
[ERP Decoding] EEG recording & Preprocessing
2023. 2. 12. 23:18
🧠 Key Words
EEG recording
ICA
ERP Info
SVM
hyperplane
EEG recording
- Number of electrodes
- Down-sampling
- Referencing
- Bandpass filtering
- Removing protions of EEG containing large muscle artifacts and extreme voltage offsets (can be identified by visual inspection)
- ICA (Independent Component Analysis)
- remove components associated with eye-movements and blinks
- 요새는 EEG recording과 eye tracker를 동시에 사용하여 pixation 벗어난 것은 어느 정도 제외하는 방법을 사용한다.
- Segmenting continuous EEG
아래 사이트에서 ERP Decoding에 대한 정보를 얻을 수 있다.
ERP Info
ERPLAB Toolbox is a free, open-source Matlab package for analyzing ERP data. It is tightly integrated with EEGLAB Toolbox, extending EEGLAB’s capabilities to provide robust, industrial-strength tools for ERP processing, visualization, and analysis. See
erpinfo.org
- 직접 scalp map을 그린 후 image를 decoding하는 것이 아니라, 각각의 Indiviual electrode site에 있는 EEG의 pattern을 가지고 decoding한다.
- EEG data는 시간별로 continuous하기 때문에 시간 별로 나타낼 수 있다.
- Decoding을 위해선 data structure가 Origanized 되어 있어야 한다.
- The same decoding analysis is done at each time point separately.
- Decoding은 time point 마다 반복이 된다.
- single data point에서 ERP averaging을 한다.
Preprocessing 후 averaging을 한다.
block으로 나누게 된다.
- 각각의 scalp map 마다 classifier에 집어 넣는다.
- How does the SVM classifier work ?
- How do we guess about the feature from the scalp distribution?
- 여러 개의 electrode sites 중 2개만 있다고 가정한다면,
- left, right로 예시를 들면, feature ERP 들이 어떻게 분포 되어 있는지 left, right로 나눠서 본다.
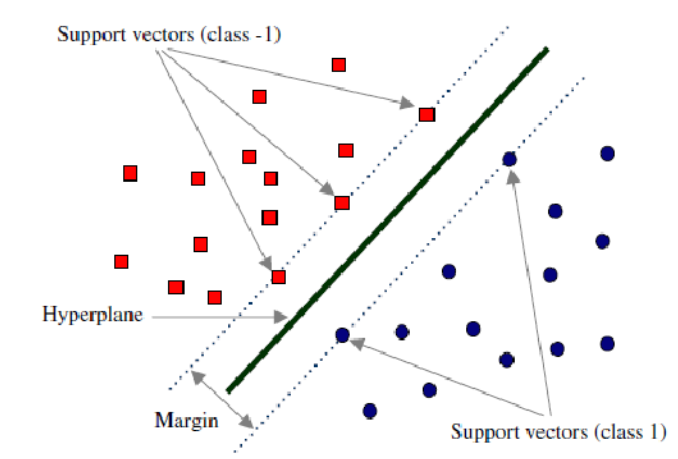
- 해당 Data 들에 대해서 random하게 추출한 데이터 분포를 SVM에 의해 Optimal hyperplane을 그려서 나눈다.
- 이 Optimal hyperplane을 찾는 과정이 Training이 됩니다.
- 2-dimensional space에서 Data를 뿌린 후, feature 정보 하나를 나머지 features 들에 대해서 구분짓는 것이다.
- 이 과정을 fitting 또는 running이라고 볼 수 있는 것이다.
- 이 과정이 electrode sites의 개수-dimensional space에서 일어나기 때문에 상상하기 어렵다.
- 학습 과정 중 실제로 너무 떨어져 있는 Data의 경우에 있어, 같은 feature와 너무 떨어져 있는 경우에, prediction은 incorrect classification이 되고, 실제 correct한 것은 correct classification이 된다.
- 아래와 같은 binary classification (A or B)으로는 현재 feature의 개수만큼의 것을 구분지을 수 있을까?
- 기본적으로 SVM은 binary classifier이므로 다른 절차가 필요하다.
- feature의 개수만큼의 SVMs 들을 training 하는 것이다.
- feature의 개수만큼의 hyperplane을 생각해 볼 수 있다.
- 주어진 time point의 feature 개수만큼의 training data에 대해서 feature 개수만큼의 classifier가 fitting하게 되고,
- 각 feature 별로 각 feature와 나머지 feature 들을 구분 짓는 hyperplane을 찾는다.
- 이 과정이 Training이다.
- 주어진 data에 대해 feature의 개수 만큼의 SVM에 대해 다 test를 한다.
- 각각에 대해 어떤 feature or the other 에서 가장 잘 구분이 되는 것을 평가하여 확률을 매긴다.
- 어떤 classifier가 주어진 Data를 가장 잘 분류하느냐? 에 대한 것이다.
- 어떤 classifier의 확률이 가장 높느냐?
- penalty가 가장 낮은 classifier를 가지고 prediction을 한다.
- 각 feature 별로 해당되는 Prediction이 무엇인지 계산하고, 예측된 feature label과 실제 label을 비교함으로써 Decoding accuracy를 구할 수 있습니다.
- Each of feature's count SVMs produce 'loss' value for a given test data point, and the feature label with the smallest loss value is assigned to the data.
'Biology > EEG' 카테고리의 다른 글
| [ERP Decoding] ERP Decoding procedure (0) | 2023.02.11 |
|---|---|
| [ERP Decoding] The step toward mind reading (0) | 2023.02.10 |
| [ERP Decoding] EEG - Electronencephalography (0) | 2023.02.07 |






