
https://learning.oreilly.com/library/view/hands-on-generative-ai/9781098149239/cover.html
Hands-On Generative AI with Transformers and Diffusion Models
- Selection from Hands-On Generative AI with Transformers and Diffusion Models [Book]
www.oreilly.com
본 포스팅이 문제가 될 시 삭제하겠습니다.
본 Hands-On Generative AI with Transformers and Diffusion Models에 대한 Ebook을 hands-on 해보고 리뷰를 남기려합니다.
최근 diffusion models과 stable diffusion에 대한 개념을 잘 담고 있다고 생각하여 선정하였습니다.

시작에 앞서 위와 같이 저자들의 정보와 출처를 남깁니다.
그럼 시작합니다.
Hands-On Generative AI with Transformers and Diffusion Models
Chapter 1. Diffusion Models
최신 Diffusion models의 remarkable한 결과로 굉장히 많은 연구가 이루어지고 있습니다.
한편, 해당 ebook에서는 diffusion models, stable diffusion 등의 개념에 대해 설명하고 있습니다.
그리고 GLIDE, DALL-E-2, Imagen 등에 대해 언급하며 최신 동향을 알립니다.
The Key Insight: Iterative Refinement
실습에 대한 코드 및 설명은 아래와 같습니다.
pip install diffusersfrom diffusers import DDPMPipeline
import torch
# Load the pipeline
image_pipe = DDPMPipeline.from_pretrained("google/ddpm-celebahq-256")
device = 'cuda' if torch.cuda.is_available() else 'cpu'
image_pipe.to(device);
# Sample an image
image_pipe().images[0]

해당 코드는 Hugging Face의 diffusers 라이브러리를 사용하여 DDPM (Denoising Diffusion Probabilistic Model)을 사용하여 이미지를 생성하는 과정을 보여줍니다.
모델이 이미지를 생성하는 동안 무슨 일이 일어나는지 더 잘 이해하기 위해 샘플링 과정을 단계별로 재현할 수 있습니다.
우리는 샘플 $x$ 를 무작위 노이즈로 초기화한 후 모델을 통해 30단계 동안 실행합니다.
