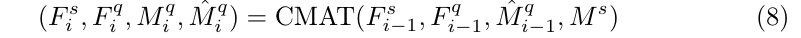abstract:: Medical image segmentation has made significant progress in recent years. Deep learning-based methods are recognized as data-hungry techniques, requiring large amounts of data with manual annotations. However, manual annotation is expensive in the field of medical image analysis, which requires domain-specific expertise. To address this challenge, few-shot learning has the potential to learn new classes from only a few examples. In this work, we propose a novel framework for few-shot medical image segmentation, termed CAT-Net, based on cross masked attention Transformer. Our proposed network mines the correlations between the support image and query image, limiting them to focus only on useful foreground information and boosting the representation capacity of both the support prototype and query features. We further design an iterative refinement framework that refines the query image segmentation iteratively and promotes the support feature in turn. We validated the proposed method on three public datasets: Abd-CT, Abd-MRI, and Card-MRI. Experimental results demonstrate the superior performance of our method compared to state-of-the-art methods and the effectiveness of each component. Code: https://github.com/hust-linyi/CAT-Net.
Annotations
Few Shot Medical Image Segmentation with Cross Attention Transformer
Abstract
[!Highlight]
However, manual annotation is expensive in the field of medical image analysis, which requires domain-specific expertise.
Comment:
Challenge in Medical Imaging
[!Highlight]
In this work, we propose a novel framework for few-shot medical image segmentation, termed CAT-Net, based on cross masked attention Transformer.
Comment:
CAT-Net
[!Highlight]
Our proposed network mines the correlations between the support image and query image, limiting them to focus only on useful foreground information and boosting the representation capacity of both the support prototype and query features.
Comment:
query image and support image
[!Highlight]
Most of the existing methods follow a fullysupervised learning paradigm, which requires a considerable amount of labeled data for training.
However, the manual annotation of medical images is timeconsuming and labor-intensive, limiting the application of DL in medical image segmentation.
Comment:
challenge of Medical imaging
[!Highlight]
Specifically for the 3D volumetric medical images (e.g., CT, MRI), the manual annotation is even more challenging which requires the annotators to go through hundreds of 2D slices for each 3D scan.
Comment:
specific challenge of Medical imaging
[!Highlight]
To address the challenge of manual annotation, various label-efficient techniques have been explored, such as self-supervised learning [15], semi-supervised learning [30,31], and weakly-supervised learning [11].
Comment:
various label-efficient technique
[!Highlight]
Despite leveraging information from unlabeled or weakly-labeled data, these techniques still require a substantial amount of training data [21,16], which may not be practical for novel classes with limited examples in the medical domain.
Comment:
substantial amount of training data
[!Highlight]
Considering the hundreds of organs and countless diseases in the human body, FSL brings great potential to the various medical image segmentation tasks where a new task can be easily investigated in a data-efficient manner.
Most few-shot segmentation methods follow the learning-to-learn paradigm, which aims to learn a meta-learner to predict the segmentation of query images based on the knowledge of support images and their respective segmentation labels.
how to learn the meta-learner [17,26,14]; and (2) how to better transfer the knowledge from the support images to the query images [23,27,18,13,5,25].
Comment:
two aspects of existing few-shot segmentation methods
[!Highlight]
Despite prototype-based methods having shown success, they typically ignore the interaction between support and query features during training.
Comment:
prototype-based methods' limitation
[!Highlight]
In this paper, as shown in Fig. 1(a), we propose CAT-Net, a Cross Attention Transformer network for few-shot medical image segmentation, which aims to fully capture intrinsic classes details while eliminating useless pixel information and learn an interdependence between the support and query features.
Comment:
CAT-Net
[!Highlight]
Different from the existing FSS methods that only focus on the single direction of knowledge transfer (i.e., from the support features to the query features), the proposed CAT-Net can boost the mutual interactions between the support and query features, benefiting the segmentation performance of both the support and query images.
Comment:
the difference between the existing FFS methods and CAT-Net
[!Highlight]
Additionally, we propose an iterative training framework that feed the prior query segmentation into the attention transformer to effectively enhance and refine the features as well as the segmentation.
