Paper Review
제목 : An Images is Worth 16 x 16 Words: Transformers For Image Recognition At Scale
저널 : ICLR 2021
저자 : Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby
일시 : 3 Jun 2021
연구 : Google Research, Brain Team
해당 논문 리뷰는 위 링크의 논문을 리뷰한 것입니다.
오류나 내용 정정 요청에 대한 문의는 언제나 환영입니다.
Background
1. The Shortcomings of CNNs
전통적으로 이미지 처리에는 Convolutional Neural Networks (CNNs)가 주로 사용되어왔습니다. CNNs는 이미지의 지역적 특징을 잘 파악하며, 이를 계층적으로 추상화하여 이미지 분류나 객체 탐지 같은 태스크에서 좋은 성능을 보여줍니다. 그러나 CNNs는 고정된 receptive field를 갖는 필터를 사용하기 때문에 전체 이미지의 긴 거리 의존성이나 복잡한 패턴을 완벽하게 파악하는데 한계가 있습니다.
2. Introduction of Transformers in NLP
Transformer 아키텍처는 처음에는 자연어 처리(NLP) 문제를 위해 고안되었습니다. 'Attention is All You Need'라는 논문에서 소개된 Transformer는 self-attention 메커니즘을 활용해 문장의 각 단어가 다른 단어와 어떻게 관련되어 있는지를 학습합니다. 이 구조는 전체 문장의 문맥을 파악하는 데 있어 기존의 RNN이나 LSTM보다 뛰어난 성능을 보여줍니다.
3. Vision Transformer (ViT)
Vision Transformer(ViT)는 이미지 인식 분야에 Transformer를 적용한 방식입니다. ViT는 이미지를 고정된 크기의 패치들로 나눈 후, 이 패치들을 일련의 벡터로 변환합니다. 예를 들어, "An Image is Worth 16x16 Words"는 16x16 크기의 패치를 의미하며, 각 패치는 Transformer의 입력으로 사용됩니다. 그 후, 이 벡터들은 Transformer 레이어를 통해 처리되며, 이미지의 전체적인 문맥과 패치 간의 관계를 학습합니다.
4. Training ViT on Large-Scale Datasets
ViT의 성능은 학습 데이터셋의 크기에 크게 의존적입니다. 대규모 데이터셋에서 학습될 때 가장 좋은 성능을 발휘하는데, 이는 Transformer의 구조가 데이터의 복잡한 패턴과 문맥을 학습하는 데 매우 효과적이기 때문입니다. 이 논문에서는 JFT-300M과 같은 대규모 데이터셋에서 ViT의 성능을 실험하고, 기존의 state-of-the-art 이미지 인식 모델들과 비교합니다. 결과적으로 충분한 학습 데이터와 함께 사용될 때, ViT는 이미지 인식 태스크에서 뛰어난 성능을 보여줍니다
special issue:
- CNN구조를 Transfomer 구조로 대체
- Transformer 구조를 이용한 Architecture가 많은 SOTA를 기록하는데, ViT paper가 그 시작점
- 많은 데이터를 적은 cost로 transfer learning
- 대용량의 학습 자원과 데이터가 필요.
- 스케일 효과적인 성능
- 간단한 구조
- self-supervised learning
- 해석 가능성 및 시각화
먼저 Vision Transformer의 의의는 뭐가 있을까요.
- NLP 분야에서 많이 사용되는 Transformer를 CV분야에서 사용
- 기존 Attention mechanism에서 CNN 구조를 전반적으로 Transformer로 대체 (input의 sequences pof image patch에선 제외)
- 대용량 Dataset -> pre-training -> sample image dataset ==> Transfer Learning
inductive bias란?
machine learning에서의 inductive bias는 학습 모델이 지금까지 만나보지 못한 상황에 대해 정확한 예측을 위해 추가적인 가정을 의미합니다.
(The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered.)

conv. layer의 경우는 locality에 대한 가정이 있습니다.
convolution을 통하면 local 영역에서 Spatial한 정보를 더 잘 뽑아내는 것을 볼 수 있다. 이러한 모델 설계에 대한 가정이 포함되어 있습니다.
RNN에서는 sequence나열에서 가까운 것들에게 더 많은 영향을 주거나 받게 된다는 가정이 있습니다.
그래서 CNN은 global한 영역에 대한 처리가 어려우니 deformable 등의 연구로 Receptive field를 넓히려고 많이 연구를 했고,
RNN은 긴 문장에 대해서 앞 문장에 특정 주어를 지칭하는 문제에서 어려움을 겪었습니다.
그러나,
Transformer는 Positional Embedding이나 Self-Attention mechanism을 통해 모든 정보를 활용하지만 Inductive bias가 부족하다는 점이 있습니다.
그래서 robust하게 동작할 수 있지만 많은 양의 data를 필요로 합니다.
Introduction
Self-attention 기반 architecture인 Transformer는 자연어 처리 분야(Natural Language Processing, NLP)에서 선호되는 모델이 되었습니다.
larget text corpus에 pre-training 후 더 작은 특정 작업 dataset에 대해 fine-tunning 하는 것이 주된 approach 입니다. (Devline et al., 2019)
Transformer의 computational effciency와 scalability 덕분에 1000억 이상의 parameter를 가진 models을 훈련시키는 것이 가능해졌습니다. (Brown et al., 2020; Lepikhin et al., 2020)
models과 datasets의 발전으로, 더 이상 saturating performance 가는 징후는 아직 보이지가 않습니다.
그러나, Computer Vision에서 convolutional architecture 구조가 여전히 주입니다.
(LeCun et al., 1989; Krizhevsky et al., 2012; He et al., 2016)
NLP 분야의 성공으로 여러 연구들이 CNN과 같은 구조와 self-attention을 결합하려고 시도합니다(Wang et al., 2018; Carion et al., 2020),
일부는 CNNs을 완전히 대체하기도 합니다.(Ramachandran et al., 2019; Wang et al., 2020a)
이러한 모델은 이론적으로 효율적이지만, 특수한 self-attention 사용으로 인해 현대의 hardware accelerators에는 효과적으로 확장되지 않았습니다.
따라서, 대규모 image recognition에서는 classic ResNet과 같은 구조가 여전히 SOTA로 간주됩니다. (Mahajan et al., 2018; Xie et al., 2020; Kolesnikov et al., 2020)
NLP에서의 transformer scaling에 영감을 받아서,
본 논문의 저자들은, Transformer의 구조를 거의 수정하지 않고 image에 직접 적용합니다.
이를 위해, image를 patch로 분할하고, 이 patch의 linear embedding의 sequence를 Transformer의 input으로 제공합니다.
image patch는 NLP에서의 token, 즉 단어와 같이 처리됩니다.
본 모델을 supervised 방식으로 훈련하여 image classification에 적용합니다.
ImageNet과 같은 mid-sized dataset에서 강력한 regularization 없이 훈련된다면, 이러한 모델들은 비슷한 크기의 ResNets보다 몇 percentage 낮은 accuracy를 보입니다.
이러한 겉보기 실망스러운 결과가 예상될 수 있습니다.
본질적으로, Transformers는 CNNs에 비해 inductive biases가 부족하며, (CNNs의 inductive bias로는 translation equivariance & locality가 있음) 그로인해, 충분지 않은 양의 data에 대해 훈련될 때 일반화가 잘 되지 않습니다.
그러나, models이 더 큰 dataset(14M ~ 300M image)에서 훈련될 경우 상황이 바뀝니다.
저자들은 large scale training이 inductive bias를 앞선다 라는 것을 발견했습니다.
충분한 규모에서 pre-trained 되고 datapoints가 적은 task로 전송될 때,
본 Vision Transformer(ViT)는 훌륭한 결과를 달성합니다.
public ImageNet-21k dataset이나 in-house JFT-300M dataset에서 pre-training 될 때,
ViT는 여러 image recognition benchmark에서 SOTA에 근접하거나 이를 뛰어넘습니다.
특히, best model은 ImageNet에서 88.55%의 정확도, ImageNet-ReaL에서 90.72%, CIFAR-100에서 94.55%, 그리고 VTAB의 19개 작업에서 77.63%의 정확도를 달성합니다.
Related Work
Transformer는 Vaswani et al., 2017에 의해 machine translation을 위해 제안되었으며, 이후 많은 NLP 작업에서 SOTA가 되었습니다.
Large Transformer based models은 대규모 말뭉치에서 pre-trained된 후 특정 작업을 위해 fine-tunning됩니다.
BERT(Devlin et al., 2019)는 denoisiing self-supervised pre-training 작업을 사용하며, GPT는 그 pre-training 으로 language modeling을 사용합니다.(Radford et al., 2018; 2019; Brown et al., 2020).
image에 self-attention을 적용하면 각 pixel이 다른 모든 pixels에 attention을 합니다.
pixel 수에 대한 이차적인 cost로, 이것은 실제 input size로 확장되지 않습니다.
따라서 image processing의 맥락에서 Transformer를 적용하기 위해 과거에 여러 approximations이 시도 되었습니다.
Parmar et al. 2018은 각 query pixel에 대해 globally가 아닌 local neighborhood에서만 self-attention을 적용했습니다.
이러한 local multi-head dot-product self-attention block은 완전히 convolution을 대체할 수 있습니다.
다른 연구 라인에서, Sparse Transformers (Child et al., 2019)는 image에 적용 가능하도록 global self-attention에 대한 확장 가능한 approximation을 사용합니다.
attention을 확장하는 대안적인 방법은 block의 다양한 크기에서 적용하는 것이며, 극단적인 경우에는 개별 축을 따라만 적용됩니다.
이러한 특수 attention architecture 중 많은 것들이 Computer Vision 작업에서 유망한 결과를 보여주지만,
hardware accelerators에서 효율적으로 구현하려면 complex engineering이 필요하다.
가장 관련이 있는 것은 Cordonnier 등(2020)의 모델로, 입력 이미지에서 2 × 2 크기의 patch를 추출하고 위에 전체 self-attention을 적용한다.
이 models은 ViT와 매우 유사하지만, 본 연구는 large scale pre-training 이 vanila Transformer를 SOTA CNNs과 경쟁력 있게 (또는 더 나은) 만든다는 것을 보여줍니다.
게다가, Cordonnier 등(2020)은 2 × 2 픽셀의 작은 패치 크기를 사용하므로 모델은 작은 해상도 이미지에만 적용될 수 있으나, ViT는 중간 해상도 이미지도 처리한다.
또한 convolutional neural networks(CNNs)와 self-attention의 형태를 결합하는 데 큰 관심이 있었다.
예를 들어,
- image classification를 위해 feature map을 확대(Bello 등, 2019)하거나,
- self-attention을 사용하여 CNN의 output을 further processing하여 object detection(Hu 등, 2018; Carion 등, 2020),
- video processing(Wang 등, 2018; Sun 등, 2019),
- image classification(Wu 등, 2020),
- unsupervised object discovery(Locatello 등, 2020),
- unified text-vision tasks(Chen 등, 2020c; Lu 등, 2019; Li 등, 2019)
을 수행합니다.
