🧑🏻💻 주요 정리
NLP
Word Embedding
Modeling Sequence
MLP
CNN
RNN
Language Modeling
Autoregressive Language Modeling
Machine Translation
Seq2Seq
Attention
Transformer
배경 지식
NLP를 배우기 위해선 다음과 같은 구성요소들을 알아야 합니다.
함께 알아봅시다.
Word Embedding
컴퓨터는 인간의 언어를 알아듣지 못 합니다.
그래서 우리는 이 문자들을, 이 Semantic 단어를 어떤 숫자로 mapping 시켜주어야 합니다.
이를 word embedding 작업이라고 부릅니다.
Each word can be represented as a vector based on the Distributed hypothesis.
Modeling Sequences
모든 text는, 즉 모든 자연어는 각각 다른 문장 길이, 다른 단어의 길이를 가지고 있습니다.
이러한 sequence들을 우리가 modeling하는 작업이 필요해집니다.
이를 modeling sequences라고 부릅니다.
더 자세히 알아봅시다.
MLP
먼저, sequence의 length를 바꿔보면 어떨까요?
MLP를 사용한다는 것은 고정된 Length를 사용한다는 것이기 때문에,
다음과 같은 issue가 있습니다.
- We cannot reuse the same network for handling sequences in different length
- It is because the network parameter bounds the length of the sequences
그렇다면 우리는 어떤 Length를 선택하는 게 바람직할까요?
1. 제일 짧은 것
2. 제일 긴 것. 남은 것은 padding (공백)
이것은 과제에 따라 다를 것입니다.
CNN
CNN을 사용하여 sequence의 길이를 바꾸면 어떨까요?
We can resue the same network by sliding convolution filters over the sequence.
CNN은 Computer Vision에서와 같이,
이를 테면 28 x 28 크기의 고정된 length는 잘 처리하지만, 변화하는 것은 잘 처리하지 못 합니다.
CNN을 사용하면 다음과 같은 issue가 발생합니다.
- The hidden representation grow with the length of the sequence.
- The receptive field is fixed.
그렇다면, 어떤 것이 가장 효과적인 방법일까요?
실제 NLP 분야에서 중요한 것은 바로,
Recursion
입니다.
반복을 사용하면 다음과 같은 이점이 존재합니다.
- A model that reads each input one at a time.
- Parameters can simply be reused (or shared) for each input in a recurrent computation.
여기서 RNN을 채택합니다.
RNN을 통해 sequence pattern 분석이 가능하고, sequence의 길이 만큼 입력이 들어갑니다.

Language Modeling
A language model captures the distribution over all possible sentences
특정 단어 input에 대해 그 다음 단어에 대하여 예측하여 output을 내놓습니다.
- input : a sentence
- output : the probability of the input sentence
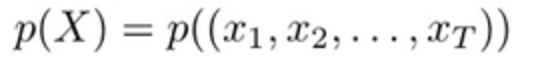
여기서 확률이 출력으로 나온다는 것은 scoring이 가능한 것입니다.
즉, 우리가 문자를 숫자로 나타낼 수 있게 되었다는 말이죠 !!!
이는 우리가 sequenct generating을 하는 데 있어 큰 영향력을 가져옵니다.
여기서 조금 더 나아가면,
Autoregressive Language Modeling
The distribution over the next toen is based on all the previous tokens.
회귀적으로 앞에서부터 차근차근 확률을 계산하는 것입니다.
이전 단어로 다음 단어를 예측하는 Model입니다.
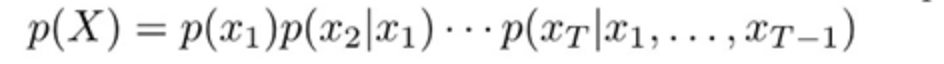
위 식을 토대로 살펴보면, 조건부확률분포와 일치하는 것을 알 수 있습니다.
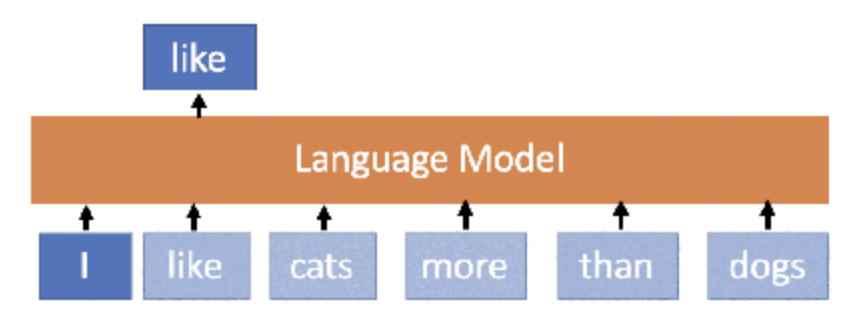
위와 같이 I가 입력 되었을 때, like가 올 확률을 계산하는 것입니다.
