🧑🏻💻 주요 정리
NLP
Word Embedding
배경 지식
What is the Embedding?
Embedding이란 무엇일까요?
우리는 input으로 들어온 sentence인 sequence를 vector화 해서 계산해야합니다.
이 때 필요한 것이 바로 Word Embedding입니다.
즉, 문자를 숫자로 표현하는 것입니다.
우리가 CNN에서 image를 처리할 때, [28 x 28 x 3 x 256] 정도의 vector가 필요합니다.
이때, hidden layer에서 hidden representation을 뽑아내는 과정을 하죠.
즉, vector 값에서 의미있는 representation을 뽑아내는 것입니다.

Embedding도 마찬가지 입니다.
위와 같이 우리가 input으로 넣는 값을 vector로 바꾸어 연산하는 것입니다.

위와 같은 자료를 봅시다.
단어를 위와 같이 3차원 공간에 mapping합니다.
vector[Queen] = vector[King] - vector[Man] + vector[Woman] 과 같은 연산을 통해
단어를 embedding or representation으로 바꾸며 이러한 연산이 가능하다는 것을 알게 되었습니다.
그럼 조금 더 살펴볼까요?
NLP 분야는 다음과 같은 분야로 넓게 쓰이며 아래와 같은 관련 메소드들이 존재합니다.
1. Word Similarity
Classic Methods : Edit Distance, WordNet, Porter's Stemmer, Lemmatization using dictionaries
- Easily identifies similar words and synonyms since they ocuur in similar contexts.
- Stemming (thought -> think)
- Inflections, Tense forms
- eg. Think, thiught / ponder, podering
- Plane, Aircraft, Flight
2. Machine Translation
Classic Methods : Rule-based machine translation, morphological transformation
3. Part-of-Speech and Named Entity Recognition
Classic Methods : Sequential Models (MEMM, Conditional Random Fields), Logistic Regression
4. Relation Extracting
Classic Methods : OpenIE, Linear programming models, Bootstrapping
5. Sentiment Analysis
Classic Methods : Naive Bayes, Random Forests/SVM
- Classifying sentences as positive and negative
- Building sentiment lexicons using seed sentiment sets
- No need for classifiers, we can just use cosine distances to compare unseen reviews to known reviwes.
-> 단어간 distance를 고려하여 계산한다.
=> L1 distance는 비슷할 수록 값이 적어진다. L2 distance는 유클리디안을 사용하는 풀이이다. cos distance는 비슷할 수록 각도 차이를 작게 하여 계산하는 방법이다.
6. Co-reference Resolution
- Chaining entity mentions across multiple documents
- can we find and and unify the multiple contexts in which mentions occurs?
7. Clustering
- Words in the same class naturally occur in similar contexts, and this feature vector can directly be used with any conventional clustering algorithms (K-Means, agglomerative, etc..).
- Human doesn't have to waste time hand-picking useful word features to cluster on.
8. Semantic Analysis of Documents
- Build word distributions for various topics, etc.
위와 같은 엄청난 vectors들을 어떻게 만들까요?
-> Similar words have silmilar representation !
Lower-dimension vector representations for words based on their context
- Co-occurrence Matrix with SVD
- Word2Vec
- Global Vector Representations (Glove)
- Paragraph Vectors
Co-occurrence Matrix with Singular Value Decomposition
data에 대해서 Co-occurrence 하는 단어에 대해서 같이 표현합니다.
해당 과정을 통해서 테이블을 얻습니다.
그리고 Vector의 차원에서 의미 있는 dimension만 봅니다.
이 과정을 Dimension Reduction using SVD라고 합니다.
SVD는 vector의 차원입니다.
많은 계산량 때문에 이 과정을 많이 사용하진 않습니다.
Word2Vec
- Represent each word with a low-dimensional vector
- Word similarity = vector similarity
- Key idea : Predict surrounding words of every word
- Faster and can easily incorporate a new sentence/document or add a word to the vocabulary
Represent the meaning of word
- Two basic neural network models:
- Continuous Bag of Word(CBOW) : use a window of word to predict the middle word.
- Skip-gram (SG) : use a word to predict the surrounbding ones in window.