또 다른 최근 관련 모델은 image GPT(iGPT) (Chen 등, 2020a)로, image resolution와 color space을 줄인 후 image pixel에 Transformer를 적용합니다.
models은 generative models로서 unsupervised training되며,
resulting representation은 fine-tunning 또는 classification performance을 위해 linearly probed 될 수 있으며 ImageNet에서 최대 72%의 정확도를 달성합니다.
본 연구는 표준 ImageNet 데이터셋보다 더 큰 규모에서 image recognition을 탐구하는 논문의 늘어나는 컬렉션에 추가됩니다.
additional data sources의 사용은 standard benchmakrs에서 SOTA를 달성할 수 있게 합니다(Mahajan 등, 2018; Touvron 등, 2019; Xie 등, 2020).
게다가, Sun 등(2017)은 CNN 성능이 dataset size와 어떻게 확장되는지 연구하고,
Kolesnikov 등(2020); Djolonga 등(2020)은 ImageNet-21k 및 JFT-300M과 같은 대규모 데이터셋에서의 CNN 전송 학습을 경험적으로 탐구합니다.
본 논문의 저자들은 이 두 가지 데이터셋에도 중점을 두고,
그러나 이전 연구에서 사용된 ResNet 기반 models 대신 Transformers를 훈련시킵니다.
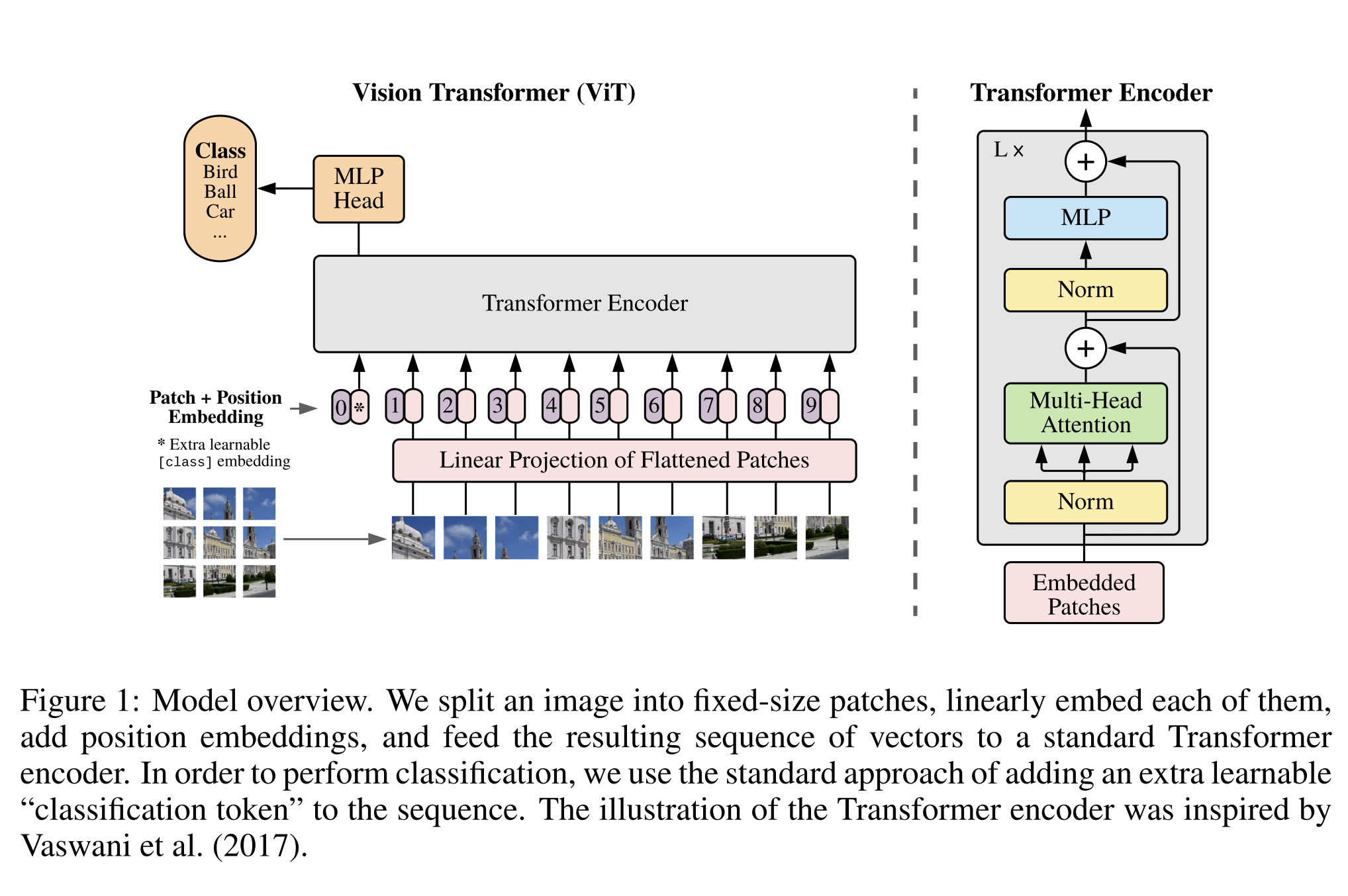
Method
본 논문에서 model design은 최대한 밀접하게 original Transformer를 따른다고 합니다.
이 의도적인 간단한 setup의 이점은,
scalable NLP Transformer architectures와 그 효율적인 구현이 거의 그대로 사용될 수 있다는 것입니다.
3.1. Vision Transformer (ViT)
standard Transformer 는 token embeddings의 1D-sequence를 입력으로 받는다.
2D image를 처리하기 위해, 우리는 이미지 $ x ∈ \mathbb{R}^{H×W×C} $ 를 2D pathes들의 시퀀스 $ x_p ∈ \mathbb{R}^{N×(P2 \cdot C)} $으로 flattened한다.
여기서 $ (H,W) $ 는 원래 image의 resolution, C는 채널 수, $ (P, P) $ 는 각 image patch의 resolution이며, $ N = HW/P^2 $ 는 결과로 나오는 patches의 수로, 이는 Transformer에 대한 실질적인 input sequence 길이 역할을 한다.
Transformer는 모든 layer에서 일정한 latent vector 크기 D를 사용하므로, patch를 flattened하고 trainable linear projection(Eq. 1)으로 D 차원에 mapping한다.
이 projection의 output을 patch embedding이라고 한다.
BERT의 [class] token과 유사하게, 우리는 embedded patches sequence에 learnable embedding을 앞에 추가한다(z00 = xclass).
Transformer encoder의 output에서의 state$ (z_0^0 = x_\text{class}) $는 image representation y(Eq. 4) 역할을 한다.
pre-training 및 fine-tunning 중에 $ z_L^0 $에 classification head 가 부착된다.
classification head는 pre-training time에는 one-hidden layer를 가진 MLP로,
fine-tunning time에는 one-single layer로 구현된다.
positional embedding이 patch embedding에 추가되어 positional information을 유지한다.
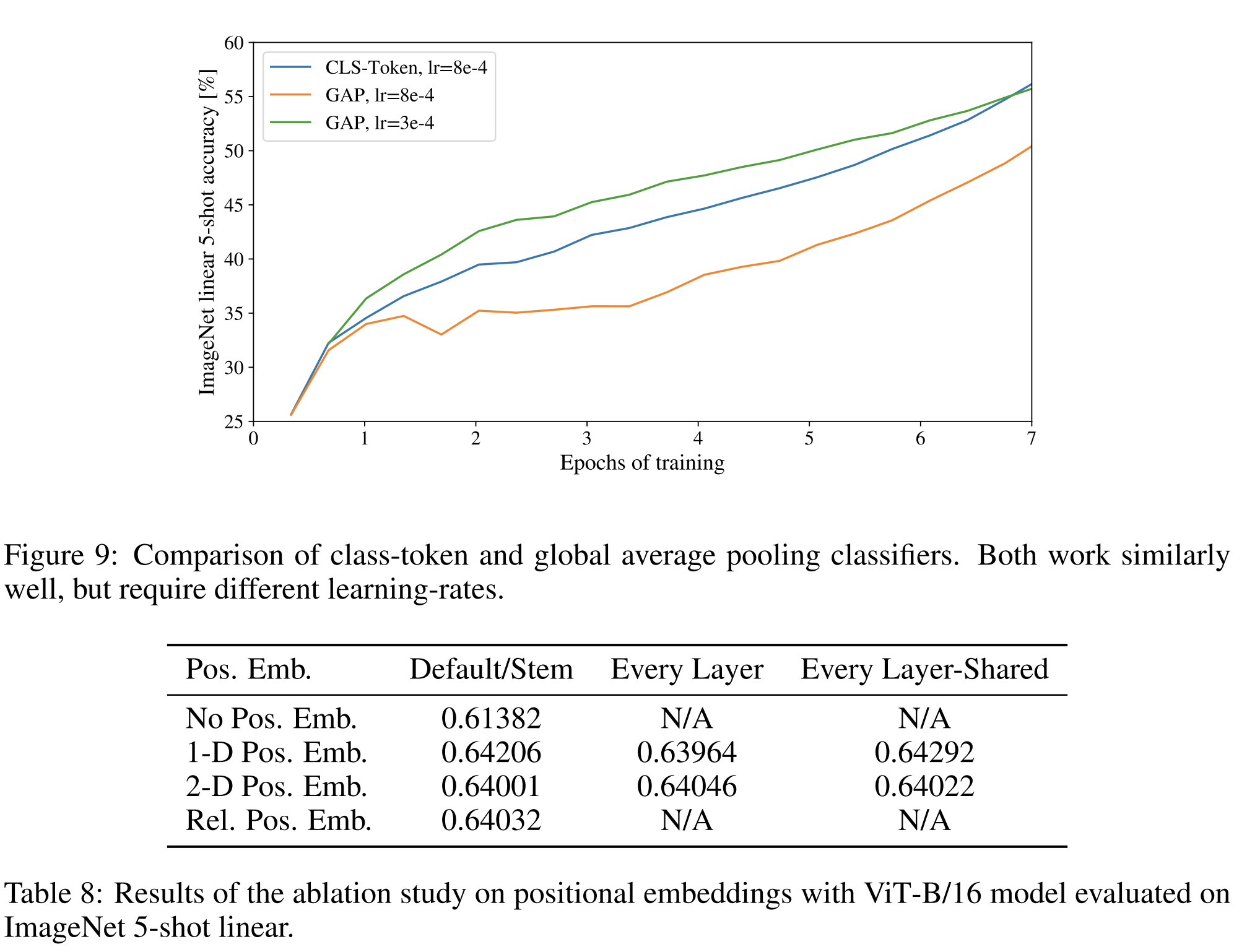
우리는 2D-aware positional embedding을 사용하여 더 높은 performance gains를 관찰하지 않았기 때문에 standard learnable 1D positional embedding을 사용한다(Appendix D.4).
결과로 나오는 embedding vector의 sequence는 encoder의 input으로 사용된다.
Transformer encoder(Vaswani et al., 2017)는 Multiheaded self-attention(MSA, 별첨 A 참조)과 MLP 블록(Eq. 2, 3)의 교대 레이어로 구성된다.
