
[Training Neural Networks] part 2
🧑🏻💻용어 정리
Gradient Descent
MNIST handwritten digit classification
Back propagation
Computational graph
sigmoid
tanh
ReLU
Batch Normalization
Gradient Descent
- loss function을 최소화하는 Gradient 값을 찾는다.
- 그러나 곧이 곧대로 gradient descent 를 사용한다면 비효율적으로 사용될 수 있다.
- 그러므로 여러 가지 Gradient Descent Algorithm 들이 존재합니다.
MNIST handwritten digit classification
-> mse loss 적용 예시
목적 : 학습을 통해 각 layer 들에 존재하는 Parameter 들.
- 학습 Data에 대해서 forward propagation을 수행.
- parameter들은 Random initialization에서부터 시작.
- 먼저, 예측 값들은 입력 Data의 ground truth 값과 상이하다.
- 계속해서 이 차이를 줄이는 방향을호 손실함수를 정의한다.
- 손실함수로부터 편미분 값을 구하고, 편미분 값을 통해 parameter 들을 update해야합니다.
결국 Loss function에 대한 편미분을 구하는 과정은 마치 neural network에서의 forward propagation의 반대 방향으로 layer 별로 순차적인 계산을 수행하게 되는 back propagation이라는 과정을 통해 Parameter 들의 gradient 값 or loss function의 편미분 값을 계산할 수가 있습니다.
Neural Network 의 순차적인 계산과정은 하나의
computational graph
라는 형태로 나타낼 수 있습니다.

처음의 Parameter까지 편미분 과정을 거쳐 올라가게 된다면,
처음의 parameter 값에, learning rate 값과 Gradient 값을 더한 것을 빼서 parameter 값을 update합니다.
중간 과정 중의 결과물로서 Gradient 값이 계산 되지만 직접적인 gradient descent에는 사용되지 않는 그러한 노드들입니다.
하나의 함수에 대한 결과물로 나온다면, gradient descent 과정에서 하나의 함수를 쪼개어 하나씩의 계산과정을 하는 대신 하나의 함수를 편미분하여 구할 수 있게됩니다.
Sigmoid Activation

입력 신호를 잘 선형 결합해서 만들어진 값에 hard threshold를 적용해서 최종 출력 값을 내어줬던 것을 부드러운 형태의 함수로 근사화한 것입니다.
- 선형 결합의 결과가 마이너스 무한대부터 무한대까지 가질 수 있는 이러한 값들을 0에서 1사이의 값으로 mapping 시켜줍니다.
- 이 값을 logistic regression의 경우 positive class에 대응하는 예측된 확률 값으로 해석하는 경우가 많이 있습니다.
- Back propagation에서 해당 sigmoid function을 편미분 시 0에서 1/4 사이의 값을 가지므로, 이 값이 곱해져 입력 값의 Gradient 가 결정되고, 이는 1보다 많이 작은 값이므로 sigmoid node를 back propagation 할 때마다 gradient 값이 점차 작아지는 양상이 보이게 됩니다.
- 여러 Layer에 있는 Sigmoid node에 대해서 Back propagation할 때마다 gradient 값이 계속해서 깎여 나갑니다.
- 그래서 Gradient가 0에 가까워지는 문제점이 야기하게 됩니다.
- 결국 이것으로 Back Propagation 했을 때, 앞쪽 Layer에 있는 parameter들에 도달하는 gradient 값이 일반적으로 굉장히 작은 값을 얻게 되고 learning rate를 사용했을 때, 앞쪽 parameter들의 Gradient 값이 작음으로 인해 parameter들의 update가 거의 일어나지 않게 되는 현상이 발생합니다.
- 그러므로, Neural network의 전체적인 학습이 느려지게 됩니다.
- 이를 Gradient Vanishing이라고 합니다.
- 이러한 문제점을 해결하기 위해서 다음과 같은 Activation function이 제안됩니다.
Tanh Activation