오른쪽에서는 특정 단계에서 최종 이미지가 어떻게 보일 것인지에 대한 모델의 예측을 볼 수 있습니다.
초기 예측이 특별히 좋지 않다는 점에 주목하세요!
최종 예측된 이미지로 바로 jump하는 대신에, 우리는 prediction의 방향으로 $x$ 를 조금 수정합니다(왼쪽에 표시됨).
그런 다음 이 새롭고 약간 개선된 $x$를 다음 단계를 위해 다시 모델에 투입합니다.
이렇게 하면 조금 더 개선된 예측이 나올 것이고, 이를 사용해 $x$를 조금 더 업데이트할 수 있습니다. 충분한 단계가 지나면, 모델은 꽤 현실적인 이미지를 생성할 수 있습니다.
그렇다면 다음과 같은 결과를 볼 수 있습니다.
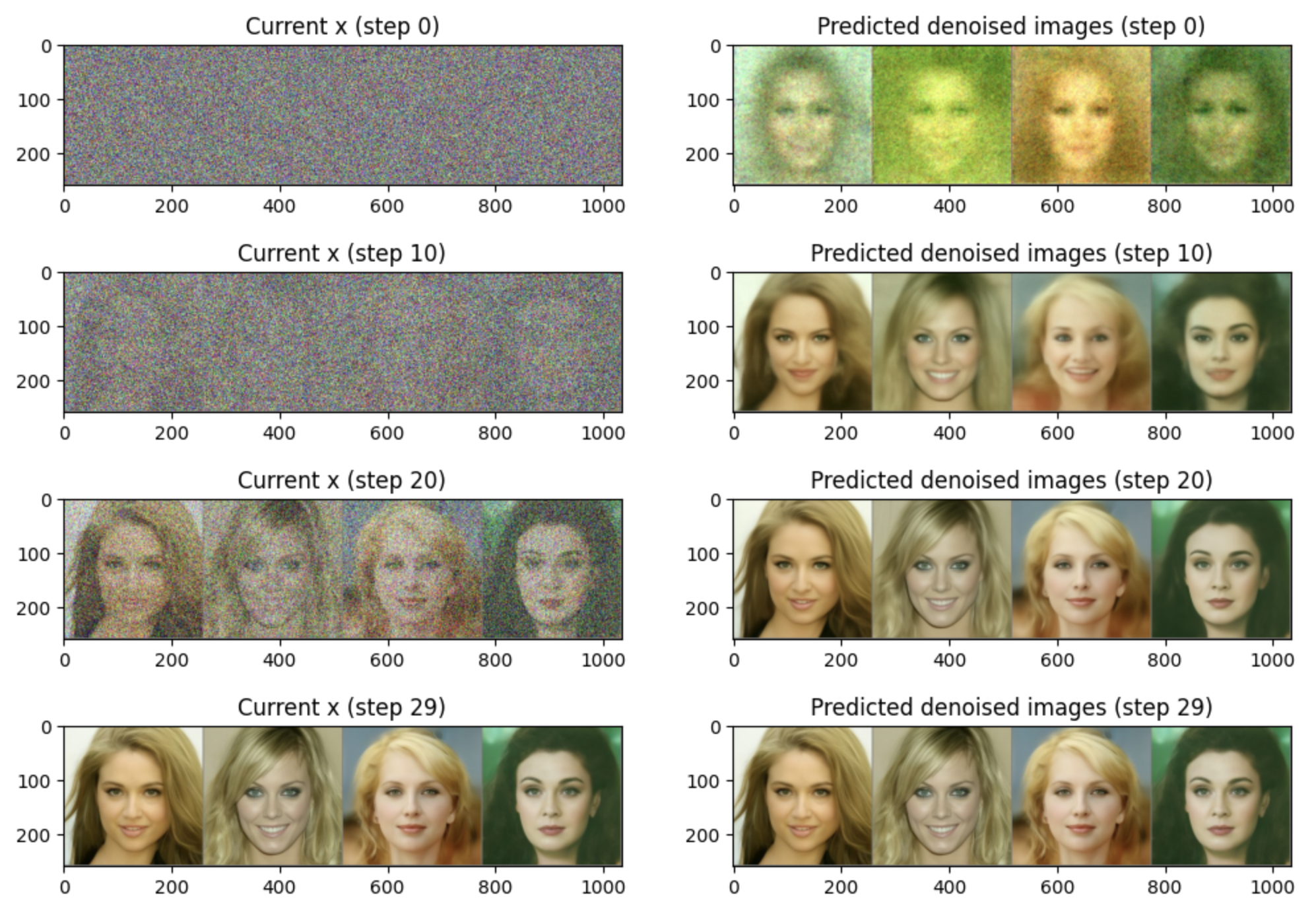
이 'corrupted' 입력을 점진적으로 개선하는 방법을 학습하는 핵심 아이디어는 다양한 작업에 적용될 수 있습니다. 이 장에서는 unconditional image generation에 중점을 둘 것입니다.
즉, 학습 데이터와 유사한 이미지를 생성하는 것으로, 이 생성된 샘플이 어떻게 보일지에 대한 추가적인 제어 없이 진행됩니다.
확산 모델은 오디오, 비디오, 텍스트 등에도 적용되었습니다. 대부분의 구현이 여기서 다룰 'denoising' 접근 방식의 변형을 사용하는 반면, 다양한 종류의 'corruption'과 함께 반복적인 개선을 활용하는 새로운 접근 방식이 등장하고 있으며, 이는 확산의 'denoising'에 대한 현재의 초점을 넘어서게 될 수 있습니다.
Training a Diffusion Model
Hugging Face diffusers 라이브러리의 컴포넌트를 사용하여 시작할 것입니다.
1. 학습 데이터에서 이미지를 불러옵니다.
2. 다양한 양의 잡음을 추가합니다. 우리는 모델이 극도로 잡음이 많은 이미지와 거의 완벽한 이미지를 모두 ‘수정’(denoise)하는 방법을 잘 추정하기를 원합니다.
3. 잡음이 있는 입력 버전을 모델에 입력합니다.
4. 이러한 입력을 denoising하는 데 모델이 얼마나 잘 작동하는지 평가합니다.
5. 이 정보를 사용하여 모델의 가중치를 업데이트합니다.
The Data
이 예제에서는 Hugging Face Hub의 이미지 데이터셋을 사용할 것입니다. 구체적으로는 1000개의 나비 사진 컬렉션을 이용합니다. 나중에 프로젝트 섹션에서는 어떻게 자신의 데이터를 사용하는지 알게 될 것입니다.
이 데이터를 모델 학습에 사용하기 전에 몇 가지 준비 작업이 필요합니다. 이미지는 일반적으로 'pixels'의 grid로 표현되며, 세 가지 색상 채널(빨강, 초록, 파랑) 각각에 대해 0부터 255 사이의 색상 값으로 표현됩니다. 이들을 처리하고 학습을 위해 준비하기 위해 우리는 다음과 같은 작업을 수행합니다:
- 이미지를 고정된 크기로 조절합니다.
