
[Deep Learning] Backpropagation in special Functions
🧑🏻💻용어 정리
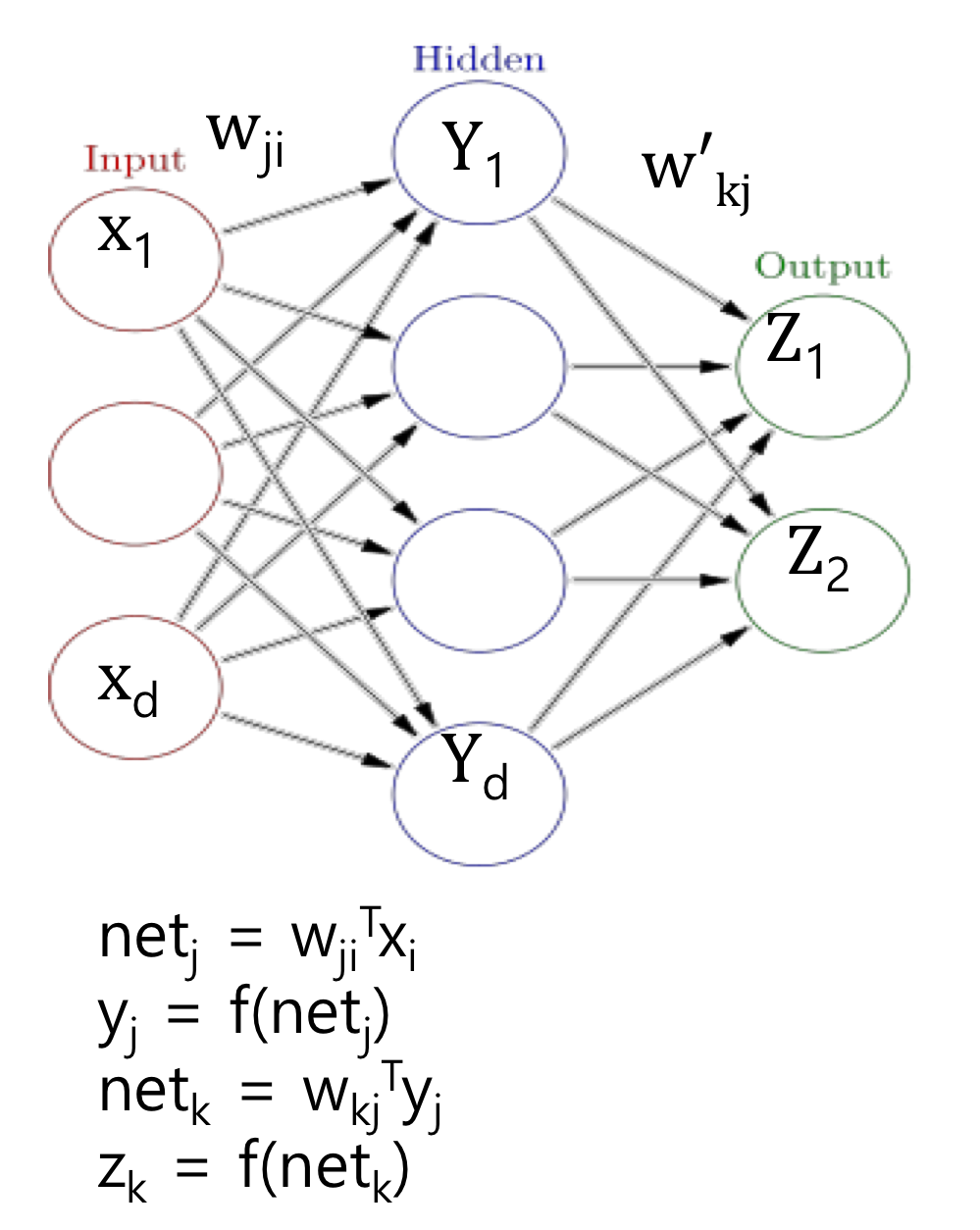
Neural Networks
Feed-forward
Backpropagation
지금까지 조금은 general한 형태의 부분들을 많이 보셨다면,
이번에는 실제로 더 많이 쓰이는 function들의 미분값을 살펴보겠습니다.
Backpropagation
앞에서는 f'(net)으로 activation function을 계산하고 넘어갔습니다.
