아래 글은 Langevin Dynamics와 이를 이해하기 위한 배경 수학(특히 SDE, 확률분포, Fokker–Planck 방정식 등)를
컴퓨터공학(CS) 전공자가 조금 더 직관적으로 이해할 수 있도록 풀어서 설명한 글입니다.
갑자기 SDE가 뭐고, 확률분포 $p$ 는 무엇이며, 왜 이렇게 식이 복잡해지는지"에 대한
기본 개념 정리와 함께, Langevin Equation이 무엇이고 어떻게 샘플링에 사용되는지를 다룹니다.
앞서 설명드린 글들을 다시 한 번 짚고 넘어가기에, 더 자세한 설명이 필요하신 분은 앞 포스팅을 이용해주시면 감사하겠습니다.
Background1 : ODE to SDE
1-1. ODE는 무엇인가?
- ODE (Ordinary Differential Equation)
- "시간에 따른 변화"를 수학적으로 기술한 방정식
- e.g.,
- $\frac{dx(t)}{dt} = f(x(t), t)$
- 여기서 $x(t)$는 시간 $t$일 때의 어떤 상태 또는 값, $f$는 변화율을 정해주는 함수
- 해석:
- $x$가 시간이 지날 때 어떻게 변하는가? 라는 질문을 $\frac{dx}{dt}$로 나타낸 것.
- 예시:
- $\frac{dx}{dt} = -x$ => $x(t) = x(0) e^{-t}$
- "시간에 따른 변화"를 수학적으로 기술한 방정식
1-2. SDE 는 무엇인가?
하지만, 현실 세계 (또는 확률 모델)에는 Noise, 즉 무작위성이 들어가는 경우가 많습니다.
이를 반영하기 위해, ODE에 확률적 항(Stochastic Term)을 추가한 것이 SDE (Stochastic Differential Equation)입니다.
- SDE의 전형적 형태:
- $dX_t = f(X_t, t)dt + g(X_t, t)dW_t$
- $dX_t$: "아주 작은 시간 $\Delta t$" 동안 $X$가 어떻게 변하는가
- $f(X_t, t)$: 결정론적 변화율 ($i.e.,$ "Drift"라 부름)
- $g(X_t, t) dW_t$: 무작위 (noise) 항으로, 주로 $W_t$는 Wiener Process (브라운 운동)
- Wiener Process ($W_t$)란 ?
- "연속적으로 누적되는 무작위"라고 보시면 됩니다.
- 실제 통계학에서 Brownian motion이라 부르는 표준 Gaussian 무작위가 시작 축에 따라 조금씩 추가되는 개념
- 의미:
- 우리 시스템 (즉, 상태 $X$)는 시간에 따라 어느 정도 결정론적으로 변하지만, 동시에 무작위 충격(Noise)도 받아서 불규칙하게 움직인다.
- $dX_t = f(X_t, t)dt + g(X_t, t)dW_t$
Distribution 관점: Fokker-Planck Equation
위에서 언급한 SDE는 "하나의 샘플 경로(Trajectory)"가 어떻게 변하지는지를 보여줍니다.
하지만, 때로는 "전체 확률 분포가 시간에 따라 어떻게 변하는지"가 더 중요할 때가 있습니다.
2-1. 확률 분포 $p(x,t)$
- $p(x,t)$: 특정 시간 $t$에, 상태(공간) $x$ 근처에 있을 확률 (또는 확률 density)
- 예:
- $p(x,0)$ = 초기 시점에서의 분포
- 시간이 지남에 따라 $p(x,t)$가 변함
2-2. Fokker-Planck Equation
- dFokker-Planck(FPE)는 다음과 같은 편미분방정식 (PDE) (1차원 단순형)
- $\frac{\partial t p(x,t)}{\partial t} = \frac{\partial}{\partial x} \left[f(x)p(x,t) \right] + \frac{1}{2} \frac{\partial^2}{\partial x^2} [g^2(x)p(x,t)]$
- 이 식은
- SDE에서 말하는 Drift 항 $f$, 디퓨저항 $g$가 주어졌을 때, 전체 분포 $p(x,t)$가 어떻게 변하는가를 기술합니다.