- (선택 사항) 데이터셋의 크기를 효과적으로 두 배로 늘리기 위해 이미지를 가로로 무작위로 뒤집는 방식의 증강을 추가합니다.
- PyTorch 텐서로 이미지를 변환합니다(이때 색상 값은 0과 1 사이의 실수로 표현됩니다).
- 이미지를 평균이 0이 되도록 정규화하며, 값은 -1과 1 사이가 되도록 합니다.
from datasets import load_dataset
dataset = load_dataset("huggan/smithsonian_butterflies_subset", split="train")
이 모든 것을 torchvision.transforms를 사용하여 할 수 있습니다.
import torchvision.transforms as transforms
image_size = 64
# Define data augmentations
preprocess = transforms.Compose(
[
transforms.Resize((image_size, image_size)), # Resize
transforms.RandomHorizontalFlip(), # Randomly flip (data augmentation)
transforms.ToTensor(), # Convert to tensor (0, 1)
transforms.Normalize([0.5], [0.5]) # Map to (-1, 1)
]
)
다음으로, 우리는 transform이 적용된 상태로 배치에 대한 데이터를 로드하기 위해 dataloader를 사용합니다.
batch_size = 64
def transform(examples):
images = [preprocess(image.convert("RGB")) for image in examples['image']]
return {"images": images}
dataset.set_transform(transform)
train_dataloader = torch.utils.data.DataLoader(
dataset, batch_size=batch_size, shuffle=True
)
위 코드는 데이터셋의 원본 이미지를 처리하고, 처리된 이미지를 batch로 로드하는 방법을 설정합니다.
import matplotlib.pyplot as plt
def show_images(images, n_rows=2, n_cols=4):
"""
Visualize a batch of images in a grid format.
Parameters:
- images: A batch of images, expected shape [batch_size, channels, height, width]
- n_rows: Number of rows for the grid
- n_cols: Number of columns for the grid
"""
# Ensure we don't try to display more images than we have in the batch
n = n_rows * n_cols
n = min(n, len(images))
# Create a grid of subplots with a smaller figsize
fig, axs = plt.subplots(n_rows, n_cols, figsize=(10, 5))
for i in range(n_rows):
for j in range(n_cols):
idx = i * n_cols + j
if idx < n:
img = images[idx].permute(1, 2, 0).numpy() # Convert to HxWxC format
axs[i][j].imshow(img)
axs[i][j].axis('off')
plt.tight_layout()
plt.show()
그리고 본 ebook에 나와있지는 않지만, show_images라는 function을 사용합니다.
코드는 위와 같습니다.
batch = next(iter(train_dataloader))
print('Shape:', batch['images'].shape,
'\nBounds:', batch['images'].min().item(), 'to', batch['images'].max().item())
show_images(batch['images'][:8] * 0.5 + 0.5) # NB : we map back to (0,1) for display
이 코드는 데이터 로딩 및 처리 파이프라인이 올바르게 작동하는지 확인하기 위한 간단한 방법을 제공합니다.
첫 번째 배치의 이미지를 시각적으로 확인함으로써, 데이터 전처리 단계에서 발생할 수 있는 문제를 빠르게 감지할 수 있습니다.
Adding Noise
자, 그렇다면 우리가 데이터를 어떻게 손상시킬 수 있을까요? 그것도 "gradually" 손상시켜야 합니다.
가장 흔한 것은 image에 noise를 추가하는 것이 있습니다.
우리가 추가하는 noise는 noise schedule에 의해 제어 되고, 본 ebook에서는 Ho et al. 의 "Denoising Diffusion Probabilistic Models" paper를 기반으로 한 일반적인 approach를 사용합니다.
https://arxiv.org/abs/2006.11239
Denoising Diffusion Probabilistic Models
We present high quality image synthesis results using diffusion probabilistic models, a class of latent variable models inspired by considerations from nonequilibrium thermodynamics. Our best results are obtained by training on a weighted variational bound
arxiv.org
diffusers 라이브러리에서 noise를 추가하는 것이 'scheduler'라는 것에 의해 처리되며, 이는 bach와 'timestep'의 목록을 입력 받아 해당 image의 noise가 있는 버전을 어떻게 생성할지 결정합니다.
from diffusers import DDPMScheduler
scheduler = DDPMScheduler(num_train_timesteps=1000, beta_start = 0.001, beta_end = 0.02)
timesteps = torch.linspace(0, 999, 8).long()
x = batch['images'][:8]
noise = torch.rand_like(x)
noised_x = scheduler.add_noise(x, noise, timesteps)
show_images((noised_x * 0.5 + 0.5).clip(0, 1))
코드는 노이즈가 추가된 이미지를 생성하고, 그 이미지를 시각적으로 표시하는 프로세스를 설명합니다.