Layernorm (LN)는 모든 블록 전에 적용되고, 잔류 연결은 모든 블록 후에 적용된다(Wang 등, 2019; Baevski & Auli, 2019).
결국, CNN(Locality 가정)이나 RNN(Sequentiality 가정) 경우, Global한 영역 처리는 어렵습니다.
그러나 ViT는 일반적인 CNN과 다르게 공간에 대한 "Inductive bias"는 없습니다.
그러므로, ViT는 더 많은 데이터를 통해, 원초적인 관계를 Robust하게 학습 시켜야 합니다.
ViT는 MLP Layer에서만 Local 및 Translation Equivariance(이미지에서 특정 부분의 위치가 달라져도 동일한 값을 출력)를 합니다.
Self-Attention mechanism은 Global하게 됩니다.
2차원 구조를 매우 드물게 사용합니다.
image patch를 자르는 input 부분
fine-tunning 시 다른 resolution의 이미지를 위한 위치 embedding 조정
공간에 대한 관계를 처음부터 학습합니다. 즉, positional embedding 초기화 시 위치 정보에 대한 전달이 없습니다.
MLP는 두 개의 layers를 가지며 GELU non-linearity activation function을 사용합니다.
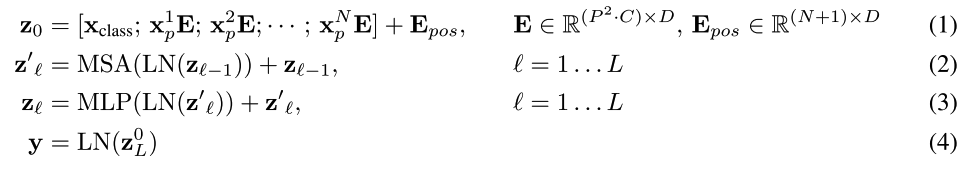
Inductive bias
ViT는 CNN에 비해 image-specific inductive bias가 훨씬 적습니다.
CNN에서는 locality, two-dimensional neighborhood structure, translation equivariance가 model 전체의 각 layer에 내장되어 있습니다.
그러나, ViT에서는 MLP layers만이 local이며 translationally equivariant하고 self-attention layer는 global입니다.
two-dimensional neighborhood structure는 매우 절약적으로 사용됩니다:
모델의 시작 부분에서 image를 patches로 분할하고 다양한 resolution의 image에 대한 position embedding을 조정하기 위해 fine-tunning합니다.
그 외에는 initialization 시점의 position embedding 이 patch의 2D 위치에 대한 information을 전혀 담고 있지 않으며 patches 간의 모든 spatial relations은 처음부터 학습되어야 합니다.
Hybrid Architecture
raw image patches의 대안으로 input sequence는 CNN의 feature map에서 형성될 수 있습니다.
이 hybrid model에서 patch embedding projection $ E $ (Eq. 1)은 CNN feature map에서 추출된 patch에 적용됩니다.
특별한 경우, patch는 space size가 1 x 1을 가질 수 있으며,
이는 input sequence가 feature map의 spatial dimension을 단순히 flattening하고 Transformer 차원으로 projection함으로써 얻어진다는 것을 의미합니다.
classification input embedding과 position embedding은 위에서 설명한대로 추가됩니다.
3.2. Fine-tuning and Higher Resolution
일반적으로 큰 Dataset에서 ViT를 pre-training시키고 (더 작은) downstream task로 fine-tuning합니다.
이를 위해 pre-trained prediction head를 제거하고, zero-initialized D × K feedforward layer를 연결합니다.
여기서 K는 downstream classes의 수입니다.
pre-training보다 higher-resolution에서 fine-tuning하는 것이 종종 유익하다고 합니다 (Touvron et al., 2019; Kolesnikov et al., 2020).
higher resolution의 image를 입력할 때 patch 크기는 동일하게 유지되어, 효과적인 sequence length가 더 커집니다.
Vision Transformer는 임의의 sequence length를 처리할 수 있지만, pre-trained position embedding은 더 이상 의미 있지 않을 수 있습니다.
따라서 원래 이미지에서의 위치에 따라 pre-trained position embedding 의 2D interpolation을 수행합니다.
이 resolution adjustment 및 patch extraction은 image의 2D structure에 대한 inductive bias가 Vision Transformer에 수동으로 주입되는 유일한 시점입니다.
Experiments
본 논문의 저자는 ResNet, Vision Transformer (ViT), 그리고 hybrid의 representation learning capabilities을 평가합니다.
각 model의 data requirements를 이해하기 위해 다양한 크기의 dataset에서 pre-training하고 많은 benchmark task를 평가합니다.
model의 pre-training cost을 고려할 때, ViT는 매우 유리하게 수행되며, 더 낮은 pre-training cost에서 대부분의 인식 벤치마크에서 SOTA을 달성합니다.
마지막으로, self-supervision을 사용하는 작은 실험을 수행하고, self-supervised ViT가 유망함을 보여줍니다.
4. 1. Setup
Datasets
model scalability를 탐구하기 위해, ILSVRC-2012 ImageNet dataset(1k classes와 1.3M images)을 사용합니다.
이를 저자들은 단순히 ImageNet으로 부릅니다.
그리고 이의 superset인 ImageNet-21k(21k classes스와 14M images)와 JFT(18k classes와 303M high-resolution images)도 사용합니다.
저자들은 Kolesnikov 등(2020)의 방식을 따라 downstream task의 test set에 대해 pre-training dataset을 중복 제거합니다.
이러한 dataset에서 trained models들은 여러 benchmark task로 전송됩니다:
원래 validation label과 정리된 ReaL 라벨(Beyer 등, 2020)을 가진 ImageNet, CIFAR-10/100, Oxford-IIIT Pets, 그리고 Oxford Flowers-102에 대한 작업입니다.
이 데이터셋의 전처리는 Kolesnikov 등(2020)을 따릅니다.
또한, 19개 작업의 VTAB classification set(Zhai 등, 2019b)에서도 평가합니다.
VTAB는 작업 당 1,000개의 훈련 예제를 사용하여 다양한 작업으로의 low-dataa transfer을 평가합니다.
작업들은 세 그룹으로 나뉩니다:
- Natural(애완 동물, CIFAR 등과 같은 작업)
- Specialized(의료 및 위성 이미지)
- Structured(지역화와 같은 기하학적 이해를 필요로 하는 작업)
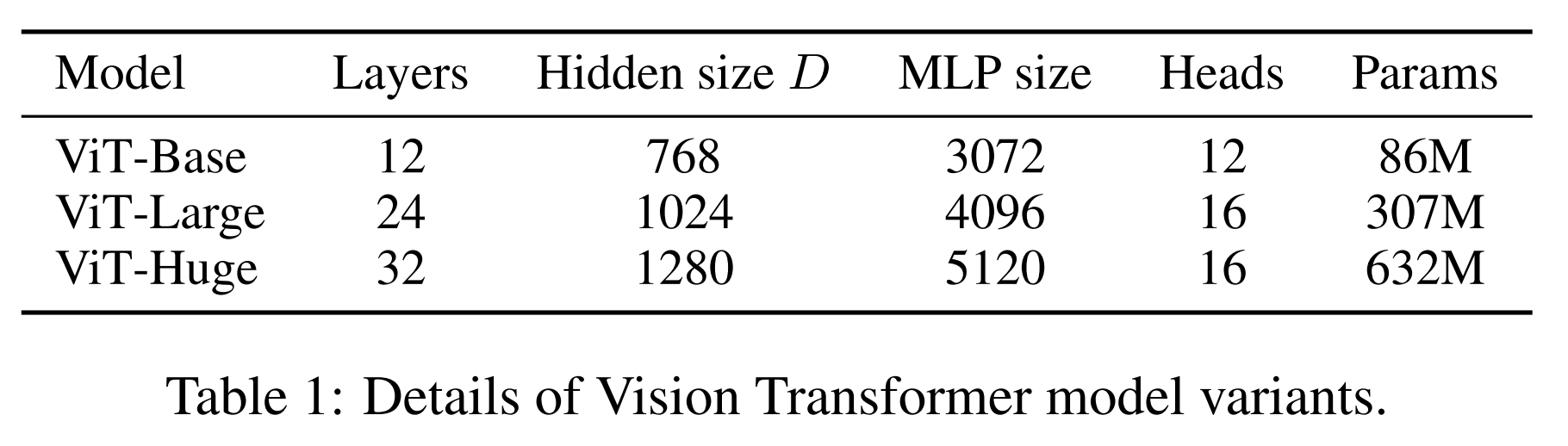
Model variants
ViT 설정은 BERT(Devlin 등, 2019)에 사용된 것을 기반으로 합니다.
“Base”와 “Large” 모델은 BERT에서 바로 가져왔으며, 더 큰 “Huge” 모델을 추가했습니다.
ViT-L/16과 같은 간단한 표기법을 사용하여 model size와 input patch size를 나타냅니다.
ViT/16은 "Large" variant를 의미하고 Input patch size는 16 x 16입니다.
Transformer의 sequence length는 patch size의 제곱에 반비례하므로,
작은 patch size의 models은 연산적으로 더 비싸게 됩니다.
기본 CNNs 대해, 저자들은 ResNet(He 등, 2016)을 사용하지만, Batch Normalization layer(Ioffe & Szegedy, 2015)를 Group Normalization(Wu & He, 2018)으로 교체하고, 표준화된 convolution(Qiao 등, 2019)을 사용했습니다.
이러한 수정은 transfer 성능을 향상시키는 것으로 확인됐습니다(Kolesnikov 등, 2020).
그리고 저자들은 수정된 모델을 "ResNet (BiT)"라고 명명했습니다.
하이브리드의 경우, intermediate feature map을 "pixel" 크기의 patch로 ViT에 공급합니다.
다른 sequence length로 실험하기 위해,
- (i) 일반 ResNet50의 4단계 출력을 가져오거나
- (ii) 4단계를 제거하고 3단계에 동일한 수의 레이어를 배치(레이어 총 수 유지)한 후 이 확장된 3단계의 출력을 가져옵니다.
(ii) 옵션은 4배 더 긴 시퀀스 길이와 더 비싼 ViT 모델을 초래합니다.