조금 더 special한 형태를 보겠습니다.
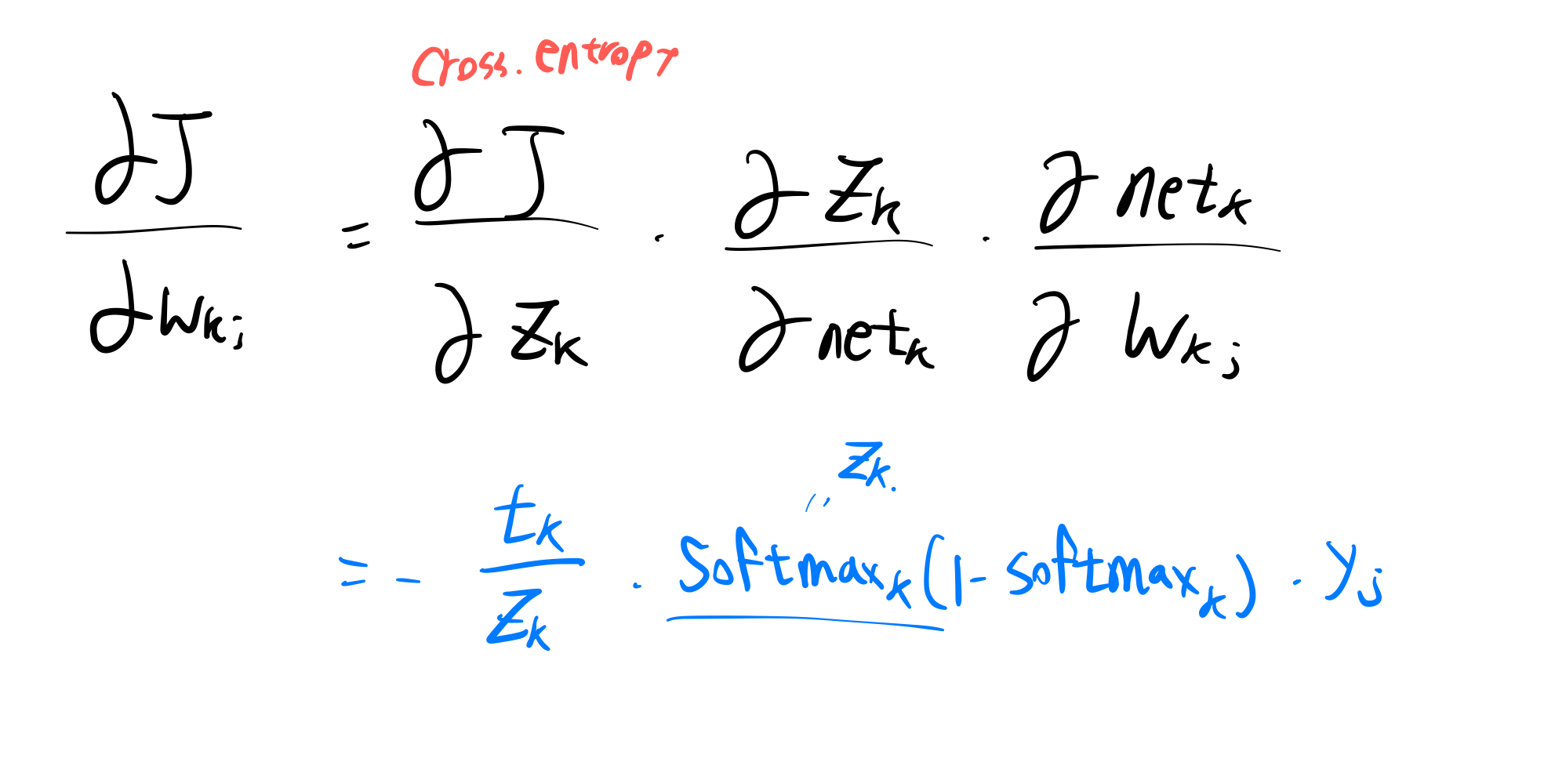
Cross Entropy
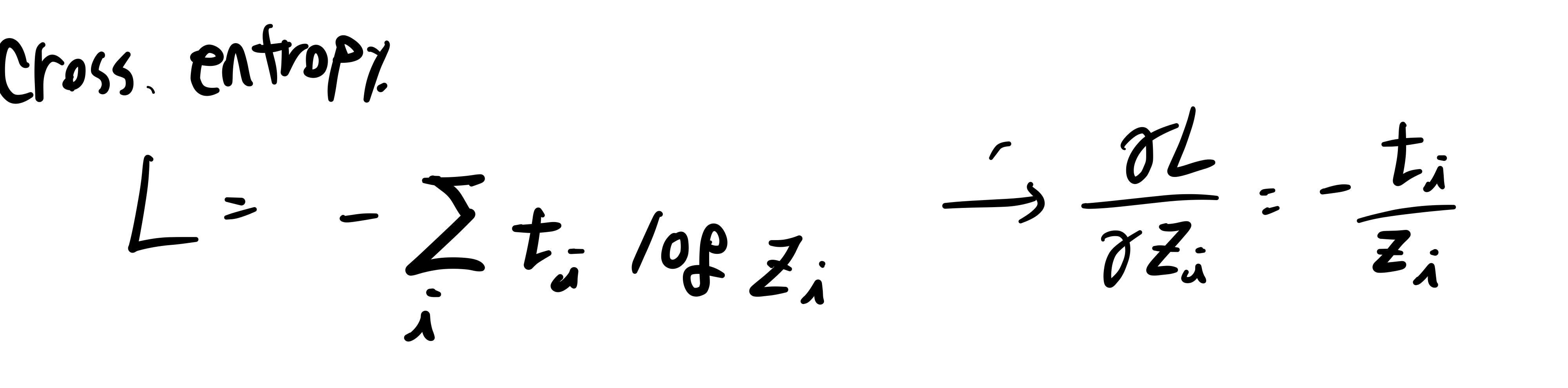
기존에는 ln이 붙어있지만,
우리의 목표는 최적화이니, 모든 항에 똑같이 곱해진 상수는 의미가 없습니다.
그래서 위와 같이 연산됩니다.
Softmax
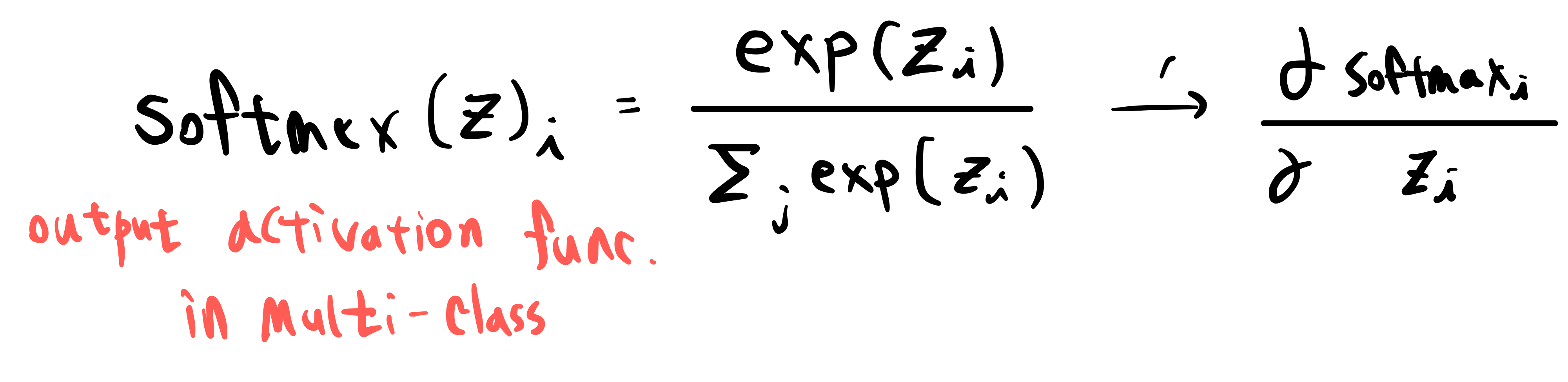
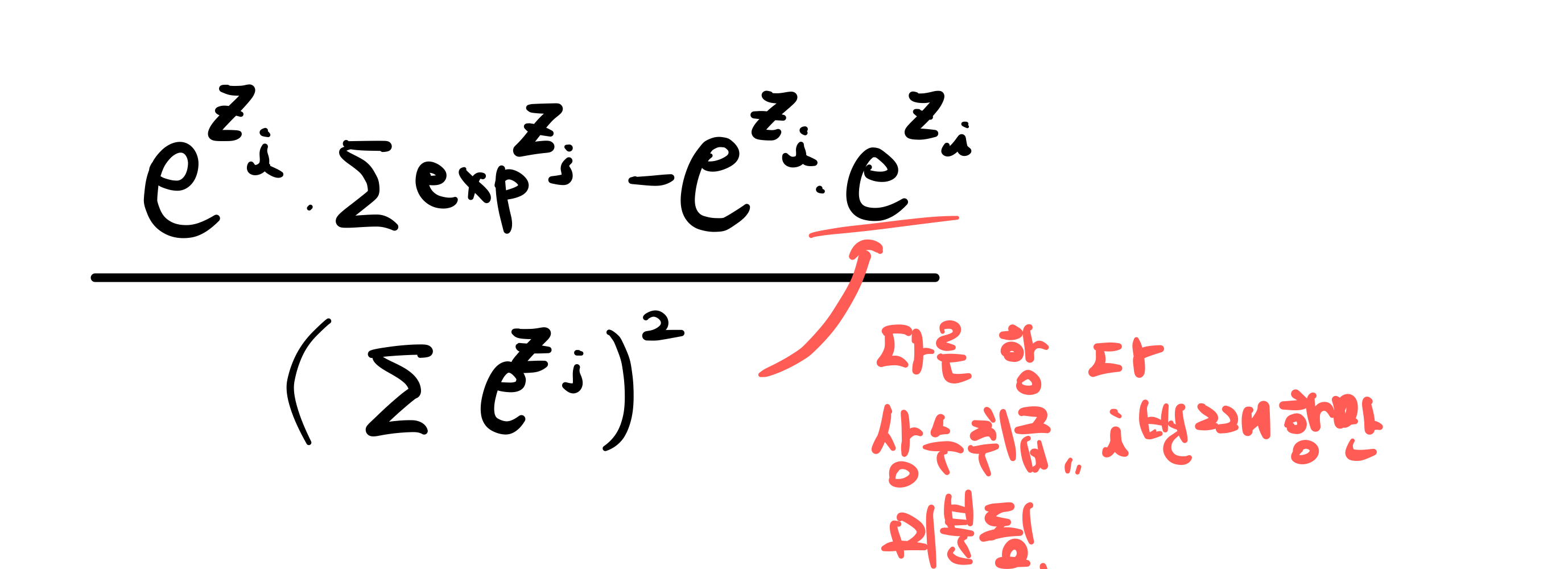
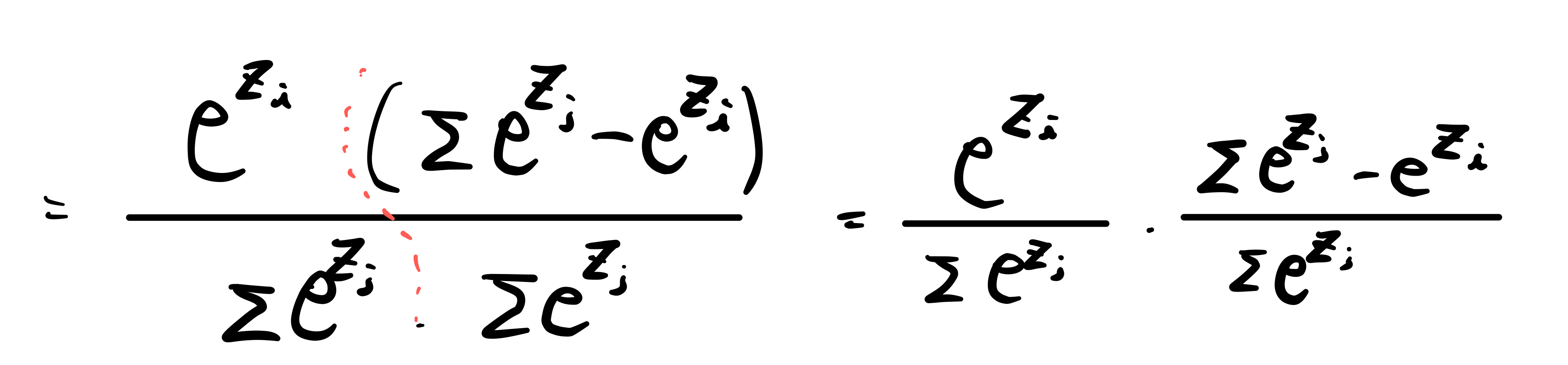