- 차이점:
- SDE: $X_t$ 하나의 경로 (실현값)
- FPE: $X$가 전체적으로 (무작위) 분포를 이룬다면, 그 분포가 시간에 따라 어떻게 변하느냐
2-3. Stationary Distribution
- 정의:
- 시간이 지나도 더 이상 안 변하는 분포
- 즉,
- $\frac{\partial p_{stationary}(x)}{\partial t} = 0$
- FPE에서 $\partial p / \partial t = 0$을 만족하는 해결책을 찾으면, 그 분포가 Stationary (정상 상태) 입니다.
- 물리학에서는 이게 조종 Boltzmann 분포 형태 ($ \propto exp(- U(x)) $)가 됩니다.
- 머신 러닝에서는 이걸 Data Distribution으로 만들고 싶은 경우가 있습니다.
Langevin Equation
3-1. 물리학에서의 출발
Langevin Dynamics는 물리학에서 "브라운 운동을 하는 입자"를 모델링할 때 자주 쓰이는 SDE 형태입니다.
가장 단순화된 1차원 식 (마찰 계수 등 생략 가능)은:
$dx (t) = - \Delta U(x(t)) dt + \sqrt{2} dw(t)$
- $\Delta U(x)$: "포텐셜 에너지 $U$의 기울기" (다차원이라면 vector)
- $\sqrt{2}dw(t)$ 가우시안 무작위 (브라운 운동) 항
- 마이너스 항: 포텐셜이 낮은 곳으로 이동하려는 힘을 의미
3-2. 왜 Stationary Distribution이 $e^{-U(x)}$가 되나?
이 Langevin Equation에 대응되는 FPE를 풀어보면 (또는 물리학 공식 참고),
$p_{stationary}(x) \propto exp(-U(x))$
즉, 시간이 충분히 흐르면 ("무한히 길게 시뮬레이션하면") 샘플들이 $exp(-U(x))$라는 분포에 따라 분포하게 된다.
이는 물리학에서는 Boltzmann 분포 (열역학적으로 안정된 상태)라 부릅니다.

머신러닝 관점: Score Function과 연결
4-1. $U(x) = - \log p_{data} (x)$로 두면?
만약 우리가 데이터 분포 $p_{data} (x)$를 알고 있다고 가정해 보겠습니다.
그렇다면,
$U(x) = - \log p_{data}(x)$
즉, 포텐셜 $U$를 $- \log p_{data}$ 형태로 설정하면,
$exp(-U(x)) = exp(\log p_{data} (x)) = p_{data}(x)$
결과적으로, Langevin Equation을 Sufficiently 오래 시뮬레이션하면, Sample들이 $p_{data} (x)$에 따르게 됩니다!
4-2. Score Function
- Score Function
- $\Delta \log p_{data} (x)$
- "데이터 분포의 로그를 취한 뒤, $x$에 대한 Gradient 즉, 기울기를 구한 것"
- Langevin Equ.에서의 Drift 항은
- $- \Delta U(x)$인데, $U(x) = - \log p_{data}$라면
- $-\Delta U(x) = -\Delta [-\log p_{data}(x)] = \Delta \log p_{data}(x)$
- 즉, "Score Function"이 곧 Langevin Dynamics에서 입자를 끌어가는 또는 밀어내는 힘의 방향이 됩니다.