Training & Fine-tuning
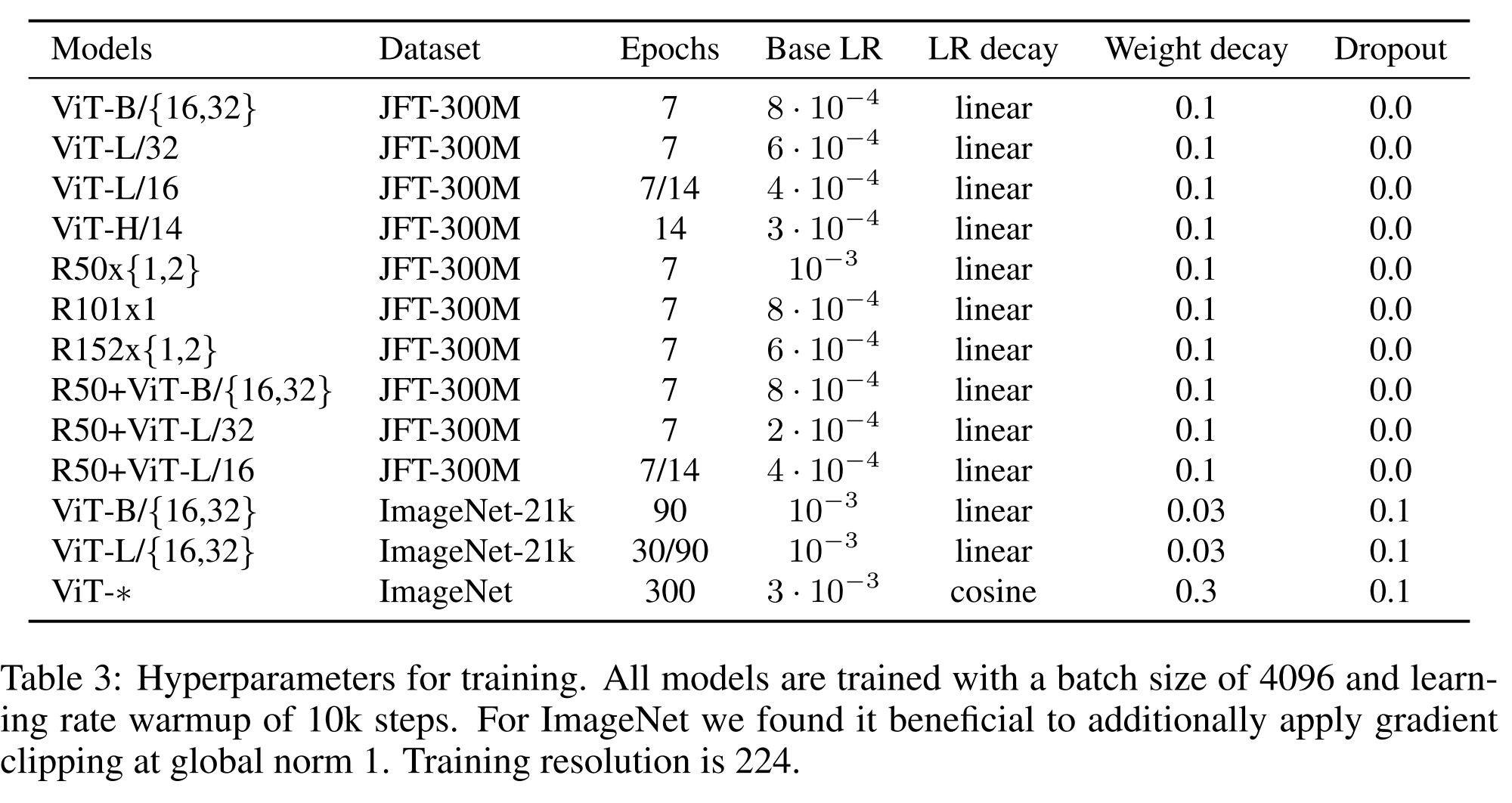
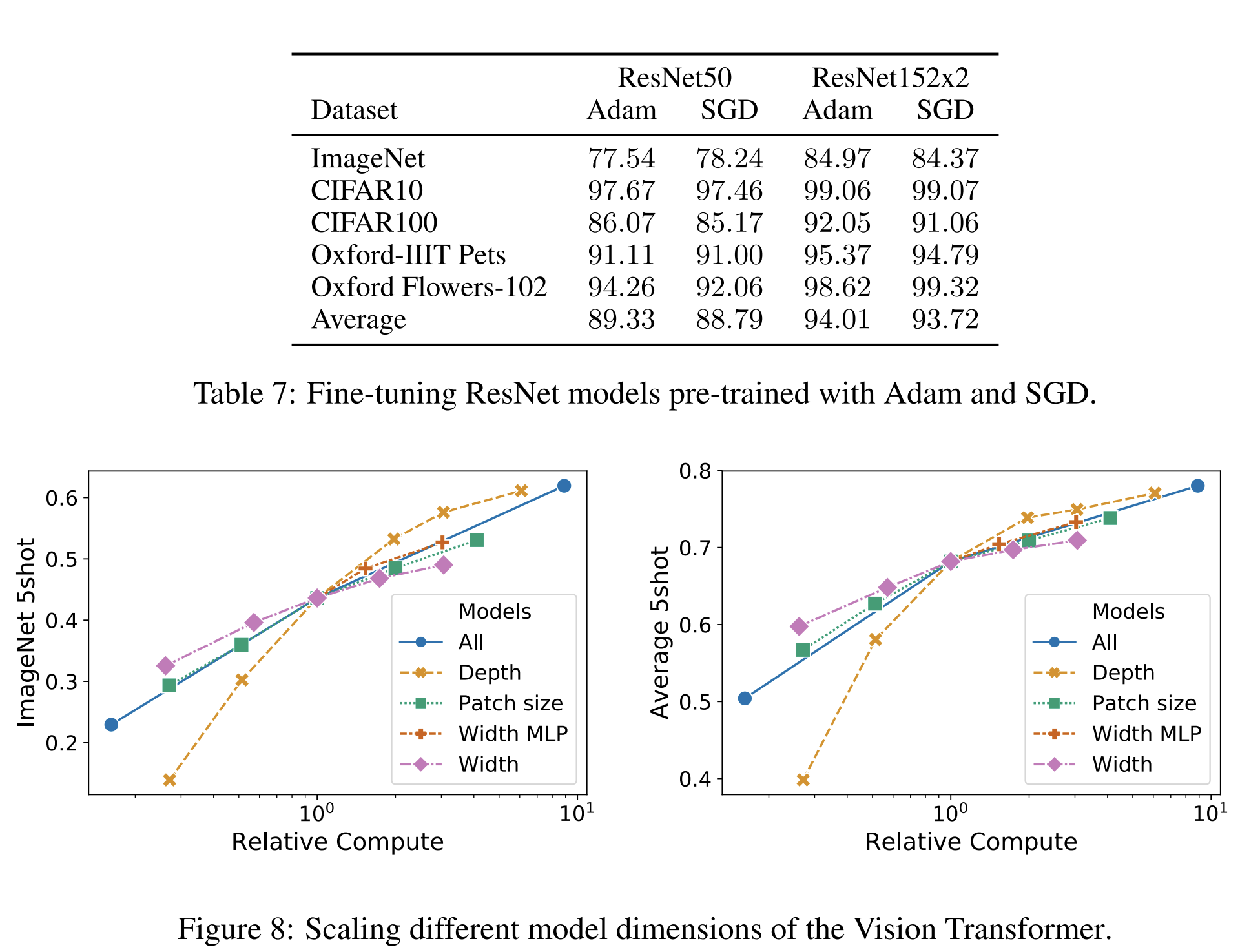
저자들은 모든 모델, ResNet을 포함하여, β1 = 0.9, β2 = 0.999, 배치 크기 4096을 갖는 Adam(Kingma & Ba, 2015)을 사용하여 훈련시킵니다.
그리고 0.1의 높은 weight decay를 적용했는데, 이것이 모든 model의 transfer에 유용하다고 발견했습니다.
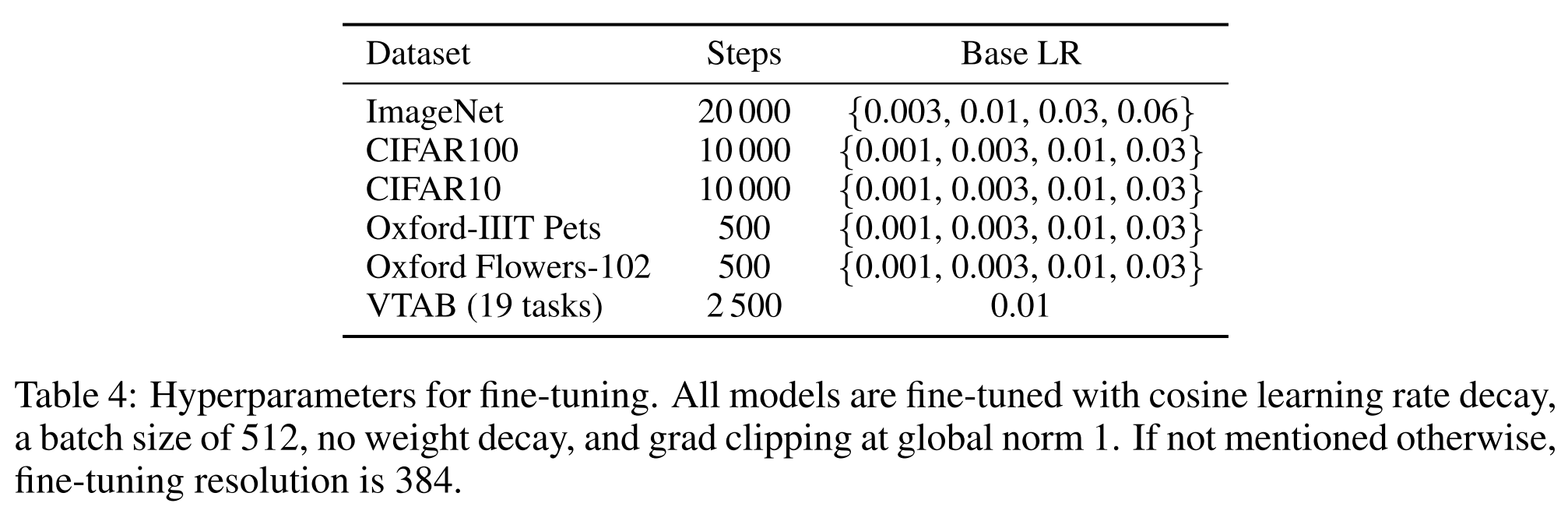
저자들은 linear learning rate warmup and decay 를 사용하며, 세부 사항은 부록 B.1을 참조하십시오.
fine-tuning을 위해 저자들은 모든 model에 대해 momentum을 가진 SGD와 batch size 512를 사용합니다.
Table 2의 ImageNet 결과의 경우, ViT-L/16에 대해 512, ViT-H/14에 대해 518의 더 higher resolution에서 fine-tuning을 했으며, 0.9999의 요소로 Polyak & Juditsky (1992) averaging도 사용했습니다.
Metrics
저자들은 downstream dataset에 대한 결과를 few-shot 또는 fine-tuning accuracy를 통해 report합니다.
fine-tuning accuracy는 각 model이 해당 dataset에서 fine-tuned 후의 성능을 반영합니다.
few-shot accuracy는 training image의 subset의 (고정된) representation을 $ {−1, 1}^K $ 대상 vector에 mapping하는 regularized least-sequares regression problem을 해결하여 얻습니다.
이 공식은 closed form에서 정확한 해답을 복구할 수 있게 합니다.
주로 fine-tuning performance에 중점을 두지만, fine-tuning이 너무 비쌌을 때는 lienar few-shot accuracy를 빠른 평가에 사용하기도 합니다.
