🧑🏻💻용어 정리
Character-level Language Model
Auto regressive model
LSTM
GRU
Character-level Language Modeling task
- 자연어 처리에서의 기본 task인 language model이라는 task에 대해서 살펴봅니다.
- 주어진 Example training sequence에 대해 Input Layer의 값을 Input chars에 대해서 one-hot vector로 구성합니다.
- 그렇다면 입력 vector를 현재 time step의 x 입력 vector로 받게 되고 그 전 time step에서 넘어오는 ht-1이라는 추가적인 입력 vector를 받아서 현재의 Hidden state vector ht를 계산하게 됩니다.
- 참고로, t가 1일 경우 이전 time step의 Hidden state vector가 존재하지 않게 되는데, 이 경우 h t-1 자리 혹은 h0 자리에 0 Vector를 입력으로 주게됩니다.
- 이 매 time step 마다 계산된 Hidden state vector를 입력으로 사용하여 각 time step 기준으로 그 다음에 나타나야 할 character를 예측해야하기 때문에 vocabulary 상의 한 단어로 예측해야 하는 것입니다.
- n개의 class 중에 하나의 class를 예측하는 multi-class classificaiton 을 수행해야 합니다.
- linear transformation을 적용하여 vector들로 만듭니다.
- 이 vector를 logit 값으로 사용하여 softmax layer를 통과하고 class에 대응하는 probability vector를 얻게 됩니다.
- ground truth cahacter 혹은 class 정보를 사용하여 각 time step의 예측된 probability vector에 ground truth class를 기준으로 하여 softmax를 적용해 줌으로써 Network 전체를 학습하게 됩니다.
- trainable parameter와 각 time step에서 사용된 linear transformation matrix 등이 gradient descent를 통해 학습이 진행되게 됩니다.
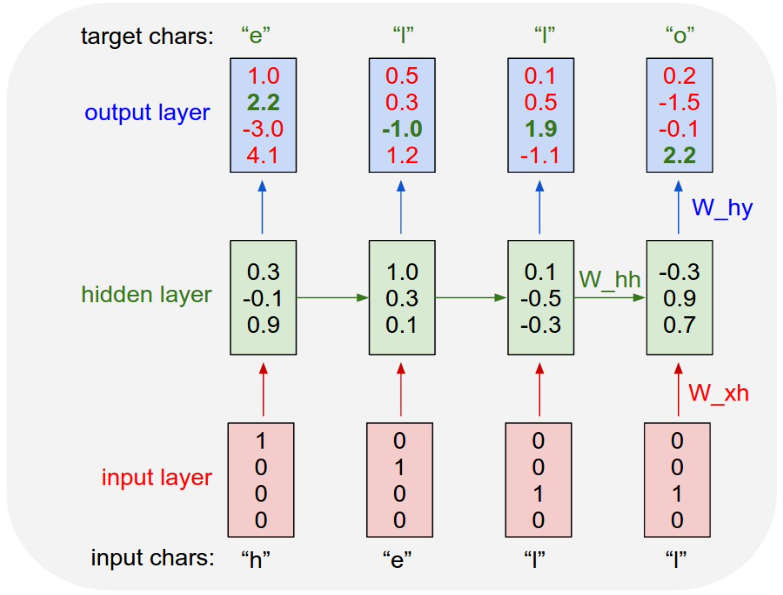
-> 각 time step 마다 다음에 나타날 Character를 예측하는 모델.
이와 같이 학습이 완료된 model을 test하는 경우에는,
test time에 입력으로 주게 되면 학습이 완료된 model에서 나온 예측된 softmax 확률 vector가 결과로 나올 것입니다.
거기서 가장 큰 확률을 부여받은 character를 다음에 나타날 character로 예측하게 됩니다.
그리고 예측에서 끝나는 것이 아닌, 예측된 character를 그 다음 time step에서 실제로 나타난 character라고 생각해서 그 다음 time step의 RNN에 입력으로 제공해 주게 됩니다.
우리는 연쇄적으로 최초의 time step에서 character 하나만 입력으로 주게 되면 이 character의 예측된 Sequence를 무한정 길이만큼 만들어 줄 수 있게 됩니다.
model의 output이 그다음 time step의 입력으로 주어지는 이러한 방식의 예측 model을
Auto regressive model
이라고 부릅니다.
이 기술은 논문, 코드, 소설 등에서 다양하게 사용됩니다.
심지어 프로그래밍 언어의 코드에서 indentation 또한 효과적으로 학습할 수 있습니다.
위와 같은 Original 구조, vanilla 구조를 실직적으로 많이 사용하지는 않습니다.
vanilla 사용 중, gradient가 vanishing 되거나 혹은 gradient가 폭발적으로 늘어나게 되어 학습이 불안정해지는 부작용이 일어나게 됩니다.
RNN의 입출력 setting은 동일하게 유지하되, gradient vanishing이나 exploding 문제를 좀 효과적으로 해결한
long short term memory(LSTM) 혹은 gated recurrent unit (GRU)
와 같은 특정한 구조의 RNN 모델을 많이 사용합니다.