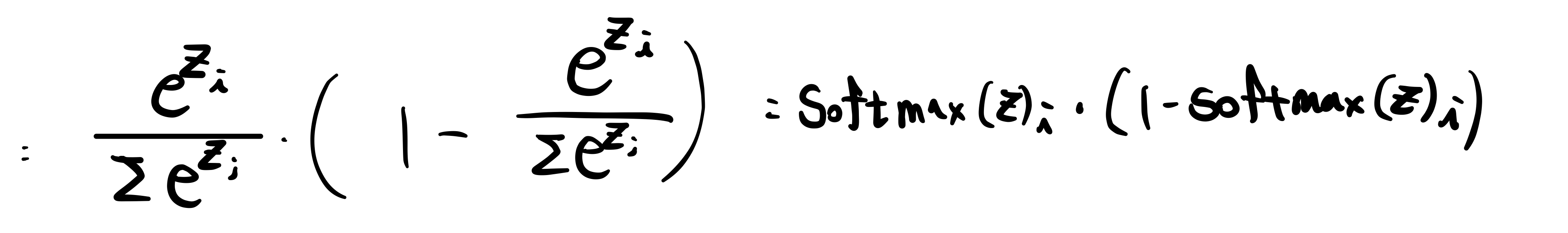
softmax 함수의 미분은 신기하게도 자기 자신들의 조합으로 이루어져 있습니다.
이것을 통해 우리는,
feed forward 과정에서 softmax function의 각 계산 결과들이 저장되어 있음을 알고,
그렇다면 backpropagation 중, 위 softmax function의 각 계산 결과들이 있다면 위와 같은 미분 결과로 미루어 볼 때, 우리는 더 많은 연산을 softmax에서는 해줄 필요가 없다는 것을 알아냈습니다.