Machine Translation
Machine Translation is a task of translating a sentence in one language to another.
이 model은 모든 generation에 포함되는 model입니다.
Seq2Seq model이며 encoder와 decoder 모두를 사용하는 model입니다.
Sequence to Sequence Learning
위 모델의 Encoder, Decoder는 다음과 같습니다.
- Encoder : Encodes the source sentence into a set of sentence representation vectors.
- Decoder : Generates the target sentence conditioned on the source sentence.
간단하게 보면, input sentence를 vector로 바꾸는 것이 Encoder, 이 vectors들을 가지고 target sentence, 즉 원하는 결과값이 나오도록 하는 것이 Decoder입니다.
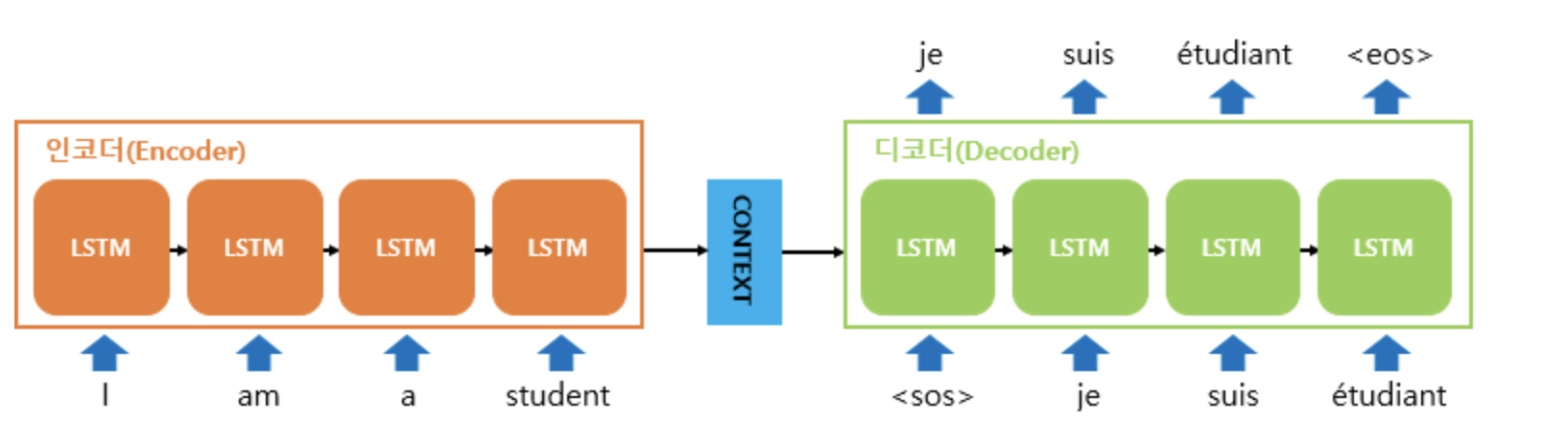
Attention Mechanism
Attention focus on a relevant part of the source sentence for predicting the next target token.
Attention 에서는 RNN Encoder와 RNN Decoder를 사용하여 조금 더 관련 있는 값들을 보고자 합니다.
단어들 입력을 한 번에 넣고, output도 하나씩 나옵니다.