LSTM
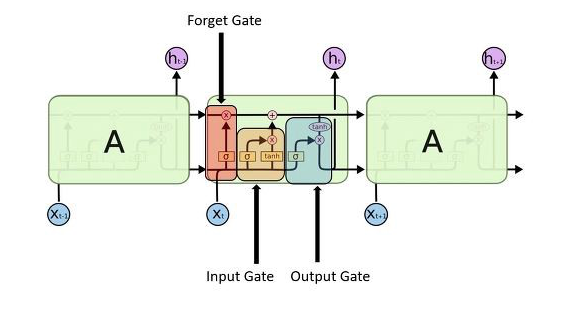
- 기본적인 입력 Setting은 RNN 기본 구조와 동일하게 매 time step 마다 그때그때 주어지는 입력 신호를 받게 됩니다.
- 그리고 LSTM cell의 output vector는 그 다음 time step의 LSTM cell에 입력으로 주어지게 됩니다.
- LSTM에서 Hidden state vector는 cell state라 불리는 ct라는 vector와 더불어 c t-1이라는 vector들을 잘 가공해서 h t h t-1만들게 됩니다.
- 다음과 같은 구조를 가집니다.
Seq2seq
- 문장을 읽어들일 때, 각 단어별로 time step에 해당 vector가 입력으로 주어져서 RNN module이 매 time step 마다 이 정보를 잘 처리하고 축적하는 과정을 거치게 됩니다.
- 마지막 time step에서 나온 Hidden state vector ht는 기본적으로 주어진 입력 Sequence에 있는 모든 단어들의 정보들을 잘 축적한 vector입니다.
- 질문, 즉 입력을 받는 것이 Encoder, 답을 생성하는 것이 Decoder입니다.
- language modeling에서의 auto regressive setting에서처럼 다음 단어로서 예측한 단어를 다음 time step에 입력으로 줘서 또 그 다음 단어를 예측하게 됩니다.
- end of sentence token이 예측될 때까지 생성 과정을 반복적으로 수행하게 됩니다.
- encoder와 decode는 parameter가 공유되지 않는 별개의 RNN을 사용하는 경우가 일반적입니다.
- 입력이 짧든 길든, 매 time step 마다 생성되는 RNN의 각 time step의 Hidden state vector는 같은 Dimension으로 이루어져 있어야 한다는 제약조건이 있습니다.
- 그래야만 output vector가 다시 Input vector로 사용 될 수 있습니다.
- 정보는 계속 축적되어도 같은 dimension으로 이루어진 vector 내에 정보를 넣어야 한다는 제약 조건이 있습니다.
- 그래서, bottleneck problem인 병목현상을 해결하고자 Attention Model이 제안됩니다.
Seq2seq and Attention Model
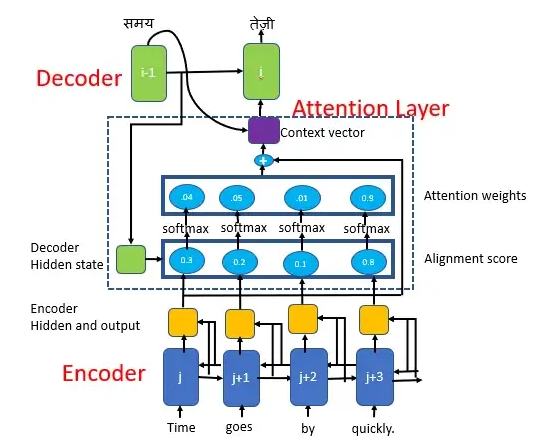
- Decoder는 Encoder의 Hidden state vector만을 입력으로 받는 것이 아닌, 입력과 더불어 decoder의 각 Time step에서 encoder에서 나온 여러 단어별로 Encoding된 Hidden state vector 들 중에 필요로 하는 vector 들을 가져가서 time step의 예측에 직접적으로 활용할 수 있는 것이 attention model의 핵심 Idea입니다.
- 가장 관련성이 높은 encoder의 hidden state vector를 가져가서 사용하게 됩니다.
- start sentense token이 time step 1에서 주어집니다.
- Hidden state vector를 가지고 바로 Output 단어를 예측하는 task를 수행하는 입력으로 사용합니다.
- decoder 의 각 Time step 마다 encoder의 Hidden state vector 유사도를 계산하게 됩니다.
- 내적을 통해 유사도를 하나하나의 scalar 값을 통해 계산합니다.
- encoder의 hidden state vector들과 특정 decoder의 hidden state vector와의 내적값들을 softmax를 통과시켜서 어떤 확률 Vector를 얻게 됩니다.
- 높은 확률의 것을 가중치로 반영하여 Output을 만들게 됩니다.
- 기계 번역 Task의 성능을 올렸습니다.
- gradient vanishing problem을 잘 해결해줍니다.
- Backpropagation에서 추가적인 attention gradient path가 생겨서 더 학습에 용이하게 됩니다.
Advanced Attention Techniques
- Gating(using sigmoid instead of softmax)
- Self-attention (serving a general-purpose sequence or set encoder)
'Artificial Intelligence' 카테고리의 다른 글
| [Self-Supervised Learning and Large-Scale Pre-Trained Models] Part 6 (0) | 2023.01.25 |
|---|---|
| [Transformer] Part 5 (1) | 2023.01.25 |
| [Seq2Seq with Attention for Natural Language Understanding and Generation] Part 4 - 1 (0) | 2023.01.25 |
| [Ensemble Learning] part 6 - 2 (0) | 2023.01.20 |
| [Ensemble Learning] part 6 - 1 (0) | 2023.01.20 |