Sigmoid
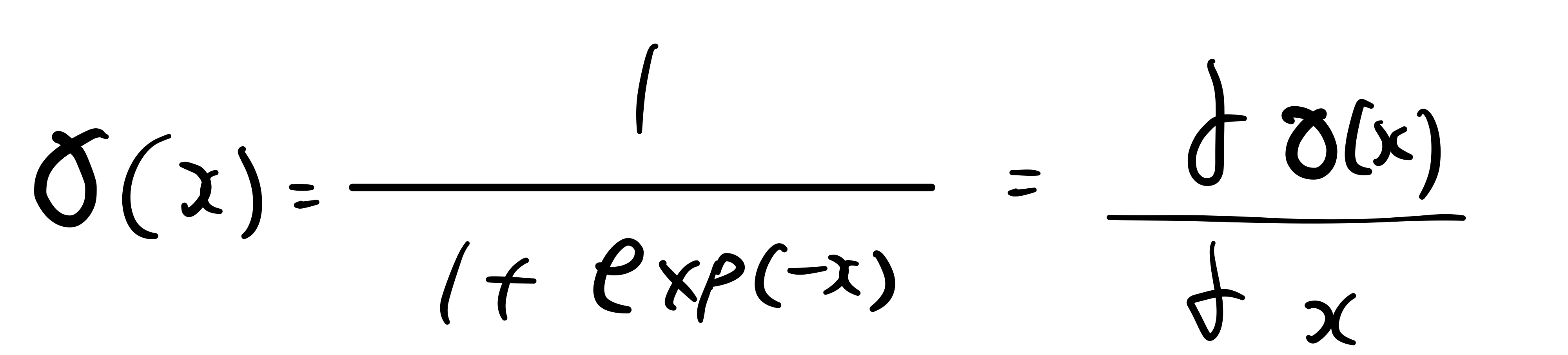
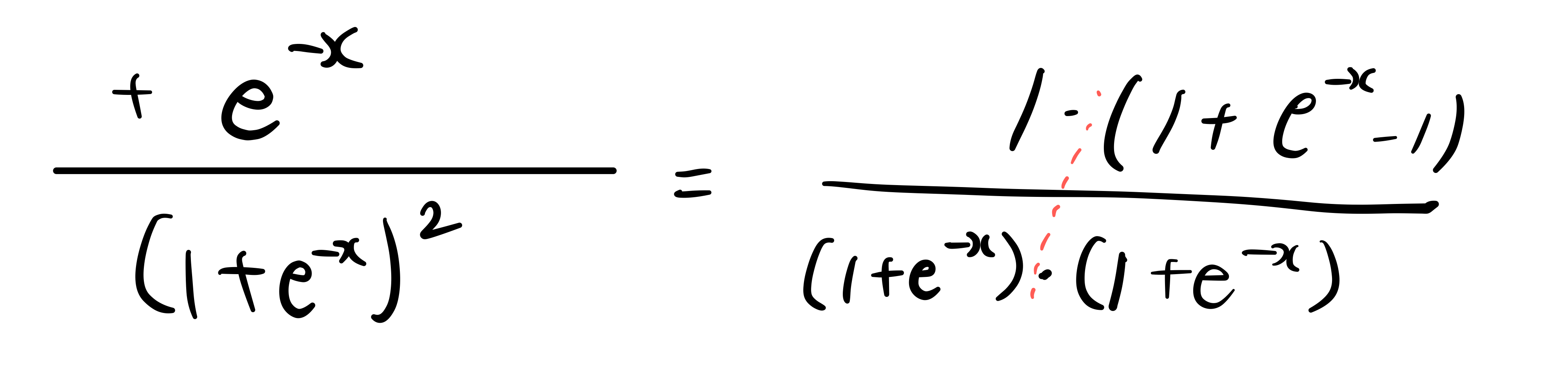
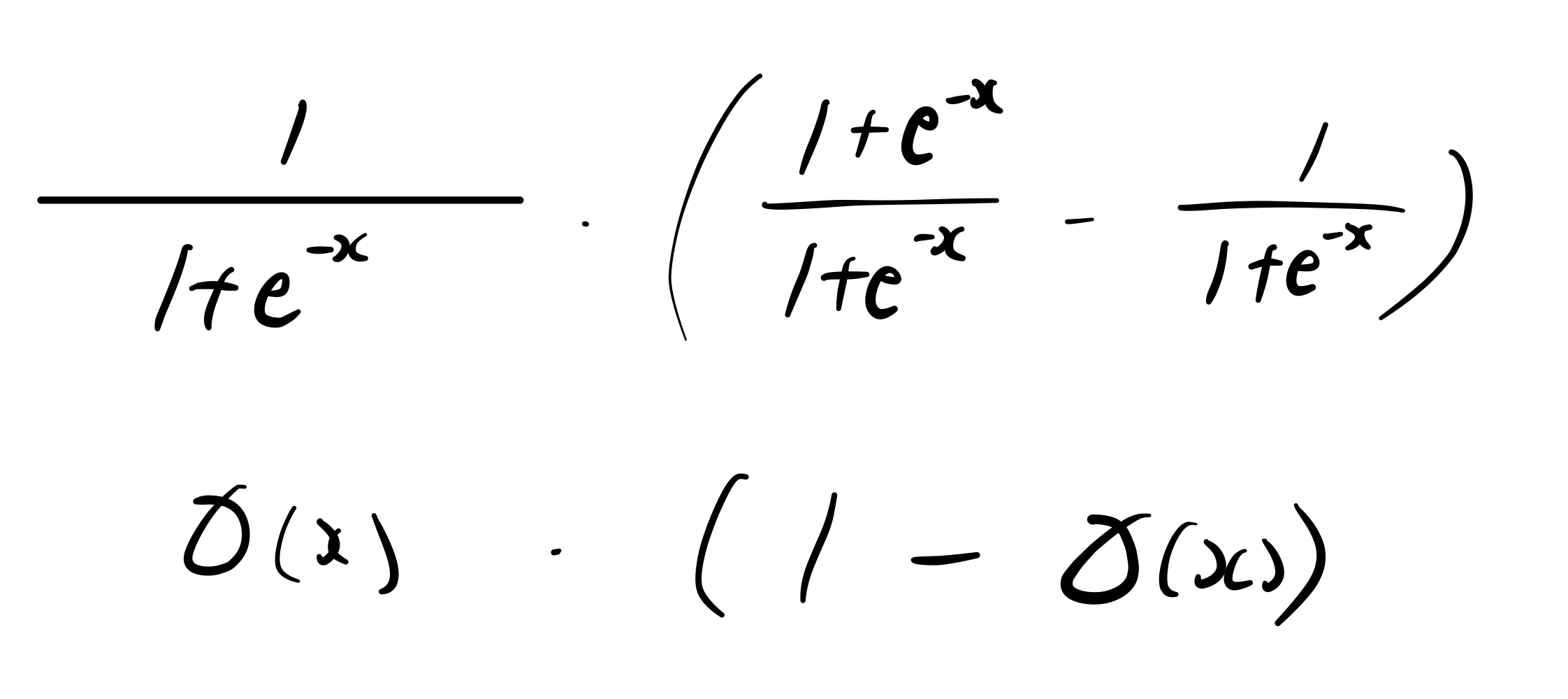
logistic sigmoid에 대한 연산은 위와 같이 이루어집니다.
softmax와 미분 form이 같은 양상입니다.
사실 softmax가 logistic을 scaling 해놓은 거라 당연한 결과이긴 합니다.
그리고, softmax와 마찬가지로 feedforward를 진행하면, 저장하려고 하면, hidden이든 output node이든 상관 없이 activation function이 통과된 값들을 저장해놓습니다.
그렇다면 바로 미분값을 구할 수 있다는 것입니다.