- $- \Delta U(x)$인데, $U(x) = - \log p_{data}$라면
- $\Delta \log p_{data} (x)$
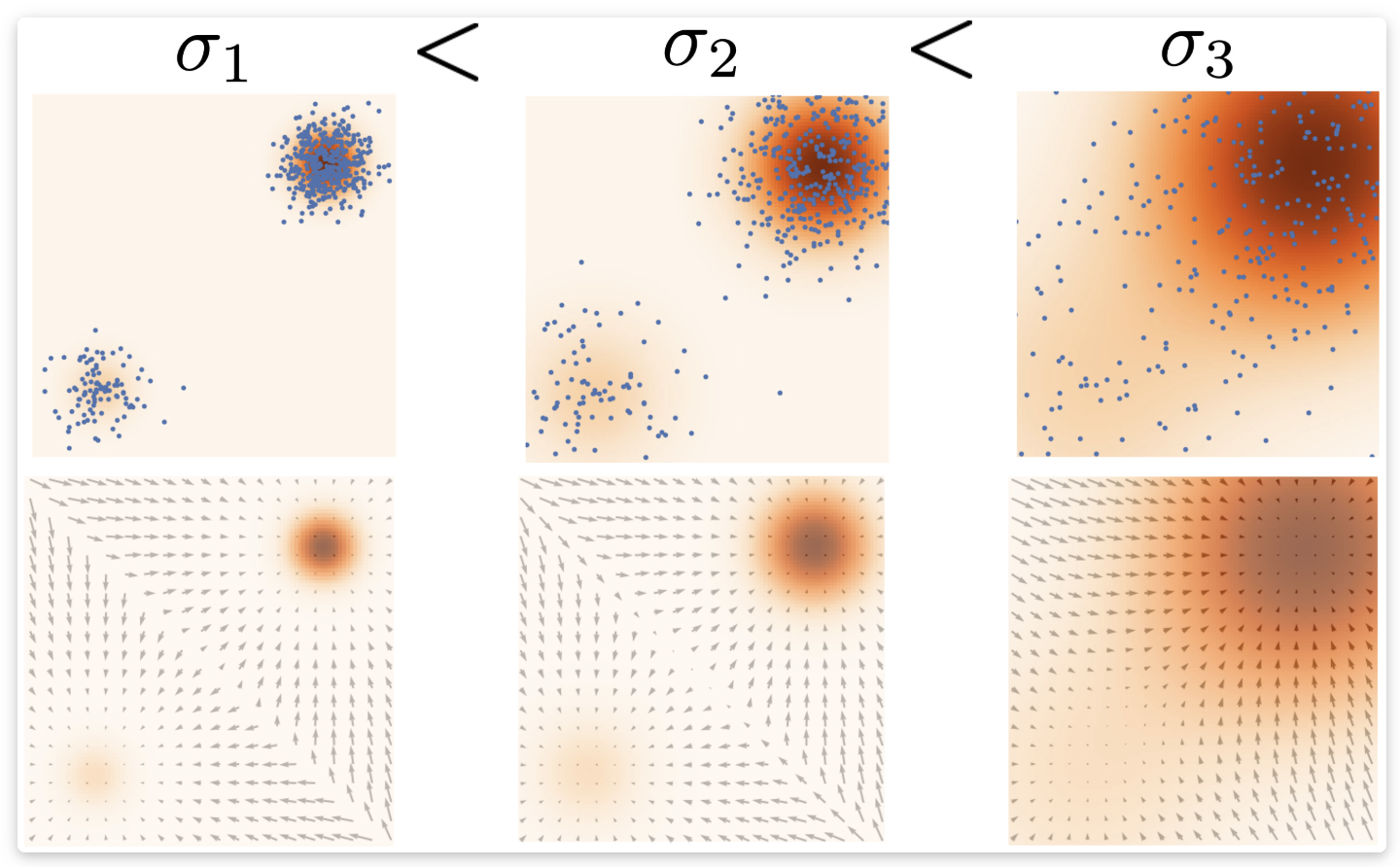
어떻게 실제 Sampling에 사용하는가?
5-1. 알고리즘
- 초기 샘플 $x(0)$을 아무 데서나 뽑아둔다 (e.g., Gaussian Noise)
- Langevin Equation (또는 이를 수치화한 오일러-마루야마 기법 등)을 반복 수행:
- $x_{n+1} = x_n + \eta \Delta \log p_{data}(x_n) + \sqrt{2\eta} \epsilon_n$,
- 여기서 $\epsilon_n \sim \mathcal{N}(0, I)$ 무작위, $\eta$는 작은 스텝 크기 (learning rate와 유사 개념)
- 충분히 많이 반복하면, 최종적으로 $x_n$ 들이 $p_{data}$분포에 가까워짐
- 이 과정을 Langevin Dynamics를 통한 샘플링이라 부르며,
- Score Function을 알면 (또는 추정할 수 있다면) 실제 데이터 분포의 샘플을 생성할 수 있다는 원리가 된다.