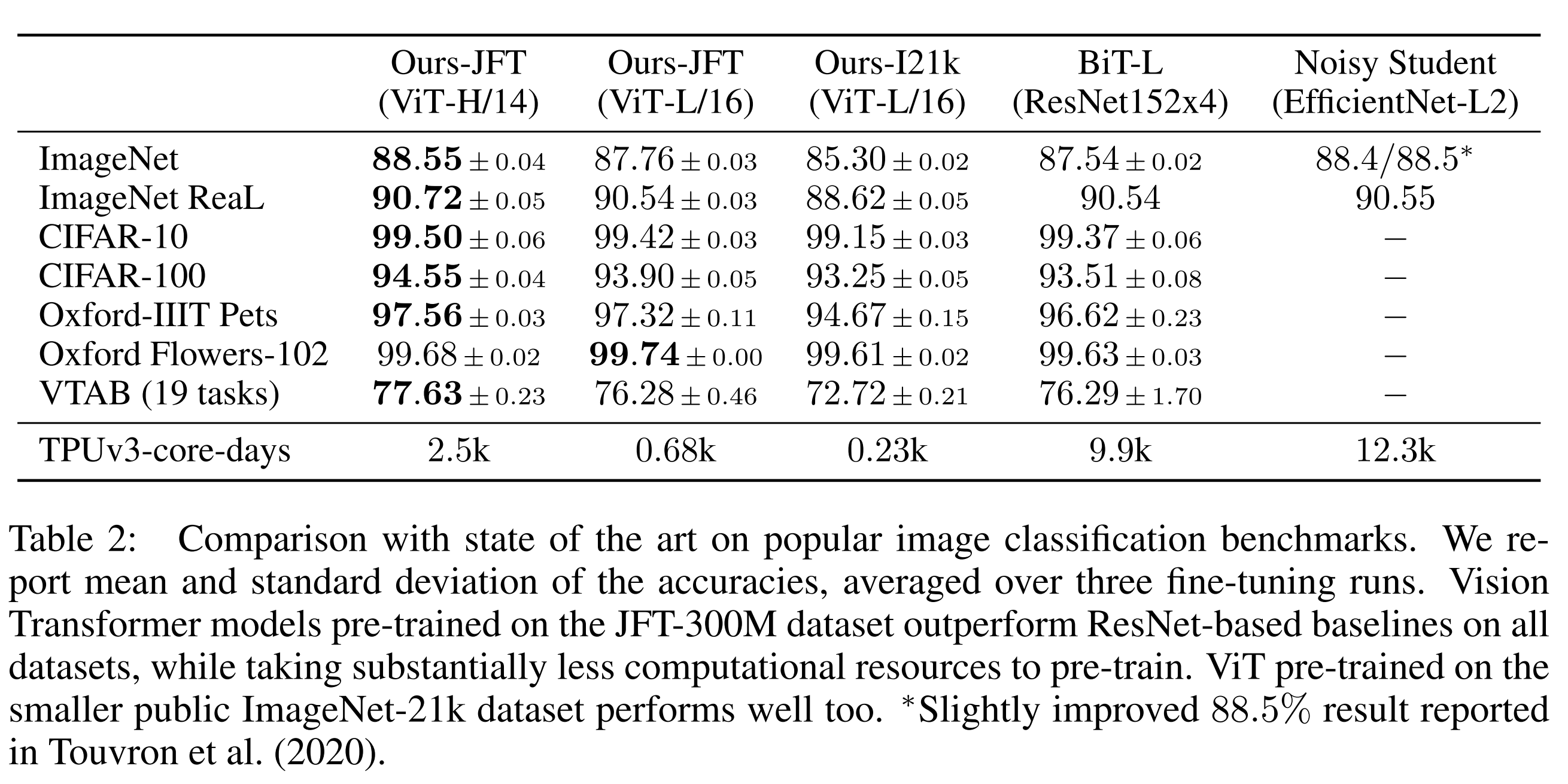
Comparison To State-of-the-art
저자들은 가장 큰 모델들인 ViT-H/14와 ViT-L/16을 문헌의 최신 CNNs와 비교합니다.
첫 번째 비교 대상은 큰 ResNets로 supervised transfer learning을 수행하는 Big Transfer (BiT) (Kolesnikov 등, 2020)입니다.
두 번째는 label이 제거된 ImageNet 및 JFT-300M에서 semi-supervised을 사용하여 훈련된 큰 EfficientNet인 Noisy Student (Xie 등, 2020)입니다.
현재 Noisy Student는 ImageNet에서 최고의 성능을 보이며, BiT-L은 여기에 보고된 다른 dataset에서 최고입니다.
모든 모델은 TPUv3 hardware에서 훈련되었으며, 각 모델의 pre-training에 소요된 TPUv3-core-days 수를 보고합니다.
JFT-300M에서 pre-trained 작은 ViT-L/16 모델은 모든 작업에서 BiT-L(동일한 dataset에서 pre-trained된)를 능가하면서, 훈련에 훨씬 적은 computational resources를 필요로 합니다.
더 큰 모델인 ViT-H/14는, 특히 ImageNet, CIFAR-100 및 VTAB 스위트와 같은 더 challenging dataset에서 성능을 향상시킵니다.
이 model은 이전 SOTA보다 pre-training에 훨씬 less computation을 필요로 합니다.
그러나, pre-training efficiency는 architecture 선택 뿐만 아니라 training schedule, optimizer, weight decay 등의 다른 parameter에 의해 영향을 받을 수 있음을 언급하고자 합니다.
저자들은 4.4 섹션에서 다양한 architecture에 대한 performance와 computation의 관계에 대한 통제된 연구를 제공합니다.
마지막으로, 공개 ImageNet-21k 데이터셋에서 사전 훈련된 ViT-L/16 모델도 대부분의 데이터셋에서 잘 작동하며,
pre-training에 더 적은 리소스를 필요로 합니다:
이 모델은 대략 30일 동안 표준 클라우드 TPUv3 8코어를 사용하여 훈련될 수 있습니다.
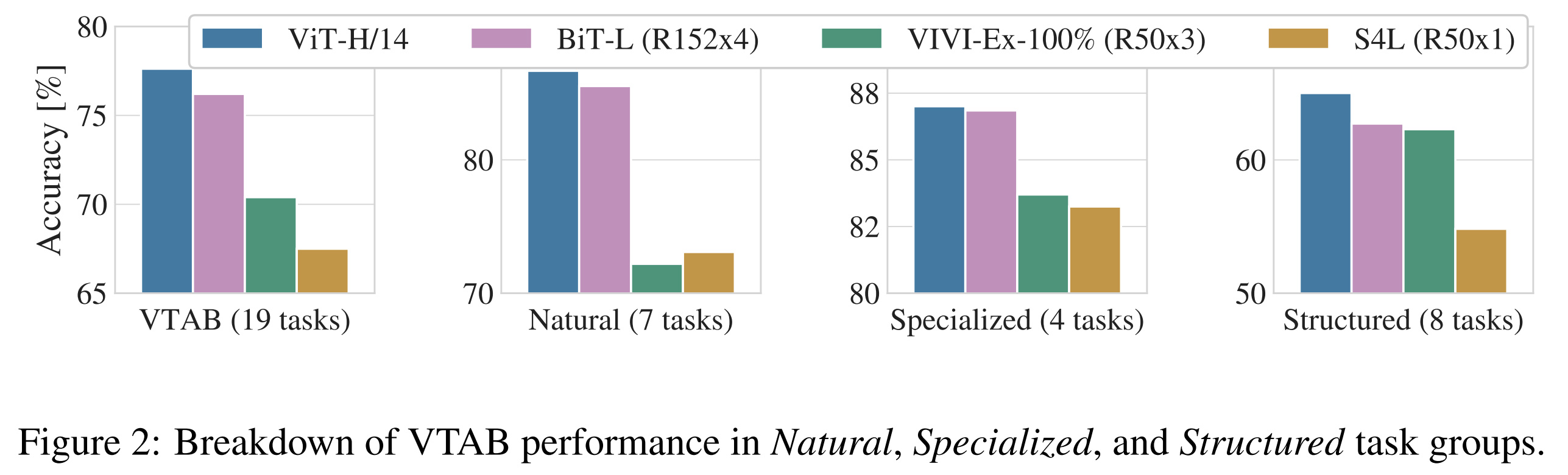
Figure 2는 VTAB 작업을 해당 그룹으로 분해하고 이 benchmark에서 이전의 SOTA와 비교합니다:
BiT, VIVI - ImageNet과 Youtube에서 함께 훈련된 ResNet(Tschannen 등, 2020) 및 S4L - ImageNet에서의 supervised plus semi-supervised learning(Zhai 등, 2019a).
ViT-H/14는 Natural 및 Structured 작업에서 BiT-R152x4와 다른 방법보다 더 우수한 성능을 보입니다.
Specialized에서는 두 top models이 비슷한 성능을 보입니다.
Pre-training Data Requirements
Vision Transformer는 큰 JFT-300M 데이터셋에 pre-training될 때 잘 수행됩니다.
ResNets보다 더 적은 시각적 inductive bias을 가진 경우,
데이터셋의 크기는 얼마나 중요한가요?
저자들은 두 번의 실험을 수행합니다.
1. 첫째, 크기가 점점 커지는 데이터셋에서 ViT 모델을 사전 훈련합니다: ImageNet, ImageNet-21k, 그리고 JFT-300M입니다.
더 작은 데이터셋에서의 성능을 향상시키기 위해, 우리는 세 가지 기본 regoularization parameters를 최적화합니다 - weight decay, dropout, 그리고 label smoothing입니다.