ReLU
요즘에 가장 많이 쓰이는 hidden node의 activation function입니다.
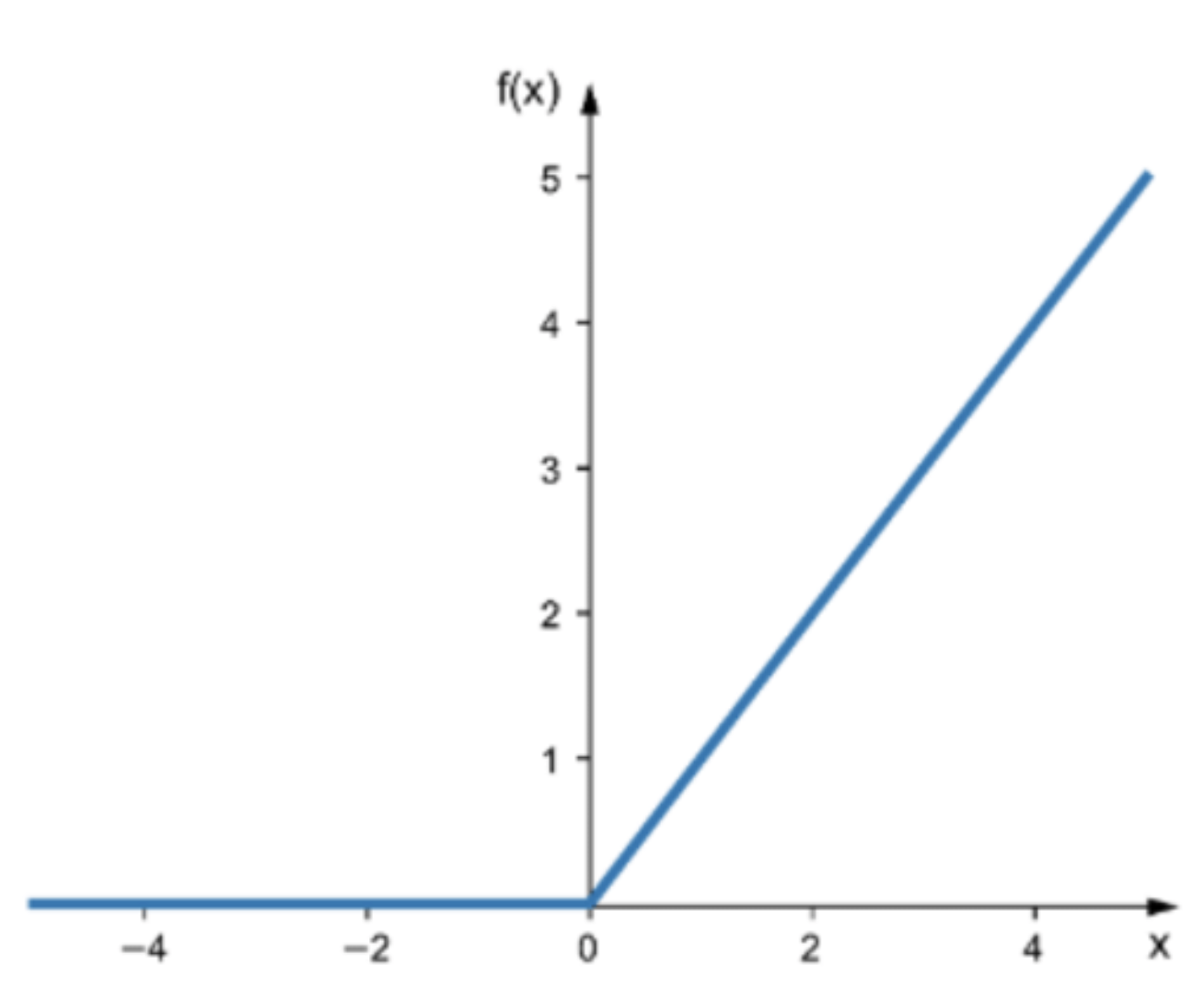
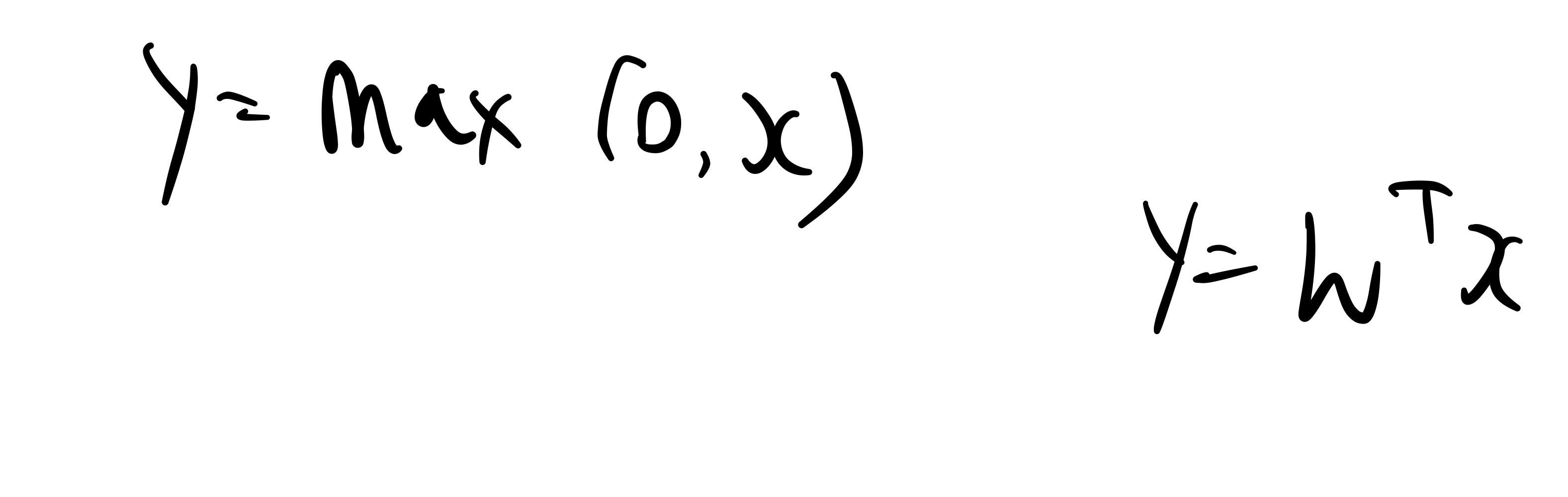
위와 같이 ReLU function이 있습니다.
그렇다면 이것은 net의 값이 x이므로, 위 수식과 같이 y로 표현가능합니다.
그렇다면 다시, 표현해봅시다.