tanh라는 함수를 sigmoid 활성 함수 대신에
- 마이너스 무한대부터 무한대까지의 범위를 마이너스 1부터 1사이의 범위로 Mapping 시켜주게 됩니다.
- 학습에 있어 속도가 더 빠릅니다.
- 이 tanh activation function을 편미분하면 0에서 1/2 사이의 값이 나오므로 Back propagation할 때마다 gradient 값이 훨씬 깎입니다.
- 그래서 Gradient vanishing 문제를 여전히 가지게 됩니다.
- layer들이 많이 쌓였을 때, gradient vanishing 문제를 근본적으로 제한할 수 있는 다음과 같은 Activation function이 존재합니다.
ReLU (Rectified Linear Unit)
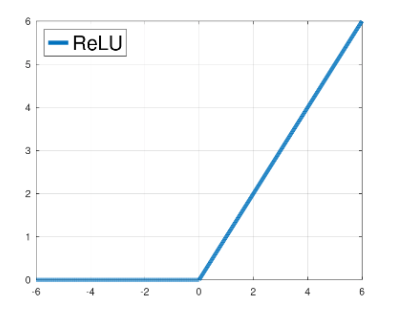
- 선형결합으로 나온 결과값이 마이너스 무한대부터 무한대까지의 값을 가질 때, 0보다 작은 경우는 0으로, 0 보다 큰 경우는 그 값을 곧이곧대로 내어주는 형태입니다.
- ReLU 함수는 sigmoid나 tanh function에 비해 더 빠르게 계산될 수 있다는 장점이 있습니다.
- 선형결합으로 나온 값이 음수라면 gradient가 0이 된다는 단점이 있습니다.
- 그러나 gradient vanishing 문제를 해결할 수 있는 측면에서 장점이 있습니다.
- 그러므로, Lyaer가 많이 쌓여져 있을 때 Neural Network의 학습을 훨씬 더 빠르게 만들어줄 수 있습니다.
Batch Normalization
- 학습의 최적화를 돕는 layer
- Tanh, sigmoid 등 중앙 정도의 값이 아닌 Satureted 된 값에 있어서 gradient 값이 0에 수렴하게 되는 문제가 발생합니다.
- 그렇다면 Back Propagation 과정에서 학습 시그널을 줄 수 없는 상황이 될 수가 있습니다.
- 극단적인 경우 선형결합의 결과가 모두 음의 값이 나올 경우 ReLU function에서는 gradient가 무조건 0이 되기 때문에 해당 node가 학습이 전혀 진행되지 않게 되는 문제점이 존재합니다.
- forward propagation 과정에서 선형결합의 값이 0주변의 값으로 이루어진다면 학습에 용이할 것입니다.
- 이것이 batch normalization의 기본적인 아이디어가 됩니다.
- 어떤 Mini batch가 주어져 data가, mini batch size가 10이라고 하면, 해당 값들이 tanh의 입력으로 주어지기 전에,
평균이 0, 분산이 1인 값을 Normalization한다면 tanh의 입력으로 주어지는 값의 대략적인 범위를 0을 중심으로 하는 그러한 분포로 만들 수 있을 것입니다. - 그 값들의 변화 폭이 너무 작으면 tanh의 Output 또한 변화 자체가 너무 작아서 data item들 간의 차이를 Neural network가 구분하기 어려울 것입니다.
- 그 값들의 변화 폭이 너무 크면 적정한 영역의 값으로 컨트롤에 어려움이 있게 됩니다.
- 이 과정은 fully-connected layer 혹은 선형 결합을 수행한 이후에 활성 함수로 들어가기 직전에 수행됩니다.

그러나 data의 의미가 중요한 경우에는 위와 같은 BN(Batch Normalization) 과정은 우리의 data를 잃어버리게 만드는 과정이라고 볼 수 있습니다.
이러한 잃어버린 정보를 원하는 정보로 복원할 수 있게끔하는 그런 두 번째 단계가 BN의 두 번째 단계가 됩니다.
그러므로 BN 과정 이후에는 해당 Data가 가지는 고유의 평균과 분산 또한 복원해낼 수 있는 능력을 부여해 주게 된 것입니다.
추가로 Gradient Vanishing 문제를 효과적으로 해결할 수 있는 이런 좋은 장치가 되는 것입니다.
'Artificial Intelligence > Deep Learning' 카테고리의 다른 글
| [XAI] 설명가능한 AI (Explainable AI) (0) | 2023.01.26 |
|---|---|
| [Convolutional Neural Networks and Image Classification] Part 3 (0) | 2023.01.24 |
| [Deep Neural Network] part 1 - 2 (0) | 2023.01.22 |
| [Deep Neural Network] part 1 - 1 (0) | 2023.01.22 |
| [Machine Learning] 신경망 기초 1 (0) | 2023.01.17 |