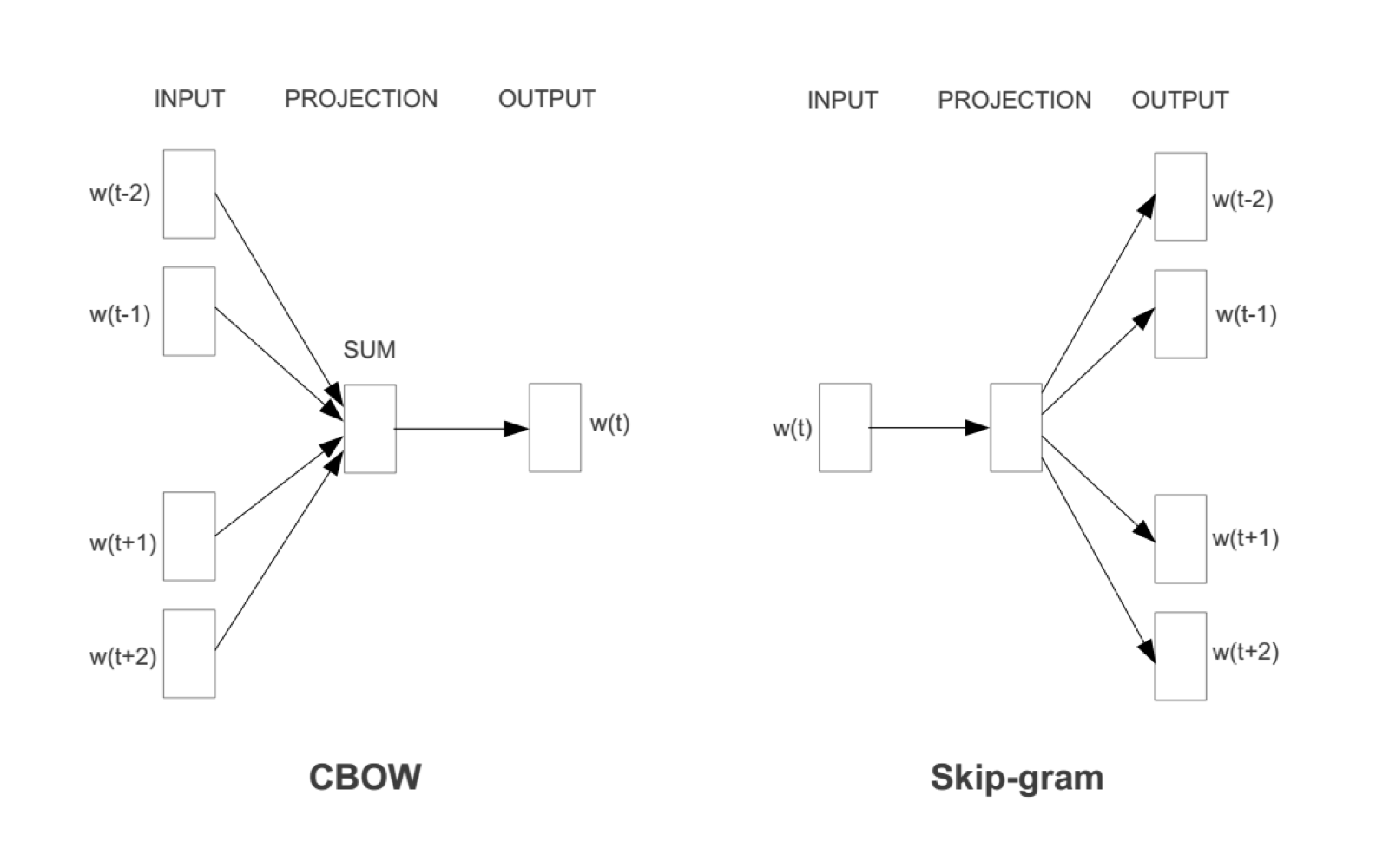
위와 같은 차이를 보인다.
이 차이에 대해 다음 시간부터 자세히 알아보겠습니다.
'Artificial Intelligence > Natural Language Processing' 카테고리의 다른 글
| [NLP] Word Embedding - Word2Vec (0) | 2023.03.27 |
|---|---|
| [NLP] Word Embedding - Skip Gram (0) | 2023.03.27 |
| [NLP] Word Embedding - CBOW (1) | 2023.03.27 |
| [NLP] Overview NLP (0) | 2023.03.21 |
| [NLP] Introduction to NLP (0) | 2023.03.21 |