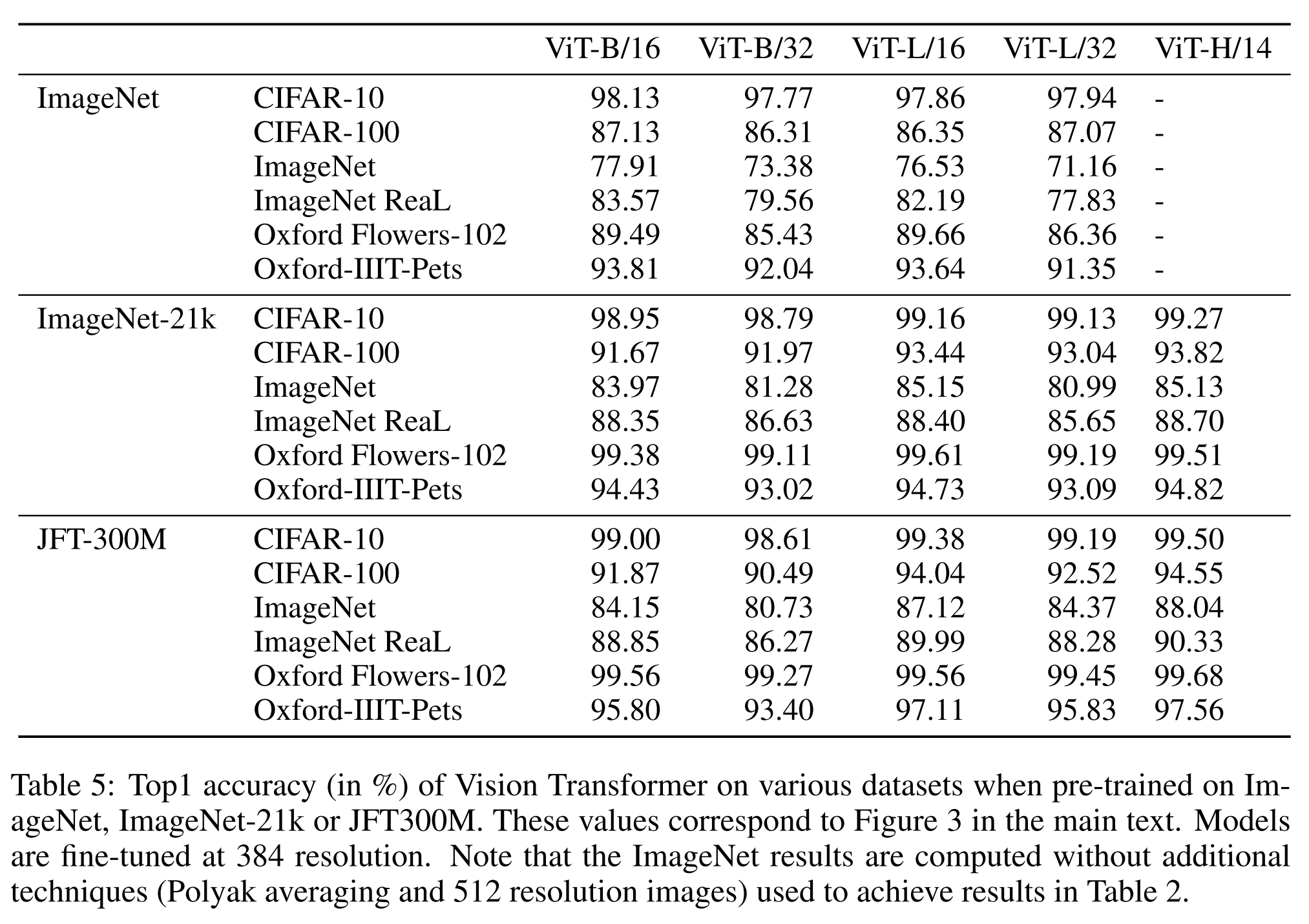
Figure 3은 ImageNet으로 fine-tuning한 후의 결과를 보여줍니다 (다른 데이터셋에서의 결과는 표 5에 나타나 있습니다).
가장 작은 데이터셋, ImageNet에서 pre-trainging될 때, ViT-Large 모델은 (적당한) regularization에도 불구하고 ViT-Base 모델보다 성능이 떨어집니다.
ImageNet-21k 사전 훈련에서 그들의 성능은 유사합니다.
JFT-300M에서만 더 큰 모델의 전체적인 이점을 볼 수 있습니다.
Figure 3은 또한 다양한 크기의 BiT 모델에 의해 형성된 성능 영역을 보여줍니다.
BiT CNN들은 ImageNet에서 ViT보다 더 나은 성능을 보이지만, 더 큰 데이터셋에서는 ViT가 앞서게 됩니다.
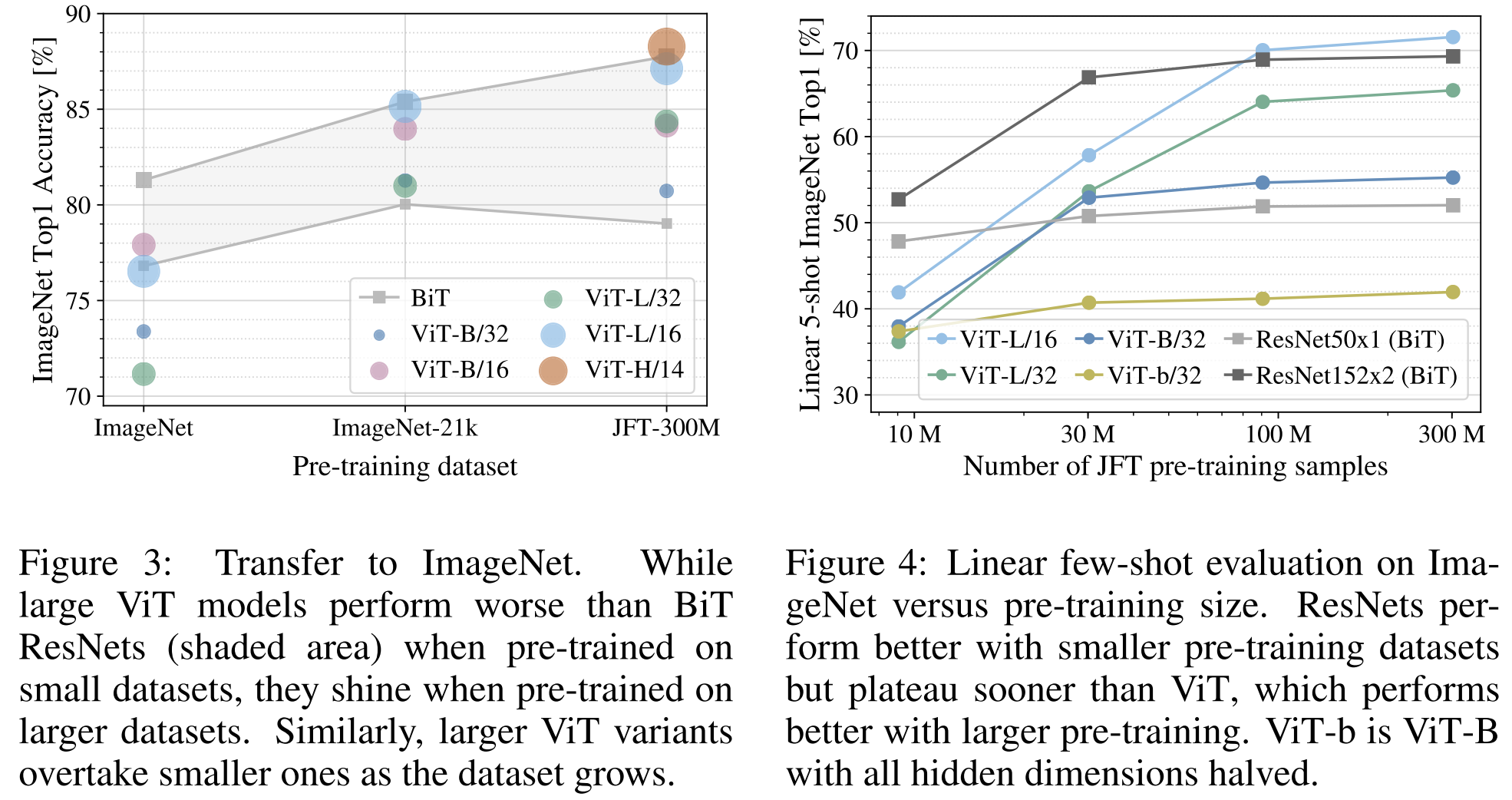
2. 둘째, 9M, 30M, 90M의 무작위 하위 집합뿐만 아니라 전체 JFT-300M 데이터셋에서 모델을 훈련시킵니다.
우리는 더 작은 하위 집합에서 추가적인 regularization을 수행하지 않고 모든 설정에 대해 동일한 hyper-parameter를 사용합니다.
이렇게 하여, intrinsic model properties를 평가하며, regularization의 효과가 아닙니다.
그러나, 우리는 early-stopping를 사용하며, 훈련 중에 달성된 최상의 validation accuracy를 보고합니다.
계산을 절약하기 위해, 우리는 전체 fine-tuning accurcay 대신에 few-shot linear accuracy를 보고합니다.
Figure 4에는 결과가 포함되어 있습니다.
Vision Transformers는 더 작은 데이터셋에서 비교적 계산 비용이 드는 ResNets보다 더 많이 overfitting됩니다.
예를 들어, ViT-B/32는 ResNet50보다 약간 빠르다; 9M 하위 집합에서는 훨씬 나쁘지만, 90M+ 하위 집합에서는 더 나아집니다.
ResNet152x2와 ViT-L/16에 대해서도 동일한 결과가 나타납니다.
이 결과는 작은 데이터셋에 유용한 convolutional inductive bias가 있다는 직관을 강화하지만,
더 큰 데이터셋에 대해서는 데이터에서 직접 관련 패턴을 학습하는 것이 충분하고, 심지어 유익하다는 것을 보여줍니다.
전반적으로, ImageNet에서의 few-shot 결과 (figure 4) 및 VTAB의 저 데이터 결과 (표 2)는 매우 낮은 데이터 전송에 대해 유망해 보입니다.
ViT의 few-shot 특성에 대한 추가적인 분석은 향후 연구 방향으로 흥미롭습니다.
Scaling Study
저자들은 JFT-300M에서의 transfer performance를 평가함으로써 다양한 모델의 scaling control 연구를 수행했습니다.
이 설정에서는 데이터 크기가 모델의 성능을 제한하지 않으므로, 각 모델의 pre-training cost에 따른 성능을 평가합니다.