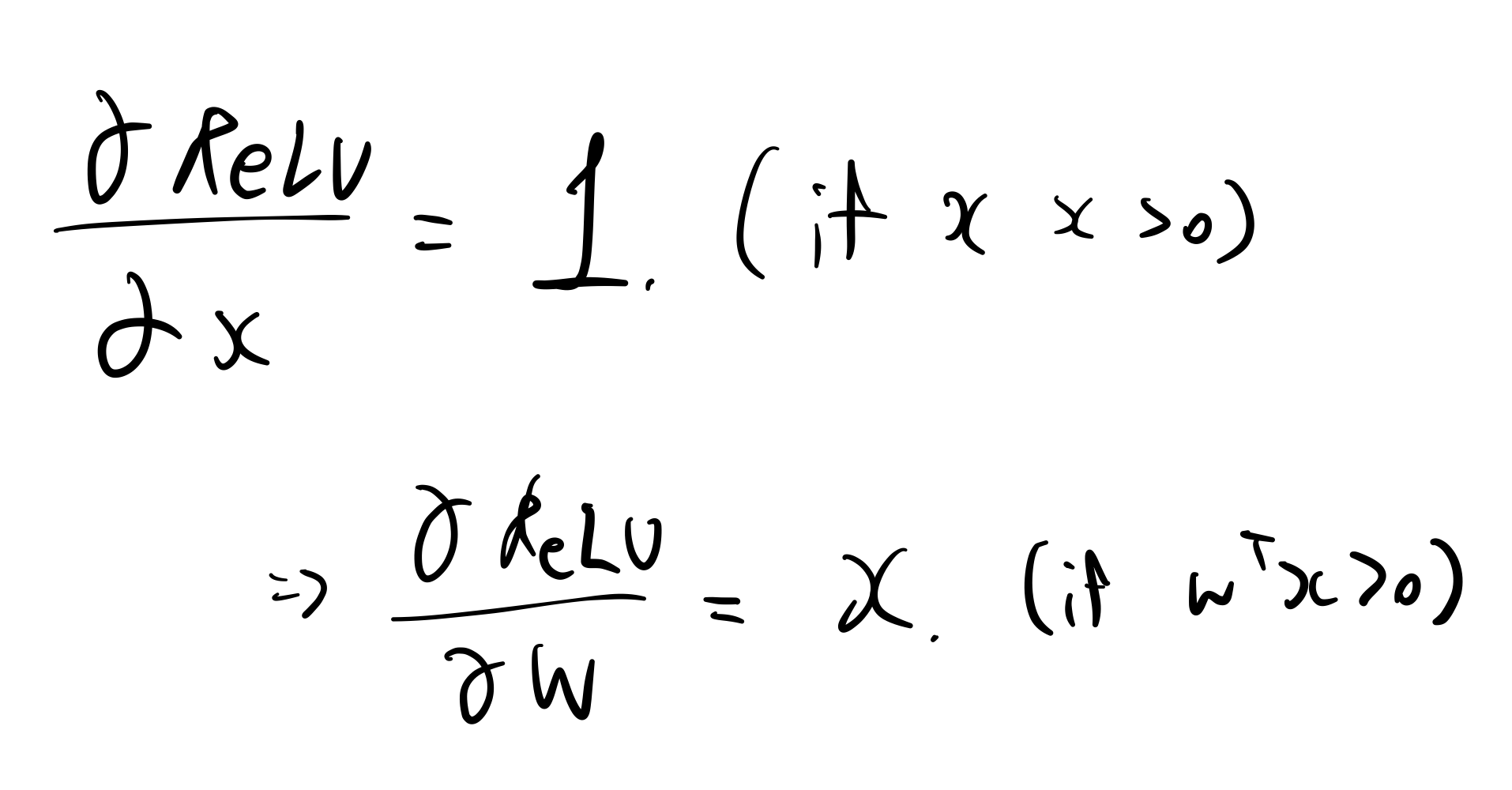
위와 같이 x가 0보다 큰 경우에는 1이다 라고 볼 수도 있습니다.
그런데, w에 대한 식이므로 w에 대해서 미분한다면 위와 같이 x로 나오기도 합니다.
둘 다 맞는 식입니다.
인자를 뭘로 볼 것인가에 따라 다릅니다.
1이거나 x이거나 x는 이미 전 단계에서 이미 다 들어오는 signal이기 때문에 추가 계산이 필요 없어집니다.
또 다른 activaiton function으로는, regression에서는 MSE가 잘 쓰입니다.
이렇게 미분 값들이 간단한 것이 우연일까요?
우리가 여기에서 쓰는 functions들은 모두 미분 값이 간단하기에 사용되는 것입니다.
미분 값이 복잡하다면 계산이 너무 많아지므로, 간단한 연산 수준의 function들로 neural network에서 쓰이는 것입니다.
그리고, 실제 간단한 예제로 살펴본다면, 위와 같은 연산이 이루어질 수 있습니다.

이러한 예시를 통해, chain rule을 적용하여, 우리가 더 쉽게, 다 아는 값들의 조합으로 이루어진 사칙연산을 그냥 하면 됩니다.
예를 들어, 이러한 값이 결국 0.1이 나왔다면,
현재 weight - 0.1하여 weight를 update하면 되겠습니다.

1. initial weight 값들을 randomize해라.
2. network이 feed forward를 타고 나가서 prediction을 진행. (y^을 구하는 과정)
3. tearch-output은 그저 실제 output을 의미. (supervised learning 과 같이 부르므로,, y값)
4. y^ - y를 각각의 units에 대해서 해라. (그 차이를 계산해라 정도)
5. hidden -> output weight update
6. input -> hidden weight update (계속해서 역방향으로 backpropagation 진행)
7. 전체 weight update해라.
8. 위 과정을 모든 examples들이 분류 되거나 stopping criterion을 만족시킬 때까지 해라.