The UNet
UNet은 입력의 원하는 출력이 입력과 동일한 공간적 범위를 갖도록 만들어진 과제들, 예를 들면 image segmentation과 같은 작업을 위해 발명된 CNN입니다. UNet는 입력의 공간적 크기를 줄이는 일련의 'downsampling' 레이어와 입력의 공간적 범위를 다시 증가시키는 일련의 'upsampling' 레이어로 구성됩니다. downsampling 레이어는 일반적으로 upsampling 레이어의 입력에 downsampling 레이어의 출력을 연결하는 'skip connection'을 따릅니다.
이를 통해 upsampling 레이어는 네트워크의 초기 단계에서 높은 해상도의 representation을 '보게' 되어, 이러한 고해상도 정보가 특히 유용한 이미지와 같은 출력 작업에 유용합니다.
https://arxiv.org/abs/1505.04597
U-Net: Convolutional Networks for Biomedical Image Segmentation
There is large consent that successful training of deep networks requires many thousand annotated training samples. In this paper, we present a network and training strategy that relies on the strong use of data augmentation to use the available annotated
arxiv.org
diffusers 라이브러리에서 사용되는 UNet 아키텍처는 Ronneberger 등이 2015년에 제안한 원래의 UNet보다 더 발전된 것으로, 주의 및 잔여 블록과 같은 추가 사항이 있습니다. 여기서 핵심 특징은 입력(노이즈 이미지)을 받아들여 동일한 형태(예측 노이즈)의 예측을 생성할 수 있다는 것입니다. 확산 모델의 경우 UNet은 일반적으로 추가 조건으로 타임스텝도 포함하게 됩니다.
다음은 UNet을 생성하고 노이즈 이미지의 배치를 통과시키는 방법입니다:
from diffusers.models.unet_2d import UNet2DModel
# Create a UNet2DModel
model = UNet2DModel(
in_channels = 3, # 3 channels for RGB images
sample_size = 64, # Specify our input size,
block_out_channels=(64, 128, 256, 512), #N channels per layer
down_block_types = ("DownBlock2D", "DownBlock2D",
"AttnDownBlock2D", "AttnDownBlock2D"),
up_block_types = ("AttnUpBlock2D", "AttnUpBlock2D",
"UpBlock2D", "UpBlock2D"),
)
# Pass a batch of data through
with torch.no_grad():
out = model(noised_x, timestep=timesteps).sample
out.shape
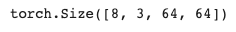
이 코드는 diffusers 라이브러리의 UNet2DModel 클래스를 사용하여 2D U-Net 모델을 생성하고, 노이즈가 추가된 이미지 데이터를 해당 모델을 통해 전달하는 과정을 설명합니다.
모델을 통과한 후의 출력 데이터의 형태를 확인합니다. 이 경우 출력은 [8, 3, 64, 64]의 형태를 가지며, 이는 배치 크기가 8이고 각 이미지가 3 채널(RGB)로 64x64 크기를 갖는다는 것을 의미합니다.
요약하면, 이 코드는 2D U-Net 아키텍처를 생성하고 노이즈가 추가된 이미지를 해당 모델을 통해 전달하는 과정을 보여줍니다.
Training
이제 모델과 데이터가 준비되었으므로 훈련을 시작할 수 있습니다.
우리는 3e-4의 Learning Rate로 AdamW Optimizer를 사용합니다.
각 훈련 단계에서 다음을 수행합니다:
- image batch를 불러옵니다.
- image에 noise를 추가합니다. noise의 양을 결정하기 위해 random timestep를 선택합니다.
- noise가 있는 image를 model에 입력합니다.
- loss을 계산합니다. 이는 model의 예측과 target 간의 MSE입니다. 이 경우 target은 image에 추가한 noise입니다. 이것을 noise또는 'epsilon' 목표라고 합니다.
- loss를 Backpropagation하고 optimizer로 model weight를 update합니다.
위의 모든 것이 코드에서 어떻게 보이는지 다음과 같습니다:
'Artificial Intelligence > Computer Vision' 카테고리의 다른 글
| [Diffusion Models] 확산 모델 이해하기 (2) - Euler's Method (0) | 2025.01.23 |
|---|---|
| [Diffusion Models] 확산 모델 이해하기 (1) - ODE, SDE and Markov process, Wiener process (0) | 2025.01.22 |
| [Computer Vision] Color Image Processing (1) | 2023.06.06 |
| [Computer Vision] Image Warping - Transformation (0) | 2023.05.31 |
| [Computer Vision] Image Warping - Transformation (0) | 2023.05.30 |