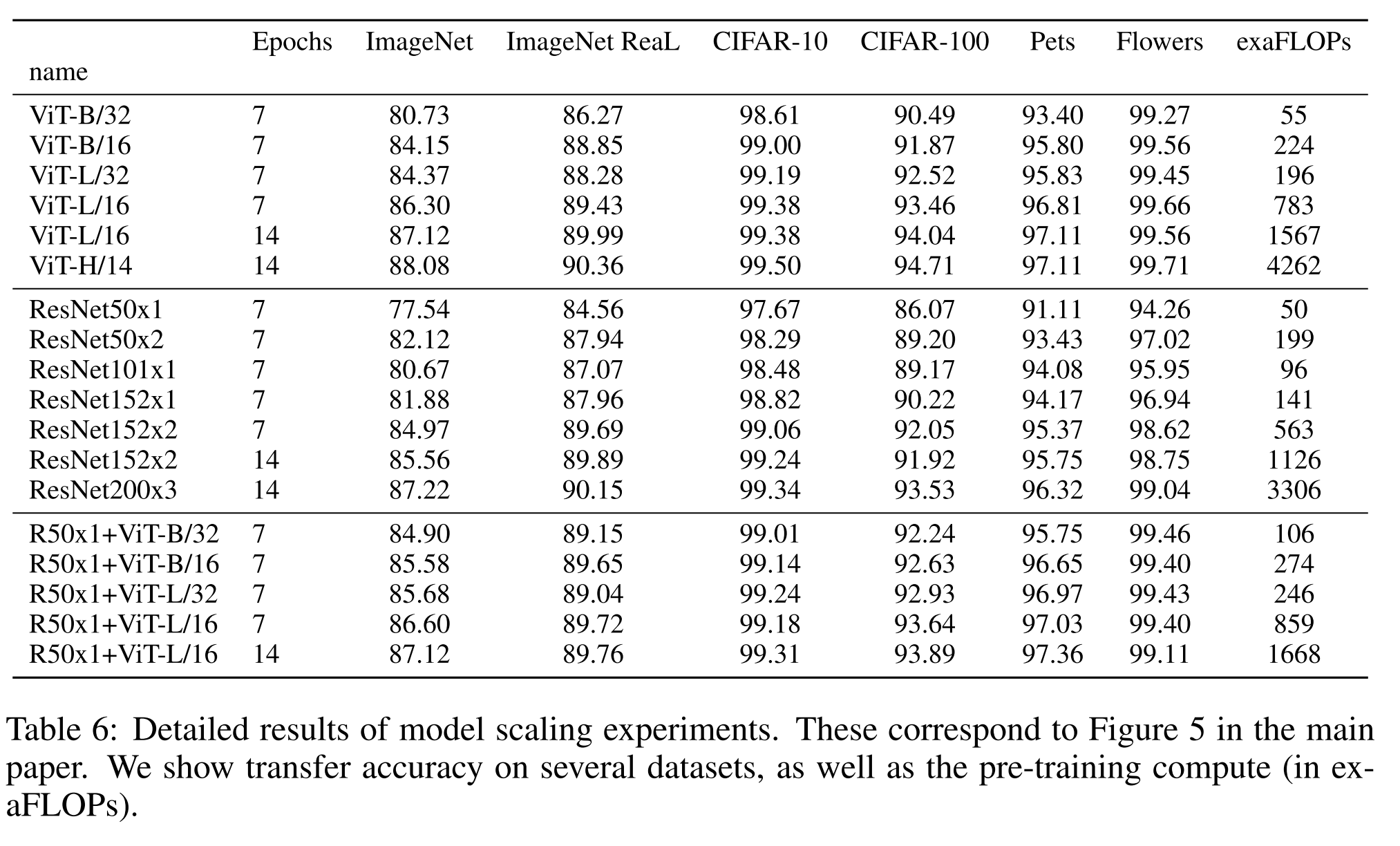
모델 세트에는 다음과 같은 것들이 포함됩니다: 7개의 ResNets, R50x1, R50x2, R101x1, R152x1, R152x2가 epochs 7 동안 pre-training, R152x2와 R200x3는 epochs 14 동안 ptr-training. 6개의 Vision Transformers, ViT-B/32, B/16, L/32, L/16은 epochs 7 동안 pre-training, L/16과 H/14는 epochs 14 동안 pre-training. 그리고 5개의 하이브리드, R50+ViT-B/32, B/16, L/32, L/16은 epochs 7 동안 pre-training, R50+ViT-L/16은 epochs 14 동안 pre-training (하이브리드의 경우, 모델 이름 끝의 숫자는 패치 크기가 아닌 ResNet 백본에서의 총 다운샘플링 비율을 나타냅니다).
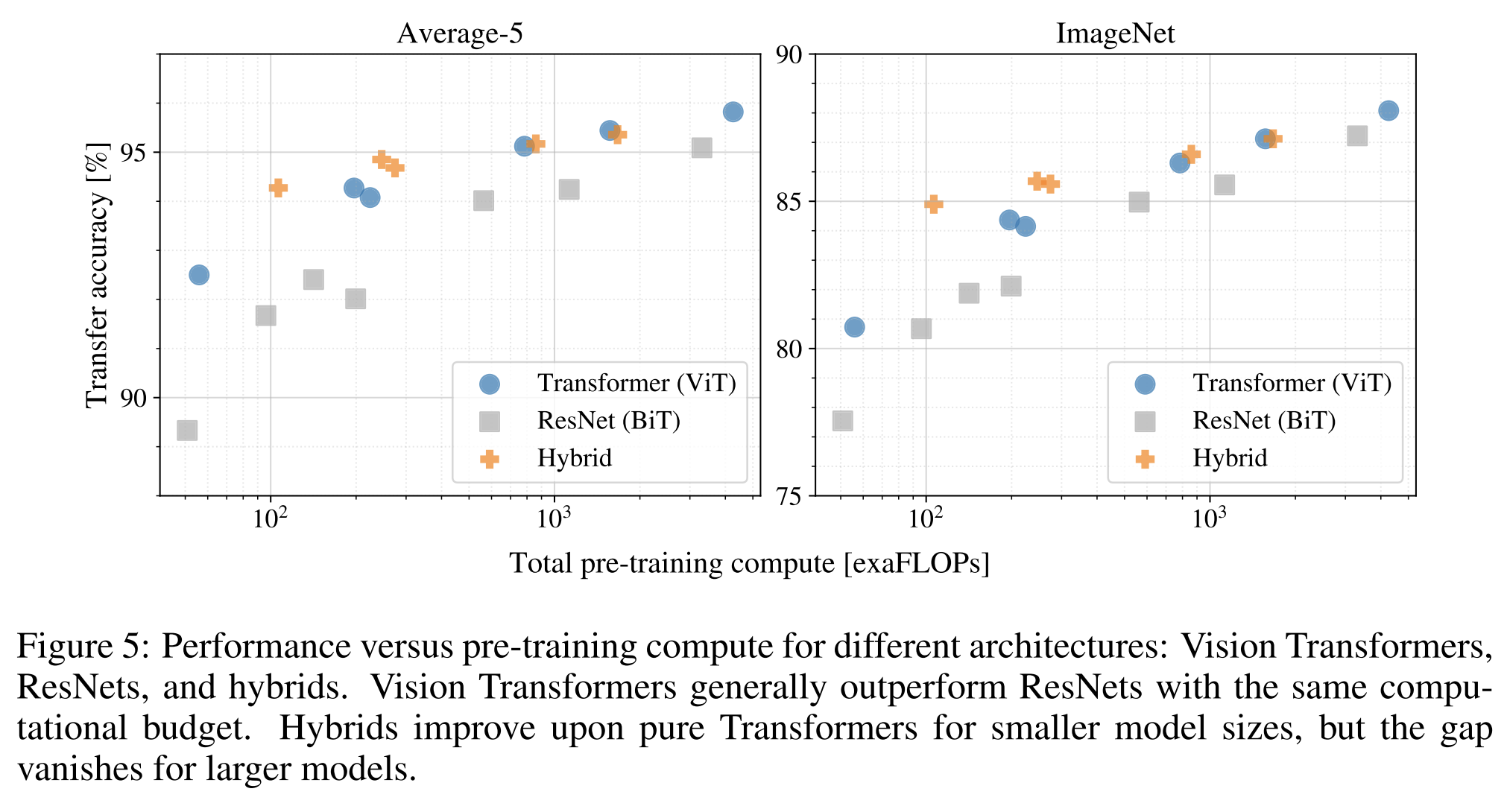
Figure 5는 전체 pre-training cost와 transfer performance을 보여줍니다 (계산 비용에 대한 자세한 내용은 부록 D.5를 참조하십시오).
모델별 자세한 결과는 부록의 표 6에 제공됩니다.
몇 가지 패턴을 관찰할 수 있습니다.
1. 첫째, Vision Transformers는 performance/compute 효율성 면에서 ResNets를 압도합니다.
ViT는 동일한 성능을 달성하기 위해 약 2 - 4배 적은 계산을 사용합니다 (5개 데이터셋의 평균).
2. 둘째, small computational budgets 에서는 하이브리드가 ViT를 약간 앞섭니다만, 더 큰 모델에서는 그 차이가 사라집니다.
이 결과는 convolutional local feature processing이 어떤 크기에서든 ViT를 도와줄 것으로 기대했기 때문에 다소 놀랍습니다.
3. 셋째, 시도된 범위 내에서 Vision Transformers는 포화되지 않는 것처럼 보여서 미래의 규모 확장 노력을 독려합니다.
Inspecting Vision Transformer
이미지 데이터가 Vision Transformer에 의해 어떻게 처리되는지 이해하기 위해, 우리는 그 내부 표현을 분석합니다.

Vision Transformer의 첫 번째 layer는 flattened patches을 저차원 공간으로 linearly projection합니다(Eq. 1). Figure 7(left)은 학습된 임베딩
필터의 top principal components를 보여줍니다. 이 구성 요소들은 각 patch 내의 fine structure의 low-dimensional representation을 위한 타당한 기초 함수처럼 보입니다.
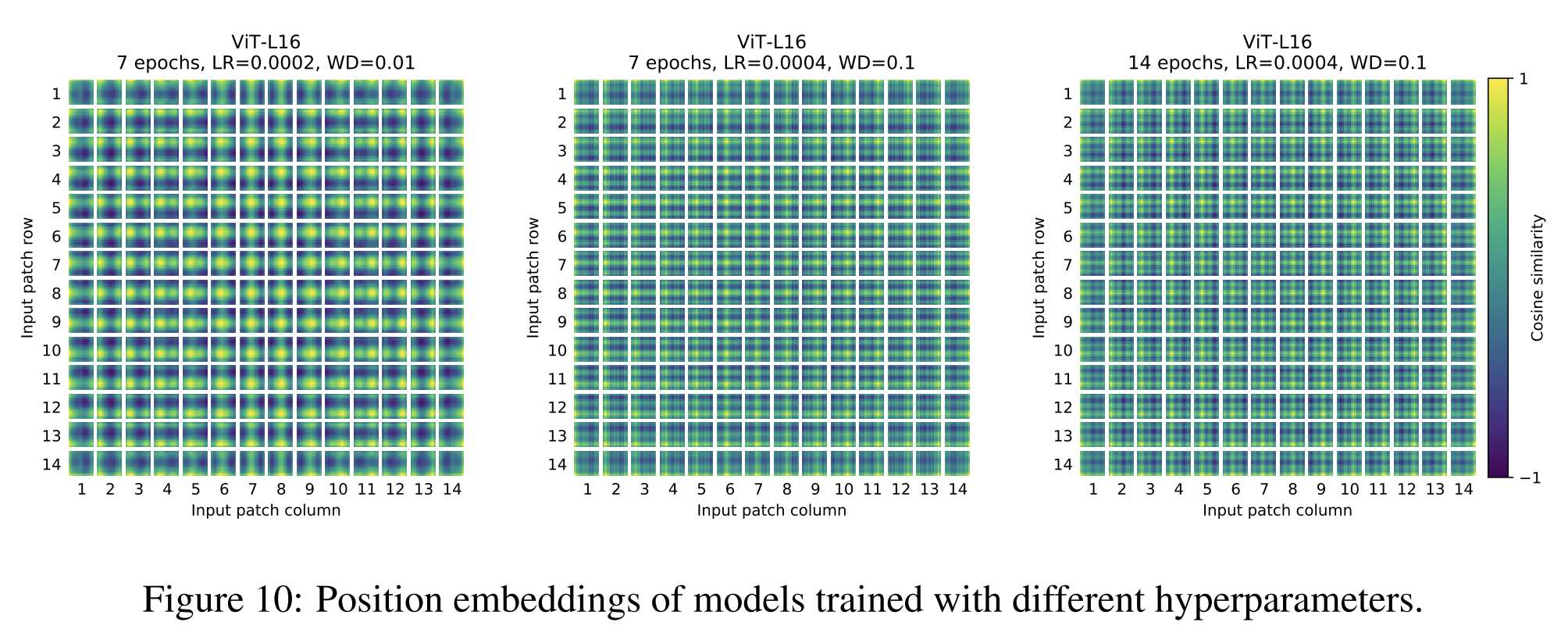
projection후, learned position embedding이 patch representation에 추가됩니다. Figure 7(center)은 모델이 이미지 내의 거리를 position embedding의 유사성에 인코딩하는 방법을 학습한다는 것을 보여줍니다. 즉, 가까운 patches들은 더 유사한 position embedding을 가집니다. 또한, 행-열 구조가 나타나며, 같은 행-열의 patches들은 유사한 embedding을 가집니다.