5-2. Diffusion Model과의 연계
- 최근 Diffusion Model / Score-based Generative Model (Song et al.)에서는,
- Forward Process: 데이터에 점점 노이즈 주입
- Reverse Process: 노이즈에서 점점 데이터로 복원
- 이 역방향 과정을 Langevin Equation (또는 유사한 SDE)로 볼 수 있음
- 결과적으로,
- Score Function ($\Delta \log p_{data}$)을 신경망으로 학습
- -> Langevin Dynamic (역방향 SDE)를 수치적으로 돌려서
- -> 데이터처럼 보이는 샘플 생성
쉬운 예시
예제: 1차원 정규 분포 $\mathcal{N}(0,1)$
- 목표 분포: $p_{data} (x) = \frac{1}{\sqrt{2\pi}} e^{-x^2 / 2}$
- Score Function: $\Delta \log p_{data}(x) = -x$
- ($\log p_{data}(x) = -\frac{x^2}{2}- \frac{1}{2} \log(2\pi)$)
- Langevin Equation:
- $dx = -\Delta U(x) dt + \sqrt{2} dw (t) = - (-x) dt + \sqrt{2}dw(t) = x ~dt +\sqrt{2}dw (t)$
- (단, ($U(x) = - \log p_{data}(x) = \frac{x^2}{2} + \text{const}$))
- 이 식을 오랫동안 시뮬레이션하면, 샘플들이 $\mathcal{N}(0,1)$에 근접
- 쉽게 말해, 한 없이 랜덤하면서도 $x=0$ 주변으로 잡아당기는 힘이 작용
- 결국 정규분포를 따라가게 됨.
최종 정리
- SDE(Stochastic Differential Equation): ODE + 랜덤 노이즈 항
- Fokker-Planck Equation: SDE 전체 "분포"가 시간에 따라 어떻게 변하는지 보여주는 PDE
- Stationary Distribution: 시간이 지나도 변하지 않는 분포
- Langevin Equation: 특정 형태의 SDE로, "$-\Delta U$"에너지 기울기와 "Gaussian Noise"로 구성됨
- 물리학 : Boltzmann 분포 $\propto e^{-U}$ 유도
- 머신러닝 : $U(x) = -\log p_{data} (x)$라 두면, => $p_{data}$에 수렴
- Sampling
- 점진적으로 역방향 SDE (Langevin) 시뮬레이션
- 노이주로 시작한 샘플이 최종적으로 데이터 분포를 따름
- Score-based Generative Model 핵심 로직
Ref
https://yang-song.net/blog/2021/score/
https://process-mining.tistory.com/210?category=800092
Song, Y. & Ermon, S. (2019). “Generative Modeling by Estimating Gradients of the Data Distribution.” NeurIPS.
Song, Y. et al. (2021). “Score-Based Generative Modeling through Stochastic Differential Equations.” ICLR.
'Artificial Intelligence > Computer Vision' 카테고리의 다른 글
| [Diffusion Models] 확산 모델 이해하기 (4) - Energy-Based Model (0) | 2025.01.30 |
|---|---|
| [Diffusion Models] 확산 모델 이해하기 (5) - Score matching (0) | 2025.01.29 |
| [Diffusion Models] 확산 모델 이해하기 (2) - Euler's Method (0) | 2025.01.23 |
| [Diffusion Models] 확산 모델 이해하기 (1) - ODE, SDE and Markov process, Wiener process (0) | 2025.01.22 |
| [Computer Vision] Hands-On Generative AI with Transformers and Diffusion Models (0) | 2023.09.05 |