Learning rate
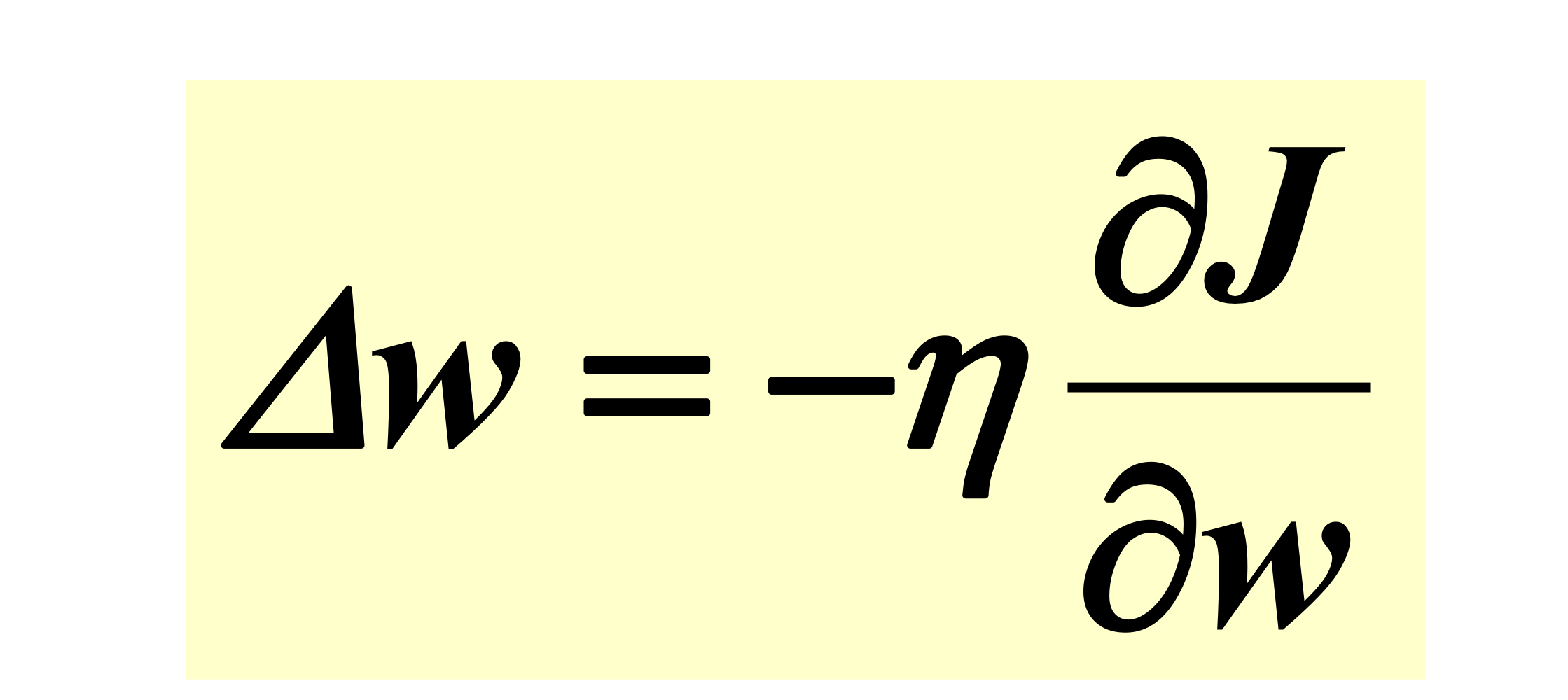
-> 우리가 만들어놓은 gradient의 값을 얼마나 반영할 것인가를 결정해주는 hyper parameter입니다.
=> 그대로 or 축소 or 확대
- Fixed Learning rate
- Adaptive Learning rate
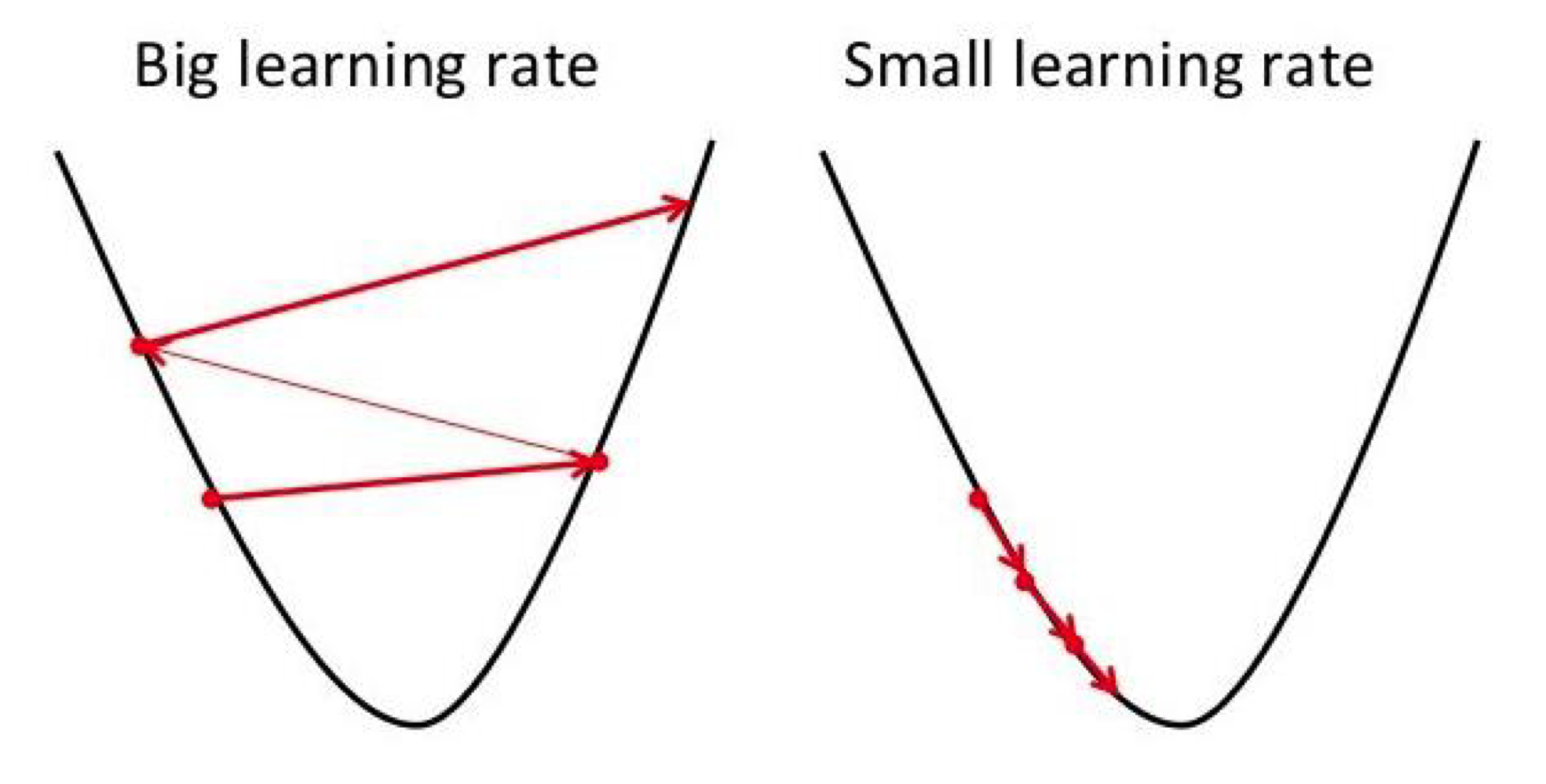
- Learning rate이 너무 지나치게 크면 solution을 지나갈 가능성이 있습니다.