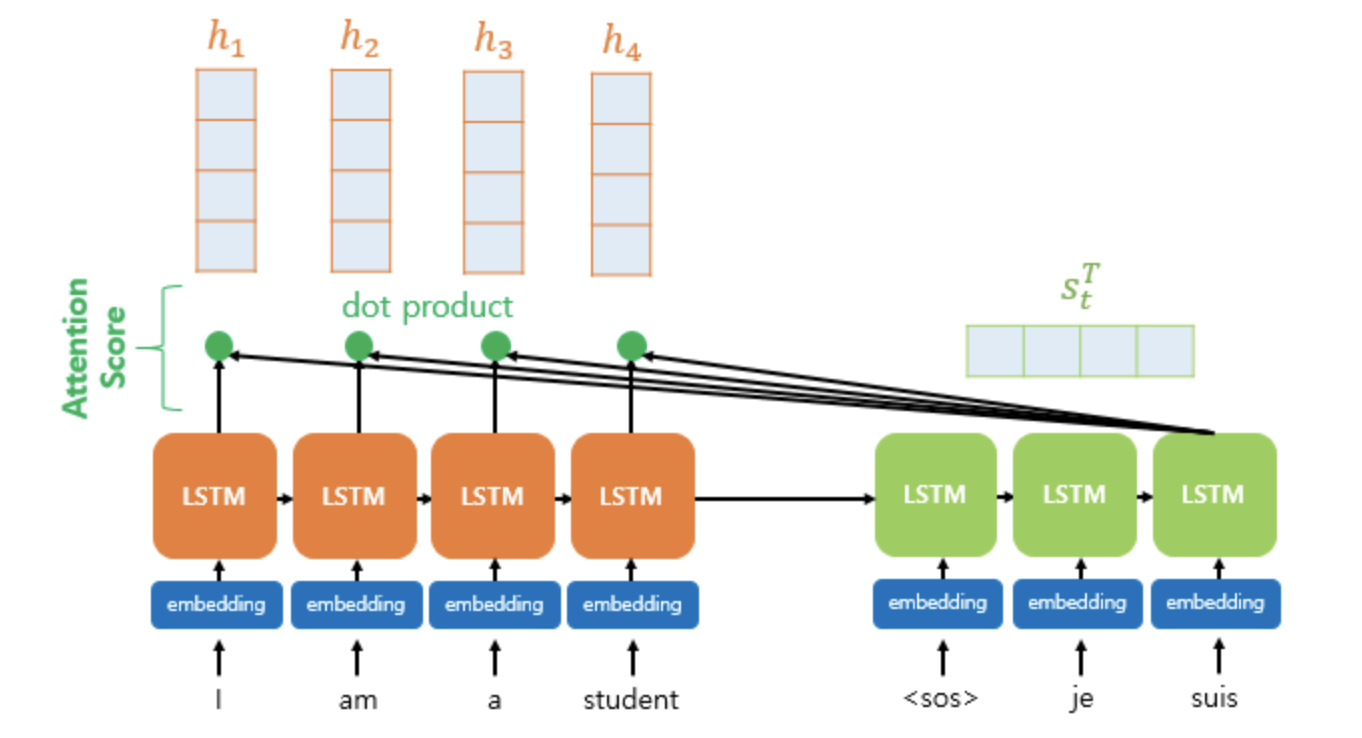
단어 개수 4개 짜리 sentence를 단어의 개수만큼 4번 봐서 결정한다.
그러나 transformer에서 이것은 한 번으로 가능합니다.
Transformer
<paper : https://arxiv.org/abs/1706.03762 >
Attention Is All You Need
The dominant sequence transduction models are based on complex recurrent or convolutional neural networks in an encoder-decoder configuration. The best performing models also connect the encoder and decoder through an attention mechanism. We propose a new
arxiv.org
해당 논문을 통해 transformer가 도입되었습니다.
배경은
- No more RNN or CNN modules
- No more sequential processing
입니다.
이 transformer는 CNN 분야, 이미지 인식 분야에서도 활발하게 쓰이고 있습니다.
이는 Seq2Seq model이지만 attention만 가지는 model이라고 볼 수 있습니다.
이 transformer를 여러겹 쌓아서 성능을 향상시킬 수도 있습니다.
Transformer가 나오고 여러 가지 기술들이 많이 발전되었습니다.
- GPT-1
- BERT
- XLNet
- ALBERT
- RoBERTa
- Reformer
- T5
2017년에 개발된 이 transformer는 더 빠른 성장을 가져왔습니다.
2023년인 현재도 계속해서 쓰이고 있습니다.
BERT
Improve performance of various NLP tasks recently
Learn through masked language model task and next sentence prediction task
Transformer의 encoder 부분이라고 볼 수 있습니다.
GPT-2
Language Models are Unsupervised Multitask Learners
Transformer의 decoder부분이라고 볼 수 있습니다.
더 많이 쌓고 학습을 많이 시킨 것이 지금의 많이 상용화 되어있는 ChatGPT3, ChatGPT4라고 볼 수 있습니다.
GPT3는 GPT2 보다 parameter 개수로만 봐도 100배가 차이 납니다.
그리고, GPU 개수도 1000 ~ 10000배 차이납니다.
위 기술들은 다음과 같은 분야에 사용되겠습니다.
- Machinbe Reading Comprehension
- Document Summarization
- Extractive summarization
- Abstractive summarization
- Neural Conversational Model
'Artificial Intelligence > Natural Language Processing' 카테고리의 다른 글
| [NLP] Word Embedding - Word2Vec (0) | 2023.03.27 |
|---|---|
| [NLP] Word Embedding - Skip Gram (0) | 2023.03.27 |
| [NLP] Word Embedding - CBOW (1) | 2023.03.27 |
| [NLP] Introduction to Word Embedding (0) | 2023.03.26 |
| [NLP] Introduction to NLP (0) | 2023.03.21 |