Comment:
iterative training framework
2 Method
2.1 Problem Definition
[!Image]
Image
Comment:
figure 1
[!Highlight]
the commonly used episode training approach is employed [29].
Comment:
PANet: Few-shot image semantic segmentation with prototype alignment
[!Highlight]
Each trainig/testing episode (Si, Qi) instantiates a N -way K-shot segmentation learning task.
Comment:
instantiating
[!Highlight]
Specifically, the support set Si contains K samples of N classes, while the query set Qi contains one sample from the same class. The FSS model is trained with episodes to predict the novel class for the query image, guided by the support set. During inference, the model is evaluated directly on Dtest without any re-training. In this paper, we follow the established practice in medical FSS [7,15,20] that consider the 1-way 1-shot task.
Comment:
training and testing procedure in CAT-Net
2.2 Network Overview
[!Highlight]
1) a mask incorporated feature extraction (MIFE) sub-net that extracts initial query and support features as well as query mask;
Comment:
main component 1
[!Highlight]
2) a cross masked attention Transformer (CMAT) module in which the query and support features boost each other and thus refined the query prediction;
Comment:
main component 2
[!Highlight]
3) an iterative refinement framework that sequentially applies the CMAT modules to continually promote the segmentation performance.
Comment:
main component 3
2.3 Mask Incorporated Feature Extraction
[!Highlight]
The Mask Incorporate Feature Extraction (MIFE) sub-net takes query and support images as input and generates their respective features, integrated with the support mask.
Comment:
MIFE's feature
[!Highlight]
Specifically, we first employ a feature extractor network (i.e., ResNet-50) to map the query and support image pair Iq and Is into the feature space, producing multi-level feature maps F q and F s for query and support image, respectively.
Next, the support mask is pooled with F s and then expanded and concatenated with both F q and F s.
[!Highlight]
Finally, the query feature is processed by a simple classifier to get the query mask.
Comment:
simple classifier
2.4 Cross Masked Attention Transformer
[!Highlight]
1) a self-attention module for extracting global information from query and support features;
Comment:
main component 1
[!Highlight]
2) a cross masked attention module for transferring foreground information between query and support features while eliminating redundant background information
Comment:
main component 2
[!Highlight]
3) a prototypical segmentation module for generating the final prediction of the query image.
Comment:
main component 3
[!Highlight]
Self-Attention Module
[!Highlight]
the initial features are first flattened into 1D sequences and fed into two identical self-attention modules.
[!Image]
Image
Comment:
formula 1
[!Image]
Image
[!Highlight]
The output feature sequence of the selfattention alignment encoder is represented by Xq ∈ RHW ×D and Xs ∈ RHW ×D for query and support features, respectively.
Specifically, given the query feature Xq and support features Xs from the aforementioned self-attention module, we first project the input sequence into three sequences K, Q, and V using different weights, resulting in Kq, Qq, V q, and Ks, Qs, V s, respectively. Taking the support features as an example, the cross attention matrix is calculated by:
Similar to self-attention, the support feature is processed by MLP and LN layer to get the final enhanced query features F s 1 . Similarly, the enhanced query feature Fq 1 is obtained with foreground information from the query feature.
where K is the number of support images, and ms (k,x,y,c) is a binary mask that indicates whether pixel at the location (x, y) in support feature k belongs to class c.
where cos(·) denotes cosine distance, α is a scaling factor that helps gradients to back-propagate in training. In our work, α is set to 20, same as in [29].
Then, the second threshold ˆ τ is set to 0.4 to obtain the dilated query mask ˆ M q, which is used to generate the enhanced query feature F q 2 in the next iteration.
We further propose a new validation setting (setting II) that takes every image in each fold as a support image alternately and the other images as the query.
Effectiveness of CMAT Block: To demonstrate the importance of our proposed CAT-Net in narrowing the information gap between the query and supporting images and obtaining enhanced features, we conducted an ablation study.
Influence of Iterative Mask Refinement Block: To determine the optimal number of iterative refinement CMAT block, we experiment with different numbers of blocks.