- 적당히 크면 속도가 빠릅니다.
- 발산의 위험이 있습니다.
- 그러나 너무 지나치게 작으면 엄청나게 오래 걸리게 됩니다.
- 발산의 위험은 없습니다.
- 많은 시간이 소요됩니다.
=> 우리는 이 사실을 알 수 없습니다. 그러므로 learning rate의 존재는 너무나 중요합니다.
그래서 adaptive learning rate가 필요해집니다.
Local Optima Problem
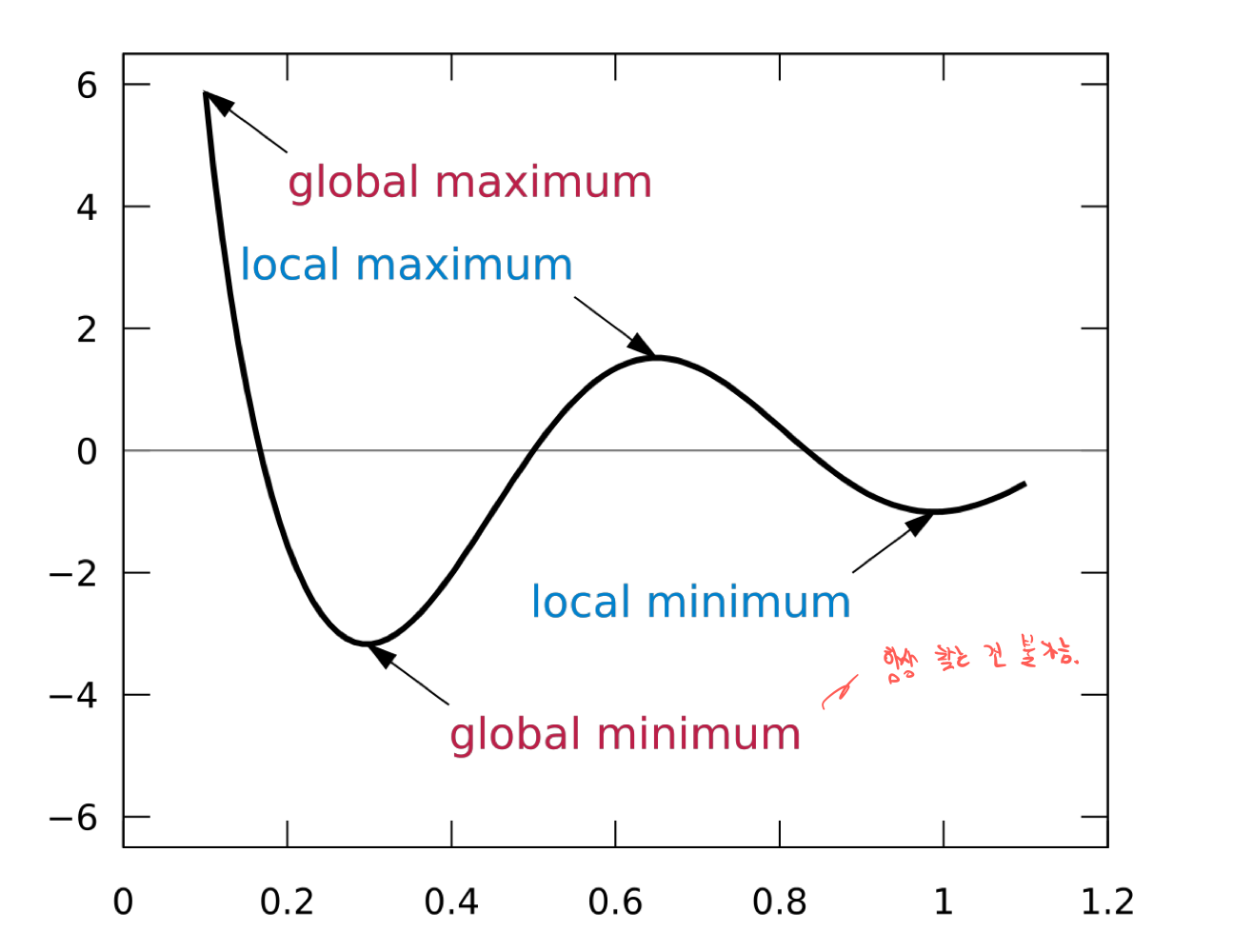
- Neural Netowork는 기본적으로 Gradient Descent를 사용하며, Gradient Descent는 Local Optimum을 찾는 개념입니다.
- Global인지 아닌지 증명조차 할 수 없습니다. Loss function이 너무 복잡하기 때문에.
- local optimum까지 가면 다행인 것입니다. (운이 좋아야)
- 안 갈 가능성도 있습니다.
- NN으로는 항상 Best solution까지 갈 수는 없습니다.
- 항상 답이 안 좋을 가능성을 항상 가지고 있습니다.
- 해가 안 좋은 데에서 멈출 가능성이 있다.
- 그나마 좋은 곳에서 멈추게 해야한다.
- 그 방법은?

- 좋은 initial weight 값을 갖는 것이 중요합니다.
- 그러나 적절한 방법은 없다고 보는 게 맞습니다.
- Stopping criterion
- 적당히 학습시켜 overfitting을 피하여 학습하다 적당히 멈추자.
- local optimum에 빠진 것과 overfitting이 매칭이 안 될 수 있지만, local optimum에 빠졌다는 것이, 안 좋은 solution에 overfitting 되었다고도 볼 수 있습니다.
- training-validation error
- Learning curves 를 그려서 training error, validation error 를 따로 주어 멈추게 할 수도 있다.
Summary
- Pros
- Great Performanc (High Accuracy)
- (Theoretically) slove any problems (High Capacity 가능)
- A generalized model (function을 통한 model, 이 NN을 이해하면 다른 model도 이해하는 데 편함)
- Cons
- Needs high computing power (input - hidden -output 연산 * # of training data * epochs)
- Overfitting (High Capacity, NN은 overfitting에 취약, DNN은 더 취약)
- Hyperparameter setting (# of Hidden nodes, # of Hidden layers, learning rate, regularization)
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [Deep Learning] Generating two classification models for MNIST dataset with Keras sequential/functional API (0) | 2023.04.05 |
|---|---|
| [Deep Learning] Generating regression model for California housing dataset with Keras functional API (0) | 2023.04.05 |
| [Deep Learning] Backpropagation (0) | 2023.03.30 |
| [Deep Learning] Feedforward (0) | 2023.03.27 |
| [Deep Learning] - MLP(Multilayer Perceptron) (0) | 2023.03.26 |








