) | 2023.02.06 |