마지막으로, 더 큰 grid에서는 때로는 sinusoidal 구조가 나타납니다(부록 D). position embedding이 2D 이미지 topology를 나타내도록 학습한다는 것은 수작업으로 만든 2D 인식 embedding 변형이 향상을 가져오지 않는 이유를 설명합니다(부록 D.4).
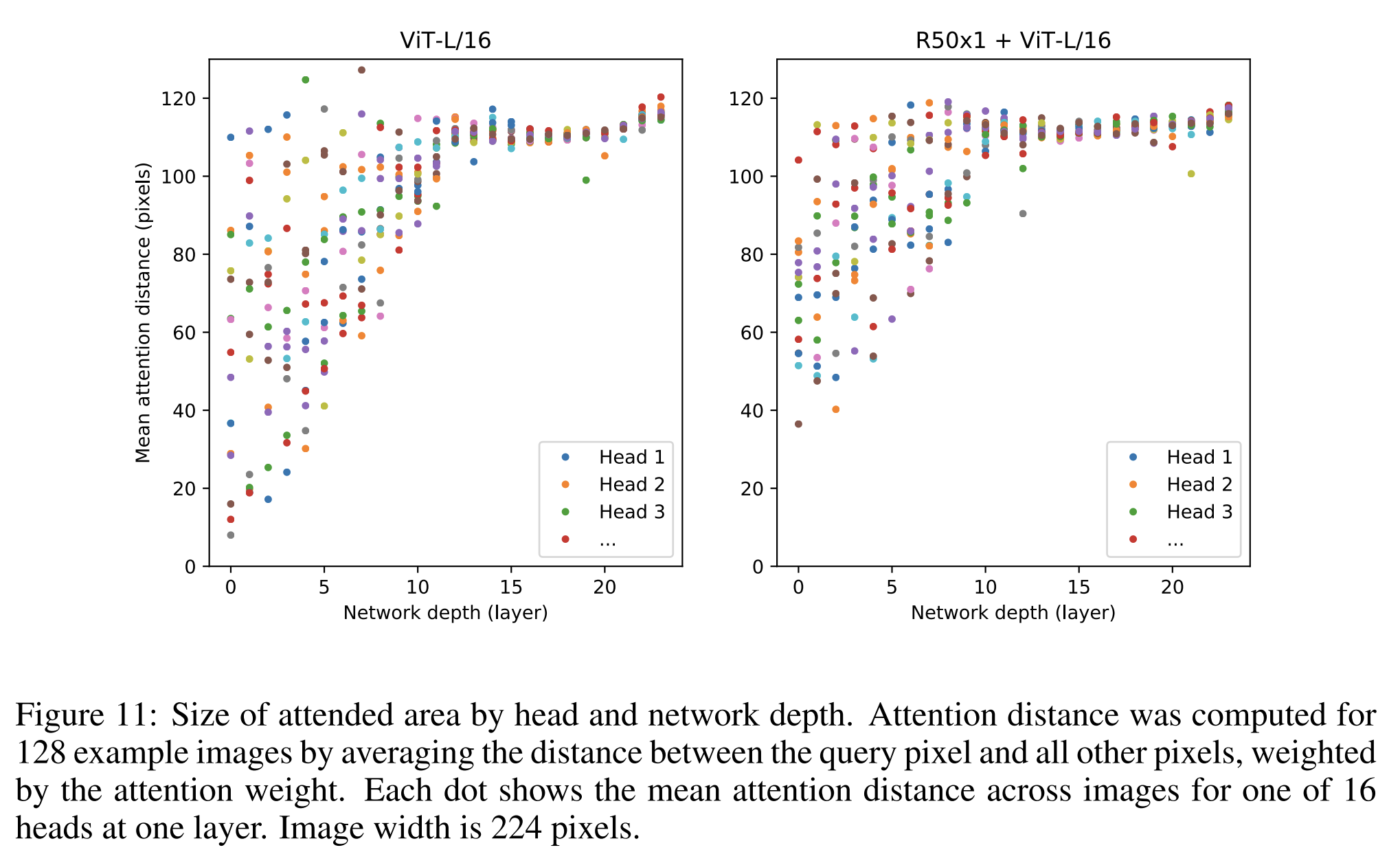
self-attention은 ViT가 가장 낮은 계층에서도 전체 이미지를 통한 정보 통합을 가능하게 합니다. 우리는 네트워크가 이 기능을 어느 정도로 활용하는지 조사합니다.
특히, attention weights를 기반으로 이미지 space에서 정보가 통합되는 average distance를 계산합니다(그림 7, right). 이 "attention distance"는 CNN에서의 receptive field size와 유사합니다.
가장 낮은 layer에서 이미 몇몇 head가 이미지 전체에 주의를 기울이는 것을 발견했으며, 이는 모델이 실제로 globally 정보를 통합하는 능력을 사용한다는 것을 보여줍니다. 다른 attention heads는 낮은 layer에서 일관되게 작은 attention distance를 가지고 있습니다.
이 매우 localized attention은 Transformer 이전에 ResNet을 적용하는 hybrid moodel에서 덜 뚜렷하게 나타납니다(Figure 7, right),
이는 CNN에서의 초기 convolutional layer와 유사한 기능을 제공할 수 있다는 것을 시사합니다.
또한, attention distance는 network depth와 함께 증가합니다.
전반적으로, 우리는 모델이 분류를 위해 의미론적으로 관련된 이미지 영역에 주의를 기울인다는 것을 발견합니다(Figure 6).

Self-supervision
Transformer는 자연어 처리(NLP) 작업에서 뛰어난 성능을 보입니다.
그러나 그들의 성공은 뛰어난 scalability만이 아니라 large scale self-supervised pre-training에서 크게 비롯되었습니다(Devlin et al., 2019; Radford et al., 2018).
저자들은 BERT에서 사용된 masked language modeling task을 모방하여 self-supervision을 위한 masked patch prediction에 대한 예비 탐색도 수행합니다.
self-supervised pre-training을 사용하면 우리의 더 작은 ViT-B/16 모델은 ImageNet에서 79.9%의 정확도를 달성하며, 스크래치부터의 훈련에 비해 2%의 중요한 개선을 보이지만, 아직 supervised pre-training보다 4% 뒤쳐집니다.
우리는 contrastive pre-training(Chen et al., 2020b; He et al., 2020; Bachman et al., 2019; H´enaff et al., 2020)의 탐색을 미래의 작업으로 남겨둡니다.
Conclusion
본 논문의 저자들은 image recognition에 Transformer의 직접 적용을 탐험했습니다.
Computer vision에서 self-attention을 사용하는 이전의 작업과 달리, 우리는 초기 patch extraction 단계를 제외하고 아키텍처에 image-specific inductive biases를 도입하지 않습니다.
대신 image를 patch의 연속으로 해석하고 NLP에서 사용되는 표준 Transformer encoder로 처리합니다.
이 단순하면서도 scalable 전략은 대규모 dataset에서의 pre-training과 결합할 때 놀랍게도 잘 작동합니다.
따라서 Vision Transformer는 많은 image classification dataset에서 SOTA에 도달하거나 초과하면서, pre-training하는 데 상대적으로 저렴합니다.
이 초기 결과는 격려적이지만, 여전히 많은 도전이 남아 있습니다.
하나는 ViT를 detection 및 segmentation과 같은 다른 Computer vision task에 적용하는 것입니다.
본 논문의 결과와 Carion et al. (2020)의 결과를 결합하면 이 접근법이 유망함을 나타냅니다.
또 다른 도전은 self-supervised pre-training 방법을 계속 탐색하는 것입니다.
우리의 초기 실험은 self-supervised pre-training에서 개선을 보여주지만,
self-supervised와 large-scale supervised pre-training 사이에는 여전히 큰 차이가 있습니다.
마지막으로, ViT의 추가 확장은 improved performance를 가져올 것으로 보입니다.


Reference
https://arxiv.org/abs/2010.11929
An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
While the Transformer architecture has become the de-facto standard for natural language processing tasks, its applications to computer vision remain limited. In vision, attention is either applied in conjunction with convolutional networks, or used to rep
arxiv.org
https://www.thedatahunt.com/trend-insight/vision-transformer
Vision Transformer (ViT) 란? - 정의, 원리, 구현, 응용분야
Transformer 기반 신경망은 컴퓨터 비전에 혁신을 가져왔으며, Vision Transformer가 그 대표적인 예입니다. 이 글에서 Vision Transformer의 정의, 중요성, 원리 및 실제 적용 사례에 대해 알아보실 수 있습니
www.thedatahunt.com
[논문요약] Vision분야에서 드디어 Transformer가 등장 - ViT : Vision Transformer(2020)
*크롬으로 보시는 걸 추천드립니다* https://arxiv.org/pdf/2010.11929.pdf 종합 : ⭐⭐⭐⭐ 1. 논문 중요도 : 5점 2. 실용성 : 4점 설명 : 게임 체인저(Game Changer), Convolutional Network구조였던 시각 문제를 Transforme
kmhana.tistory.com
https://robot-vision-develop-story.tistory.com/29
Inductive Bias
안녕하세요 오랜만에 글을 쓰게 되었습니다. 요즘 대학원 진학 후 이것저것 하다 보니 시간이 빨리 가네요.. 오늘 다룰 주제는 제가 최근에 공부하고 있는 Transformer에서 나온 용어에 대해서 짚어
robot-vision-develop-story.tistory.com
Inductive bias - Wikipedia
From Wikipedia, the free encyclopedia Assumptions for inference in machine learning The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not
en.wikipedia.org
stackoverflow.com/questions/35655267/what-is-inductive-bias-in-machine-learning
What is inductive bias in machine learning?
What is inductive bias in machine learning? Why is it necessary?
stackoverflow.com
EMNLP 2018 주요 논문 정리 · MinhoPark
EMNLP 2018 이번 포스트에서는 2018년 10월 31일 부터 11월 4일까지 열린 EMNLP의 주요 논문에 대한 정리를 합니다. 본 포스트는 sebastian Ruder의 블로그를 참고하여 작성하였음을 알려드립니다. EMNLP의 페
mino-park7.github.io
https://deep-learning-challenge.tistory.com/98
[ViT] Vision Transformer란?
[ViT] Vision Transformer란? CNN등장 이후, 지난 20여년간 Computer Vision 분야에서는 CNN기반 모델(AlexNet, VGGNet, ResNet, DenseNet, NasNet, EfficientNet 등)이 사용되었습니다. CNN기반 모델이 대부분의 SOTA성능을 갖던
deep-learning-challenge.tistory.com